Spec-Zone .ru
спецификации, руководства, описания, API
|
|
Spec-Zone .ru
спецификации, руководства, описания, API
|
java.lang.CharacterCharacter представьте примитивные значения типа char. public final classМногие из методов классаCharacter{ public static final charMIN_VALUE= '\u0000'; public static final charMAX_VALUE= '\uffff'; public static final intMIN_RADIX= 2; public static final intMAX_RADIX= 36; publicCharacter(char value); public StringtoString(); public booleanequals(Object obj); public inthashCode(); public charcharValue(); public static booleanisDefined(char ch); public static booleanisLowerCase(char ch); public static booleanisUpperCase(char ch); public static booleanisTitleCase(char ch); public static booleanisDigit(char ch); public static booleanisLetter(char ch); public static booleanisLetterOrDigit(char ch); public static booleanisJavaLetter(char ch); public static booleanisJavaLetterOrDigit(char ch);) public static booleanisSpace(char ch); public static chartoLowerCase(char ch); public static chartoUpperCase(char ch); public static chartoTitleCase(char ch); public static intdigit(char ch, int radix); public static charforDigit(int digit, int radix); }
Character определяются с точки зрения "таблицы атрибутов Unicode", которая определяет имя для каждого определенного символа Unicode так же как других возможных атрибутов, таких как десятичное значение, прописной эквивалент, строчный эквивалент, и/или titlecase эквивалент. До Java 1.1, эти методы были внутренними к компилятору Java и основанными на Unicode 1.1.5, как описано здесь. Новые версии этих методов должны использоваться в компиляторах Java, которые должны работать на системах Java, которые еще не включают эти методы.Unicode 1.1.5 таблицы атрибутов доступен во всемирной паутине как:
ftp://unicode.org/pub/MappingTables/UnicodeData-1.1.5.txtОднако, этот файл содержит несколько ошибок. Термин "Unicode таблицы атрибутов" в следующих разделах относится к содержанию этого файла после того, как следующие исправления были применены:
03D0; ГРЕЧЕСКИЙ БЕТА СИМВОЛ; Ll; 0; L;;;;; N; ГРЕЧЕСКАЯ СТРОЧНАЯ БУКВА ЗАВИХРИЛАСЬ БЕТА;; 0392;; 0392
03D1; ГРЕЧЕСКИЙ СИМВОЛ ТЕТЫ; Ll; 0; L;;;;; N; ГРЕЧЕСКАЯ ТЕТА СЦЕНАРИЯ СТРОЧНОЙ БУКВЫ;; 0398;; 0398
03D5; ГРЕЧЕСКИЙ СИМВОЛ PHI; Ll; 0; L;;;;; N; ГРЕЧЕСКИЙ СЦЕНАРИЙ СТРОЧНОЙ БУКВЫ PHI;; 03A6;; 03A6
03D6; ГРЕЧЕСКИЙ СИМВОЛ PI; Ll; 0; L;;;;; N; ГРЕЧЕСКИЙ PI ОМЕГИ СТРОЧНОЙ БУКВЫ;; 03A0;; 03A0
03F0; ГРЕЧЕСКИЙ СИМВОЛ КАППЫ; Ll; 0; L;;;;; N; ГРЕЧЕСКАЯ КАППА СЦЕНАРИЯ СТРОЧНОЙ БУКВЫ;; 039A;; 039A
03F1; ГРЕЧЕСКИЙ СИМВОЛ КОЭФФИЦИЕНТА КОРРЕЛЯЦИИ ДЛЯ СОВОКУПНОСТИ; Ll; 0; L;;;;; N; ГРЕЧЕСКАЯ СТРОЧНАЯ БУКВА ВЫСЛЕЖЕННЫЙ КОЭФФИЦИЕНТ КОРРЕЛЯЦИИ ДЛЯ СОВОКУПНОСТИ;; 03A1;; 03A1
FF10; ПОЛНОШИРИННЫЙ НУЛЬ ЦИФРЫ; Без обозначения даты; 0; EN; 0030; 0; 0; 0; N;;;;;
FF11; ПОЛНОШИРИННАЯ ЦИФРА ОДИН; Без обозначения даты; 0; EN; 0031; 1; 1; 1; N;;;;;
FF12; ПОЛНОШИРИННАЯ ЦИФРА ДВА; Без обозначения даты; 0; EN; 0032; 2; 2; 2; N;;;;;
FF13; ПОЛНОШИРИННАЯ ЦИФРА ТРИ; Без обозначения даты; 0; EN; 0033; 3; 3; 3; N;;;;;
FF14; ПОЛНОШИРИННАЯ ЦИФРА ЧЕТЫРЕ; Без обозначения даты; 0; EN; 0034; 4; 4; 4; N;;;;;
FF15; ПОЛНОШИРИННАЯ ЦИФРА ПЯТЬ; Без обозначения даты; 0; EN; 0035; 5; 5; 5; N;;;;;
FF16; ПОЛНОШИРИННАЯ ЦИФРА ШЕСТЬ; Без обозначения даты; 0; EN; 0036; 6; 6; 6; N;;;;;
FF17; ПОЛНОШИРИННАЯ ЦИФРА СЕМЬ; Без обозначения даты; 0; EN; 0037; 7; 7; 7; N;;;;;
FF18; ПОЛНОШИРИННАЯ ЦИФРА ВОСЕМЬ; Без обозначения даты; 0; EN; 0038; 8; 8; 8; N;;;;;
FF19; ПОЛНОШИРИННАЯ ЦИФРА ДЕВЯТЬ; Без обозначения даты; 0; EN; 0039; 9; 9; 9; N;;;;;
03DA; КЛЕЙМО ГРЕЧЕСКОЙ БУКВЫ; Лютеций; 0; L;;;;; N; ГРЕЧЕСКОЕ КЛЕЙМО ПРОПИСНОЙ БУКВЫ;;;;
03DC; ГРЕЧЕСКАЯ БУКВА DIGAMMA; Лютеций; 0; L;;;;; N; ГРЕЧЕСКАЯ ПРОПИСНАЯ БУКВА DIGAMMA;;;;
03DE; ГРЕЧЕСКАЯ БУКВА KOPPA; Лютеций; 0; L;;;;; N; ГРЕЧЕСКАЯ ПРОПИСНАЯ БУКВА KOPPA;;;;
03E0; ГРЕЧЕСКАЯ БУКВА SAMPI; Лютеций; 0; L;;;;; N; ГРЕЧЕСКАЯ ПРОПИСНАЯ БУКВА SAMPI;;;;
03C2; ГРЕЧЕСКАЯ СИГМА ФИНАЛА СТРОЧНОЙ БУКВЫ; Ll; 0; L;;;;; N;;; 03A3;; 03A3
Java 1.1 будет включать методы, определенные здесь, или основанный на Unicode 1.1.5 или, мы надеемся, обновленные версии методов, которые используют более новый Unicode 2.0. Таблица символьного атрибута для Unicode 2.0 в настоящий момент доступна во всемирной паутине как файл:
ftp://unicode.org/pub/MappingTables/UnicodeData-2.0.12.txtЕсли Вы реализуете компилятор Java или систему, пожалуйста, обратитесь к странице:
http://java.sun.com/Seriesкоторый будет обновлен с информацией о зависимых от Unicode методах.
Самое большое изменение в Unicode 2.0 является полной перестановкой корейских символов Хангула. Также есть многочисленные меньшие улучшения.
Это - наше намерение, что Java отследит Unicode, поскольку это развивается в течение долгого времени. Учитывая, что полная поддержка Unicode только появляется на рынке, и это изменяется в Unicode, находятся в областях, которые широко еще не используются, это должно вызвать минимальные проблемы и цель дальнейшего Java глобальной поддержки языка.
20.5.1 public static final char
MIN_VALUE = '\u0000';
Постоянная величина этого поля является самым маленьким значением типа char.
[Это поле планируется для введения в версии 1.1 Java.]
20.5.2 public static final char
MAX_VALUE = '\uffff';
Постоянная величина этого поля является самым маленьким значением типа char.
[Это поле планируется для введения в версии 1.1 Java.]
20.5.3 public static final int
MIN_RADIX = 2;
Постоянная величина этого поля является самым маленьким значением, разрешенным для параметра основания в методах преобразования основания такой как digit метод (§20.5.23), forDigit метод (§20.5.24), и toString метод класса Integer
(§20.7).
20.5.4 public static final int
MAX_RADIX = 36;
Постоянная величина этого поля является самым большим значением, разрешенным для параметра основания в методах преобразования основания такой как digit метод (§20.5.23), forDigit метод (§20.5.24), и toString метод класса Integer (§20.7).
20.5.5 public
Character(char value)
Этот конструктор инициализирует недавно создаваемый Character возразите так, чтобы это представило примитивное значение, которое является параметром.
20.5.6 public String
toString()
Результатом является a String чья длина 1 и чей единственный компонент является примитивом char значение представляется этим Character объект.
Переопределения toString метод Object (§20.1.2).
20.5.7 public boolean
equals(Object obj)
Результат true если и только если параметр не null и a Character объект, который представляет то же самое char оцените как это Character объект.
Переопределения equals метод Object (§20.1.3).
20.5.8 public int
hashCode()
Результатом является примитив char значение представляется этим Character объект, бросок, чтобы ввести int.
Переопределения hashCode метод Object (§20.1.4).
20.5.9 public char
charValue()
Примитив char значение представляется этим Character объект возвращается.
20.5.10 public static boolean
isDefined(char ch)
Результат true если и только если символьным параметром является определенный символ Unicode.
Символ является определенным символом Unicode, если и только если по крайней мере одно из следующего является истиной:
\u3040 и не больше чем \u9FA5.
\uF900 и не больше чем \uFA2D. 0000-01F5, 01FA-0217, 0250-02A8, 02B0-02DE, 02E0-02E9, 0300-0345, 0360-0361, 0374-0375, 037A, 037E, 0384-038A, 038C, 038E-03A1, 03A3-03CE, 03D0-03D6, 03DA, 03DC, 03DE, 03E0, 03E2-03F3, 0401-040C, 040E-044F, 0451-045C, 045E-0486, 0490-04C4, 04C7-04C8, 04CB-04CC, 04D0-04EB, 04EE-04F5, 04F8-04F9, 0531-0556, 0559-055F, 0561-0587, 0589, 05B0-05B9, 05BB-05C3, 05D0-05EA, 05F0-05F4, 060C, 061B, 061F, 0621-063A, 0640-0652, 0660-066D, 0670-06B7, 06BA-06BE, 06C0-06CE, 06D0-06ED, 06F0-06F9, 0901-0903, 0905-0939, 093C-094D, 0950-0954, 0958-0970, 0981-0983, 0985-098C, 098F-0990, 0993-09A8, 09AA-09B0, 09B2, 09B6-09B9, 09BC, 09BE-09C4, 09C7-09C8, 09CB-09CD, 09D7, 09DC-09DD, 09DF-09E3, 09E6-09FA, 0A02, 0A05-0A0A, 0A0F-0A10, 0A13-0A28, 0A2A-0A30, 0A32-0A33, 0A35-0A36, 0A38-0A39, 0A3C, 0A3E-0A42, 0A47-0A48, 0A4B-0A4D, 0A59-0A5C, 0A5E, 0A66-0A74, 0A81-0A83, 0A85-0A8B, 0A8D, 0A8F-0A91, 0A93-0AA8, 0AAA-0AB0, 0AB2-0AB3, 0AB5-0AB9, 0ABC-0AC5, 0AC7-0AC9, 0ACB-0ACD, 0AD0, 0AE0, 0AE6-0AEF, 0B01-0B03, 0B05-0B0C, 0B0F-0B10, 0B13-0B28, 0B2A-0B30, 0B32-0B33, 0B36-0B39, 0B3C-0B43, 0B47-0B48, 0B4B-0B4D, 0B56-0B57, 0B5C-0B5D, 0B5F-0B61, 0B66-0B70, 0B82-0B83, 0B85-0B8A, 0B8E-0B90, 0B92-0B95, 0B99-0B9A, 0B9C, 0B9E-0B9F, 0BA3-0BA4, 0BA8-0BAA, 0BAE-0BB5, 0BB7-0BB9, 0BBE-0BC2, 0BC6-0BC8, 0BCA-0BCD, 0BD7, 0BE7-0BF2, 0C01-0C03, 0C05-0C0C, 0C0E-0C10, 0C12-0C28, 0C2A-0C33, 0C35-0C39, 0C3E-0C44, 0C46-0C48, 0C4A-0C4D, 0C55-0C56, 0C60-0C61, 0C66-0C6F, 0C82-0C83, 0C85-0C8C, 0C8E-0C90, 0C92-0CA8, 0CAA-0CB3, 0CB5-0CB9, 0CBE-0CC4, 0CC6-0CC8, 0CCA-0CCD, 0CD5-0CD6, 0CDE, 0CE0-0CE1, 0CE6-0CEF, 0D02-0D03, 0D05-0D0C, 0D0E-0D10, 0D12-0D28, 0D2A-0D39, 0D3E-0D43, 0D46-0D48, 0D4A-0D4D, 0D57, 0D60-0D61, 0D66-0D6F, 0E01-0E3A, 0E3F-0E5B, 0E81-0E82, 0E84, 0E87-0E88, 0E8A, 0E8D, 0E94-0E97, 0E99-0E9F, 0EA1-0EA3, 0EA5, 0EA7, 0EAA-0EAB, 0EAD-0EB9, 0EBB-0EBD, 0EC0-0EC4, 0EC6, 0EC8-0ECD, 0ED0-0ED9, 0EDC-0EDD, 10A0-10C5, 10D0-10F6, 10FB, 1100-1159, 115F-11A2, 11A8-11F9, 1E00-1E9A, 1EA0-1EF9, 1F00-1F15, 1F18-1F1D, 1F20-1F45, 1F48-1F4D, 1F50-1F57, 1F59, 1F5B, 1F5D, 1F5F-1F7D, 1F80-1FB4, 1FB6-1FC4, 1FC6-1FD3, 1FD6-1FDB, 1FDD-1FEF, 1FF2-1FF4, 1FF6-1FFE, 2000-202E, 2030-2046, 206A-2070, 2074-208E, 20A0-20AA, 20D0-20E1, 2100-2138, 2153-2182, 2190-21EA, 2200-22F1, 2300, 2302-237A, 2400-2424, 2440-244A, 2460-24EA, 2500-2595, 25A0-25EF, 2600-2613, 261A-266F, 2701-2704, 2706-2709, 270C-2727, 2729-274B, 274D, 274F-2752, 2756, 2758-275E, 2761-2767, 2776-2794, 2798-27AF, 27B1-27BE, 3000-3037, 303F, 3041-3094, 3099-309E, 30A1-30FE, 3105-312C, 3131-318E, 3190-319F, 3200-321C, 3220-3243, 3260-327B, 327F-32B0, 32C0-32CB, 32D0-32FE, 3300-3376, 337B-33DD, 33E0-33FE, 3400-9FA5, F900-FA2D, FB00-FB06, FB13-FB17, FB1E-FB36, FB38-FB3C, FB3E, FB40-FB41, FB43-FB44, FB46-FBB1, FBD3-FD3F, FD50-FD8F, FD92-FDC7, FDF0-FDFB, FE20-FE23, FE30-FE44, FE49-FE52, FE54-FE66, FE68-FE6B, FE70-FE72, FE74, FE76-FEFC, FEFF, FF01-FF5E, FF61-FFBE, FFC2-FFC7, FFCA-FFCF, FFD2-FFD7, FFDA-FFDC, FFE0-FFE6, FFE8-FFEE, FFFD.[Этот метод планируется для введения в версии 1.1 Java, или как определено здесь, или обновляется для Unicode 2.0; см. §20.5.]
20.5.11 public static boolean
isLowerCase(char ch)
Результат true если и только если символьным параметром является символ нижнего регистра.
Символ, как полагают, является нижним регистром, если и только если все следующее является истиной:
ch не находится в диапазоне \u2000 через \u2FFF.
0061-007A, 00DF-00F6, 00F8-00FF, 0101-0137 (разногласия только), 0138-0148 (выравнивает только), 0149-0177 (разногласия только), 017A-017E (выравнивает только), 017F-0180, 0183, 0185, 0188, 018C-018D, 0192, 0195, 0199-019B, 019E, 01A1-01A5 (разногласия только), 01A8, 01AB, 01AD, 01B0, 01B4, 01B6, 01B9-01BA, 01BD, 01C6, 01C9, 01CC-01DC (выравнивает только), 01DD-01EF (разногласия только), 01F0, 01F3, 01F5, 01FB-0217 (разногласия только), 0250-0261, 0263-0269, 026B-0273, 0275, 0277-027F, 0282-028E, 0290-0293, 029A, 029D-029E, 02A0, 02A3-02A8, 0390, 03AC-03CE, 03D0-03D1, 03D5-03D6, 03E3-03EF (разногласия только), 03F0-03F1, 0430-044F, 0451-045C, 045E-045F, 0461-0481 (разногласия только), 0491-04BF (разногласия только), 04C2, 04C4, 04C8, 04CC, 04D1-04EB (разногласия только), 04EF-04F5 (разногласия только), 04F9, 0561-0587, 1E01-1E95 (разногласия только), 1E96-1E9A, 1EA1-1EF9 (разногласия только), 1F00-1F07, 1F10-1F15, 1F20-1F27, 1F30-1F37, 1F40-1F45, 1F50-1F57, 1F60-1F67, 1F70-1F7D, 1F80-1F87, 1F90-1F97, 1FA0-1FA7, 1FB0-1FB4, 1FB6-1FB7, 1FC2-1FC4, 1FC6-1FC7, 1FD0-1FD3, 1FD6-1FD7, 1FE0-1FE7, 1FF2-1FF4, 1FF6-1FF7, FB00-FB06, FB13-FB17, FF41-FF5A.Из первых 128 символов Unicode, точно 26, как полагают, нижний регистр:
abcdefghijklmnopqrstuvwxyz[Эта спецификация для метода
isLowerCase планируется для введения в версии 1.1 Java, или как определено здесь, или обновляется для Unicode 2.0; см. §20.5. В предыдущих версиях Java, этот метод возвраты false для всех параметров, больше чем \u00FF.]20.5.12 public static boolean
isUpperCase(char ch)
Результат true если и только если символьным параметром является символ верхнего регистра.
Символ, как полагают, является прописным, если и только если все следующее является истиной:
ch не находится в диапазоне \u2000 через \u2FFF.
0041-005A, 00C0-00D6, 00D8-00DE, 0100-0136 (выравнивает только), 0139-0147 (разногласия только), 014A-0178 (выравнивает только), 0179-017D (разногласия только), 0181-0182, 0184, 0186, 0187, 0189-018B, 018E-0191, 0193-0194, 0196-0198, 019C-019D, 019F-01A0, 01A2, 01A4, 01A7, 01A9, 01AC, 01AE, 01AF, 01B1-01B3, 01B5, 01B7, 01B8, 01BC, 01C4, 01C7, 01CA, 01CD-01DB (разногласия только), 01DE-01EE (выравнивает только), 01F1, 01F4, 01FA-0216 (выравнивает только), 0386, 0388-038A, 038C, 038E, 038F, 0391-03A1, 03A3-03AB, 03E2-03EE (выравнивает только), 0401-040C, 040E-042F, 0460-0480 (выравнивает только), 0490-04BE (выравнивает только), 04C1, 04C3, 04C7, 04CB, 04D0-04EA (выравнивает только), 04EE-04F4 (выравнивает только), 04F8, 0531-0556, 10A0-10C5, 1E00-1E94 (выравнивает только), 1EA0-1EF8 (выравнивает только), 1F08-1F0F, 1F18-1F1D, 1F28-1F2F, 1F38-1F3F, 1F48-1F4D, 1F59-1F5F (разногласия только), 1F68-1F6F, 1F88-1F8F, 1F98-1F9F, 1FA8-1FAF, 1FB8-1FBC, 1FC8-1FCC, 1FD8-1FDB, 1FE8-1FEC, 1FF8-1FFC, FF21-FF3A.Из первых 128 символов Unicode, точно 26, как полагают, являются прописными:
ABCDEFGHIJKLMNOPQRSTUVWXYZ[Эта спецификация для метода
isUpperCase планируется для введения в версии 1.1 Java, или как определено здесь, или обновляется для Unicode 2.0; см. §20.5. В предыдущих версиях Java, этот метод возвраты false для всех параметров, больше чем \u00FF.]20.5.13 public static boolean
isTitleCase(char ch)
Результат true если и только если символьным параметром является titlecase символ.
Понятие "titlecase" было введено в Unicode, чтобы обработать специфическую ситуацию: есть единственные символы Unicode, появление которых в каждом случае точно походит на две обычных латинских буквы. Например, есть единственный символ Unicode `LJ' (\u01C7) это смотрит точно так же как символы `L' и соединенный `Дж'. Есть соответствующая строчная буква `lj' (\u01C9) также. Эти символы присутствуют в Unicode прежде всего, чтобы позволить непосредственные преобразования из Кириллицы, как использующийся в Сербии, например, к латинскому алфавиту. Теперь предположите слово "LJUBINJE" (у которого есть шесть символов, не восемь, потому что два из них являются единственными символами Unicode `LJ' и `NJ', возможно произведенный непосредственным преобразованием из Кириллицы) должен быть записан как часть книжного заголовка, в прописных буквах и нижнем регистре. Стратегия создания первого верхнего регистра буквы и остальных нижний регистр приводит к "LJubinje" - самый неудачный. Решение состоит в том, что должна быть третья форма, названная формой titlecase. Форма titlecase `LJ' является `Lj' (\u01C8) и форма titlecase `NJ' является `Nj'. Слово для книжного заголовка тогда лучше всего представляется, преобразовывая первую букву в titlecase если возможный, иначе в верхний регистр; остающиеся буквы тогда преобразовываются в нижний регистр.
Символ, как полагают, является titlecase, если и только если оба из следующего являются истиной:
ch не находится в диапазоне \u2000 через \u2FFF.
isTitleCase возвраты true: \u01C5 LATIN CAPITAL LETTER D WITH SMALL LETTER Z WITH CARON \u01C8 LATIN CAPITAL LETTER L WITH SMALL LETTER J \u01CB LATIN CAPITAL LETTER N WITH SMALL LETTER J \u01F2 LATIN CAPITAL LETTER D WITH SMALL LETTER Z[Этот метод планируется для введения в версии 1.1 Java, или как определено здесь, или обновляется для Unicode 2.0; см. §20.5.]
20.5.14 public static boolean
isDigit(char ch)
Результат true если и только если символьным параметром является цифра.
Символ, как полагают, является цифрой, если и только если оба из следующего являются истиной:
ch не находится в диапазоне \u2000 через \u2FFF.
DIGIT.
Из первых 128 символов Unicode, точно 10, как полагают, цифры:0030-0039ISO-Latin-1 (and ASCII) digits ('0'-'9')0660-0669Arabic-Indic digits06F0-06F9Eastern Arabic-Indic digits0966-096FDevanagari digits09E6-09EFBengali digits0A66-0A6FGurmukhi digits0AE6-0AEFGujarati digits0B66-0B6FOriya digits0BE7-0BEFTamil digits (there are only nine of these-no zero digit)0C66-0C6FTelugu digits0CE6-0CEFKannada digits0D66-0D6FMalayalam digits0E50-0E59Thai digits0ED0-0ED9Lao digitsFF10-FF19Fullwidth digits
0123456789[Эта спецификация для метода
isDigit планируется для введения в версии 1.1 Java, или как определено здесь, или обновляется для Unicode 2.0; см. §20.5. В предыдущих версиях Java, этот метод возвраты false для всех параметров, больше чем \u00FF.]20.5.15 public static boolean
isLetter(char ch)
Результат true если и только если символьным параметром является буква.
Символ, как полагают, является буквой, если и только если это - буква или цифра (§20.5.16), но не является цифрой (§20.5.14).
[Этот метод планируется для введения в версии 1.1 Java, или как определено здесь, или обновляется для Unicode 2.0; см. §20.5.]
20.5.16 public static boolean
isLetterOrDigit(char ch)
Результат true если и только если символьным параметром является "буква или цифра".
Символ, как полагают, является "буквой или цифрой", если и только если это - определенный символ Unicode (§20.5.10), и его код находится в одном из следующих диапазонов:
Это следует, тогда, это для Unicode 1.1.5 как исправлено выше, буквы Unicode и цифры является точно теми с кодами в следующем списке, который содержит и единственные коды и содержащие диапазоны:0030-0039ISO-Latin-1 (and ASCII) digits ('0'-'9')0041-005AISO-Latin-1 (and ASCII) uppercase Latin letters ('A'-'Z')0061-007AISO-Latin-1 (and ASCII) lowercase Latin letters ('a'-'z')00C0-00D6ISO-Latin-1 supplementary letters00D8-00F6ISO-Latin-1 supplementary letters00F8-00FFISO-Latin-1 supplementary letters0100-1FFFLatin extended-A, Latin extended-B, IPA extensions, spacing modifier letters, combining diacritical marks, basic Greek, Greek symbols and Coptic, Cyrillic, Armenian, Hebrew extended-A, Basic Hebrew, Hebrew extended-B, Basic Arabic, Arabic extended, Devanagari, Bengali, Gurmukhi, Gujarati, Oriya, Tamil, Telugu, Kannada, Malayalam, Thai, Lao, Basic Georgian, Georgian extended, Hanguljamo, Latin extended additional, Greek extended3040-9FFFHiragana, Katakana, Bopomofo, Hangul compatibility Jamo, CJK miscellaneous, enclosed CJK characters and months, CJK compatibility, Hangul, Hangul supplementary-A, Hangul supplementary-B, CJK unified ideographsF900-FDFFCJK compatibility ideographs, alphabetic presentation forms, Arabic presentation forms-AFE70-FEFEArabic presentation forms-BFF10-FF19Fullwidth digitsFF21-FF3AFullwidth Latin uppercaseFF41-FF5AFullwidth Latin lowercaseFF66-FFDCHalfwidth Katakana and Hangul
0030-0039, 0041-005A, 0061-007A, 00C0-00D6, 00D8-00F6, 00F8-01F5, 01FA-0217, 0250-02A8, 02B0-02DE, 02E0-02E9, 0300-0345, 0360-0361, 0374-0375, 037A, 037E, 0384-038A, 038C, 038E, 038F-03A1, 03A3-03CE, 03D0-03D6, 03DA-03E2, 03DA, 03DC, 03DE, 03E0, 03E2-03F3, 0401-040C, 040E-044F, 0451-045C, 045E-0486, 0490-04C4, 04C7-04C8, 04CB-04CC, 04D0-04EB, 04EE-04F5, 04F8-04F9, 0531-0556, 0559-055F, 0561-0587, 0589, 05B0-05B9, 05BB-05C3, 05D0-05EA, 05F0-05F4, 060C, 061B, 061F, 0621, 0622-063A, 0640-0652, 0660-066D, 0670-06B7, 06BA-06BE, 06C0-06CE, 06D0-06ED, 06F0-06F9, 0901-0903, 0905-0939, 093C-094D, 0950-0954, 0958-0970, 0981-0983, 0985-098C, 098F-0990, 0993-09A8, 09AA-09B0, 09B2, 09B6-09B9, 09BC, 09BE, 09BF-09C4, 09C7-09C8, 09CB-09CD, 09D7, 09DC-09DD, 09DF-09E3, 09E6-09FA, 0A02, 0A05-0A0A, 0A0F-0A10, 0A13-0A28, 0A2A-0A30, 0A32-0A33, 0A35-0A36, 0A38-0A39, 0A3C, 0A3E, 0A3F-0A42, 0A47-0A48, 0A4B-0A4D, 0A59-0A5C, 0A5E, 0A66-0A74, 0A81-0A83, 0A85-0A8B, 0A8D, 0A8F, 0A90-0A91, 0A93-0AA8, 0AAA-0AB0, 0AB2-0AB3, 0AB5-0AB9, 0ABC-0AC5, 0AC7-0AC9, 0ACB-0ACD, 0AD0, 0AE0, 0AE6-0AEF, 0B01-0B03, 0B05-0B0C, 0B0F-0B10, 0B13-0B28, 0B2A-0B30, 0B32-0B33, 0B36-0B39, 0B3C-0B43, 0B47-0B48, 0B4B-0B4D, 0B56-0B57, 0B5C-0B5D, 0B5F-0B61, 0B66-0B70, 0B82-0B83, 0B85-0B8A, 0B8E-0B90, 0B92-0B95, 0B99-0B9A, 0B9C, 0B9E, 0B9F, 0BA3-0BA4, 0BA8-0BAA, 0BAE-0BB5, 0BB7-0BB9, 0BBE-0BC2, 0BC6-0BC8, 0BCA-0BCD, 0BD7, 0BE7-0BF2, 0C01-0C03, 0C05-0C0C, 0C0E-0C10, 0C12-0C28, 0C2A-0C33, 0C35-0C39, 0C3E-0C44, 0C46-0C48, 0C4A-0C4D, 0C55-0C56, 0C60-0C61, 0C66-0C6F, 0C82-0C83, 0C85-0C8C, 0C8E-0C90, 0C92-0CA8, 0CAA-0CB3, 0CB5-0CB9, 0CBE-0CC4, 0CC6-0CC8, 0CCA-0CCD, 0CD5-0CD6, 0CDE, 0CE0, 0CE1, 0CE6-0CEF, 0D02-0D03, 0D05-0D0C, 0D0E-0D10, 0D12-0D28, 0D2A-0D39, 0D3E-0D43, 0D46-0D48, 0D4A-0D4D, 0D57, 0D60-0D61, 0D66-0D6F, 0E01-0E3A, 0E3F-0E5B, 0E81-0E82, 0E84, 0E87-0E88, 0E8A, 0E8D, 0E94-0E97, 0E99-0E9F, 0EA1-0EA3, 0EA5, 0EA7, 0EAA-0EAB, 0EAD-0EB9, 0EBB-0EBD, 0EC0-0EC4, 0EC6, 0EC8, 0EC9-0ECD, 0ED0-0ED9, 0EDC-0EDD, 10A0-10C5, 10D0-10F6, 10FB, 1100-1159, 115F-11A2, 11A8-11F9, 1E00-1E9A, 1EA0-1EF9, 1F00-1F15, 1F18-1F1D, 1F20-1F45, 1F48-1F4D, 1F50-1F57, 1F59, 1F5B, 1F5D, 1F5F-1F7D, 1F80-1FB4, 1FB6-1FC4, 1FC6-1FD3, 1FD6-1FDB, 1FDD-1FEF, 1FF2-1FF4, 1FF6-1FFE, 3041-3094, 3099-309E, 30A1-30FE, 3105-312C, 3131-318E, 3190-319F, 3200-321C, 3220-3243, 3260-327B, 327F-32B0, 32C0-32CB, 32D0-32FE, 3300-3376, 337B-33DD, 33E0-33FE, 3400-9FA5, F900-FA2D, FB00-FB06, FB13-FB17, FB1E-FB36, FB38-FB3C, FB3E, FB40, FB41, FB43, FB44, FB46, FB47-FBB1, FBD3-FD3F, FD50-FD8F, FD92-FDC7, FDF0-FDFB, FE70-FE72, FE74, FE76, FE77-FEFC, FF10-FF19, FF21-FF3A, FF41-FF5A, FF66-FFBE, FFC2-FFC7, FFCA-FFCF, FFD2-FFD7, FFDA-FFDC.[Этот метод планируется для введения в версии 1.1 Java, или как определено здесь, или обновляется для Unicode 2.0; см. §20.5.]
20.5.17 public static boolean
isJavaLetter(char ch)
Результатом является истина, если и только если символьным параметром является символ, который может начать идентификатор Java.
Символ, как полагают, является буквой Java, если и только если это - буква (§20.5.15) или является символом знака доллара '$' (\u0024) или подчеркивание ("низкая строка") символ '_' (\u005F).
[Этот метод планируется для введения в версии 1.1 Java, или как определено здесь, или обновляется для Unicode 2.0; см. §20.5.]
20.5.18 public static boolean
isJavaLetterOrDigit(char ch)
Результатом является истина, если и только если символьным параметром является символ, который может произойти в идентификаторе Java после первого символа.
Символ, как полагают, является Java "буква или цифра", если и только если это - "буква или цифра" (§20.5.16) или является символом знака доллара '$' (\u0024) или подчеркивание ("низкая строка") символ '_' (\u005F).
[Этот метод планируется для введения в версии 1.1 Java, или как определено здесь, или обновляется для Unicode 2.0; см. §20.5.]
20.5.19 public static boolean
isSpace(char ch)
Результат true если параметр ch один из следующих символов:
Иначе, результат'\t'\u0009 HT HORIZONTAL TABULATION'\n'\u000A LF LINE FEED (also known asNEW LINE)'\f'\u000C FF FORM FEED'\r'\u000D CR CARRIAGE RETURN''\u0020 SP SPACE
false. 20.5.20 public static char
toLowerCase(char ch)
Если символ ch имеет строчный эквивалент, определенный в таблице атрибутов Unicode, тогда тот строчный эквивалентный символ возвращается. Иначе, параметр ch возвращается.
Строчные эквиваленты, определенные в таблице атрибутов Unicode, для Unicode 1.1.5 как исправлено выше, следующим образом, где символьные коды направо от стрелок являются строчными эквивалентами символьных кодов налево от стрелок: 0041-005A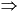
0061-007A, 00C0-00D600E0-00F6, 00D8-00DE00F8-00FE, 0100-012E0101-012F (выравнивает к разногласиям), 0132-01360133-0137 (выравнивает к разногласиям), 0139-0147013A-0148 (разногласия к выравнивают), 014A-0176014B-0177 (выравнивает к разногласиям), 017800FF, 0179-017D017A-017E (разногласия к выравнивают), 01810253, 01820183, 01840185, 01860254, 01870188, 018A0257, 018B018C, 018E0258, 018F0259, 0190025B, 01910192, 01930260, 01940263, 01960269, 01970268, 01980199, 019C026F, 019D0272, 01A0-01A401A1-01A5 (выравнивает к разногласиям), 01A701A8, 01A90283, 01AC01AD, 01AE0288, 01AF01B0, 01B1028A, 01B2028B, 01B301B4, 01B501B6, 01B70292, 01B801B9, 01BC01BD, 01C401C6, 01C501C6, 01C701C9, 01C801C9, 01CA01CC, 01CB-01DB01CC-01DC (разногласия к выравнивают), 01DE-01EE01DF-01EF (выравнивает к разногласиям), 01F101F3, 01F201F3, 01F401F5, 01FA-021601FB-0217 (выравнивает к разногласиям), 038603AC, 0388-038A03AD-03AF, 038C03CC, 038E03CD, 038F03CE, 0391-03A103B1-03C1, 03A3-03AB03C3-03CB, 03E2-03EE03E3-03EF (выравнивает к разногласиям), 0401-040C0451-045C, 040E045E, 040F045F, 0410-042F0430-044F, 0460-04800461-0481 (выравнивает к разногласиям), 0490-04BE0491-04BF (выравнивает к разногласиям), 04C104C2, 04C304C4, 04C704C8, 04CB04CC, 04D0-04EA04D1-04EB (выравнивает к разногласиям), 04EE-04F404EF-04F5 (выравнивает к разногласиям), 04F804F9, 0531-05560561-0586, 10A0-10C510D0-10F5, 1E00-1E941E01-1E95 (выравнивает к разногласиям), 1EA0-1EF81EA1-1EF9 (выравнивает к разногласиям), 1F08-1F0F1F00-1F07, 1F18-1F1D1F10-1F15, 1F28-1F2F1F20-1F27, 1F38-1F3F1F30-1F37, 1F48-1F4D1F40-1F45, 1F591F51, 1F5B1F53, 1F5D1F55, 1F5F1F57, 1F68-1F6F1F60-1F67, 1F88-1F8F1F80-1F87, 1F98-1F9F1F90-1F97, 1FA8-1FAF1FA0-1FA7, 1FB81FB0, 1FB91FB1, 1FBA1F70, 1FBB1F71, 1FBC1FB3, 1FC8-1FCB1F72-1F75, 1FCC1FC3, 1FD81FD0, 1FD91FD1, 1FDA1F76, 1FDB1F77, 1FE81FE0, 1FE91FE1, 1FEA1F7A, 1FEB1F7B, 1FEC1FE5, 1FF81F78, 1FF91F79, 1FFA1F7C, 1FFB1F7D, 1FFC1FF3, 2160-216F2170-217F, 24B6-24CF24D0-24E9, FF21-FF3AFF41-FF5A.
Отметьте что метод isLowerCase (§20.5.11) не обязательно возвратится true когда дано результат toLowerCase метод.
[Эта спецификация для метода toLowerCase планируется для введения в версии 1.1 Java, или как определено здесь, или обновляется для Unicode 2.0; см. §20.5. В предыдущих версиях Java этот метод возвращает свой параметр за все параметры, больше чем \u00FF.]
20.5.21 public static char
toUpperCase(char ch)
Если символ ch имеет прописной эквивалент, определенный в таблице атрибутов Unicode, тогда тот прописной эквивалентный символ возвращается. Иначе, параметр ch возвращается.
Прописные эквиваленты, определенные в таблице атрибутов Unicode для Unicode 1.1.5 как исправлено выше, следующим образом, где символьные коды направо от стрелок являются прописными эквивалентами символьных кодов налево от стрелок: 0061-007A0041-005A, 00E0-00F600C0-00D6, 00F8-00FE00D8-00DE, 00FF0178, 0101-012F0100-012E (разногласия к выравнивают), 0133-01370132-0136 (разногласия к выравнивают), 013A-01480139-0147 (выравнивает к разногласиям), 014B-0177014A-0176 (разногласия к выравнивают), 017A-017E0179-017D (выравнивает к разногласиям), 017F0053, 0183-01850182-0184 (разногласия к выравнивают), 01880187, 018C018B, 01920191, 01990198, 01A1-01A501A0-01A4 (разногласия к выравнивают), 01A801A7, 01AD01AC, 01B001AF, 01B401B3, 01B601B5, 01B901B8, 01BD01BC, 01C501C4, 01C601C4, 01C801C7, 01C901C7, 01CB01CA, 01CC01CA, 01CE-01DC01CD-01DB (выравнивает к разногласиям), 01DF-01EF01DE-01EE (разногласия к выравнивают), 01F201F1, 01F301F1, 01F501F4, 01FB-021701FA-0216 (разногласия к выравнивают), 02530181, 02540186, 0257018A, 0258018E, 0259018F, 025B0190, 02600193, 02630194, 02680197, 02690196, 026F019C, 0272019D, 028301A9, 028801AE, 028A01B1, 028B01B2, 029201B7, 03AC0386, 03AD-03AF0388-038A, 03B1-03C10391-03A1, 03C203A3, 03C3-03CB03A3-03AB, 03CC038C, 03CD038E, 03CE038F, 03D00392, 03D10398, 03D503A6, 03D603A0, 03E3-03EF03E2-03EE (разногласия к выравнивают), 03F0039A, 03F103A1, 0430-044F0410-042F, 0451-045C0401-040C, 045E040E, 045F040F, 0461-04810460-0480 (разногласия к выравнивают), 0491-04BF0490-04BE (разногласия к выравнивают), 04C204C1, 04C404C3, 04C804C7, 04CC04CB, 04D1-04EB04D0-04EA (разногласия к выравнивают), 04EF-04F504EE-04F4 (разногласия к выравнивают), 04F904F8, 0561-05860531-0556, 1E01-1E951E00-1E94 (разногласия к выравнивают), 1EA1-1EF91EA0-1EF8 (разногласия к выравнивают), 1F00-1F071F08-1F0F, 1F10-1F151F18-1F1D, 1F20-1F271F28-1F2F, 1F30-1F371F38-1F3F, 1F40-1F451F48-1F4D, 1F511F59, 1F531F5B, 1F551F5D, 1F571F5F, 1F60-1F671F68-1F6F, 1F701FBA, 1F711FBB, 1F72-1F751FC8-1FCB, 1F761FDA, 1F771FDB, 1F781FF8, 1F791FF9, 1F7A1FEA, 1F7B1FEB, 1F7C1FFA, 1F7D1FFB, 1F80-1F871F88-1F8F, 1F90-1F971F98-1F9F, 1FA0-1FA71FA8-1FAF, 1FB01FB8, 1FB11FB9, 1FB31FBC, 1FC31FCC, 1FD01FD8, 1FD11FD9, 1FE01FE8, 1FE11FE9, 1FE51FEC, 1FF31FFC, 2170-217F2160-216F, 24D0-24E924B6-24CF, FF41-FF5AFF21-FF3A.
Отметьте что метод isUpperCase (§20.5.12) не обязательно возвратится true когда дано результат toUpperCase метод.
[Эта спецификация для метода toUpperCase планируется для введения в версии 1.1 Java, или как определено здесь, или обновляется для Unicode 2.0; см. §20.5. В предыдущих версиях Java этот метод возвращает свой параметр за все параметры, больше чем \u00FE. Отметьте это хотя \u00FF символ нижнего регистра, его прописной эквивалент \u0178; toUpperCase в версиях Java до версии 1.1 просто последовательно не обрабатывают или используют коды символа Unicode выше \u00FF.]
20.5.22 public static char
toTitleCase(char ch)
Если символ ch имеет titlecase эквивалент, определенный в таблице атрибутов Unicode, тогда что titlecase эквивалентный символ возвращается; иначе, параметр ch возвращается.
Отметьте что метод isTitleCase (§20.5.13) не обязательно возвратится true когда дано результат toTitleCase метод. У таблицы атрибутов Unicode всегда есть атрибут titlecase, равный прописному атрибуту для символов, которые имеют прописные эквиваленты, но не разделяют форму titlecase.
Пример: Character.toTitleCase('a') возвраты 'A'
Пример: Character.toTitleCase('Q') возвраты 'Q'
Пример: Character.toTitleCase('lj') возвраты 'Lj' где 'lj' символ Unicode \u01C9 и 'Lj' его titlecase эквивалентный символ \u01C8.
[Этот метод планируется для введения в версии 1.1 Java.]
20.5.23 public static int
digit(char ch, int radix)
Возвращает числовое значение символа ch рассмотренный как цифру в указанном основании. Если значение radix не допустимое основание, или символ ch не допустимая цифра в указанном основании, тогда -1 возвращается.
Основание допустимо, если и только если его значение не является меньше чем Character.MIN_RADIX (§20.5.3) и не больше чем Character.MAX_RADIX (§20.5.4).
Символ является допустимой цифрой, если и только если одно из следующего является истиной:
isDigit возвраты true для символа, и значения десятичной цифры символа, как определено в таблице атрибутов Unicode, меньше чем указанное основание. В этом случае значение десятичной цифры возвращается.
'A'-'Z' (\u0041-\u005A) и его код является меньше чем radix+'A'-10. В этом случае ch-'A'+10 возвращается.
'a'-'z' (\u0061-\u007A) и его код является меньше чем radix+'a'-10. В этом случае ch-'a'+10 возвращается. digit планируется для введения в версии 1.1 Java, или как определено здесь, или обновляется для Unicode 2.0; см. §20.5. В предыдущих версиях Java, этот метод возвраты -1 для всех символьных кодов, больше чем \u00FF.]20.5.24 public static char
forDigit(int digit, int radix)
Возвращает символ, который представляет данную цифру в указанном основании. Если значение radix не допустимое основание, или значение digit не допустимая цифра в указанном основании, нулевом символе '\u0000' возвращается.
Основание допустимо, если и только если его значение не является меньше чем Character.MIN_RADIX (§20.5.3) и не больше чем Character.MAX_RADIX (§20.5.4).
Цифра допустима, если и только если это неотрицательно и меньше чем radix.
Если цифра является меньше чем 10, тогда символьное значение '0'+digit возвращается; иначе, 'a'+digit-10 возвращается. Таким образом, цифры, произведенные forDigit, в увеличивающемся порядке имеющем значение, символы ASCII:
0123456789abcdefghijklmnopqrstuvwxyz(они
'\u0030' через '\u0039' и '\u0061' через '\u007a'). Если прописные буквы требуются, toUpperCase метод можно вызвать на результате: Character.toUpperCase(Character.forDigit(digit, radix))
Содержание | Предыдущий | Следующий | Индекс
Спецификация языка Java (HTML, сгенерированный Блинчиком "сюзет" Pelouch 24 февраля 1998)
Авторское право © Sun Microsystems, Inc 1996 года. Все права защищены
Пожалуйста, отправьте любые комментарии или исправления к doug.kramer@sun.com