Spec-Zone .ru
спецификации, руководства, описания, API
|
|
Spec-Zone .ru
спецификации, руководства, описания, API
|
|
|
Frequently Asked Questions |
Documentation Contents |
Naming.lookup?
_Stub file in the client's
CLASSPATH? I thought it could be downloaded.
ClassNotFoundException?
java.lang.ClassMismatchError
while running my program?
ArrayStoreException. What's going on?
ClassNotFoundException for my stub
class when I try to register a remote object in the registry.
What's happening?
java.net.UnknownHostException?
UnknownHostException?
Naming.bind and Naming.lookup
take an extraordinarily long time on Windows?
java.net.SocketException:
Address already in use" when I try to run the registry?
System.exit for
graceful client termination?
unreferenced() method doesn't get called until ten minutes
after I have stopped using the remote object! How can I shorten
this delay?
rmic command in a DOS batch file?
select()
call. Is the registry implemented by polling?
Serializable in order to be written to an
ObjectOutputStream?
ObjectInputStream
from an ObjectOutputStream without a file in between?
writeObject method and receive it using the
readObject method. If I then change the value of a field
in the object and send it as before, the object that the
readObject method returns appears to be the same as the
first object and does not reflect the new value of the field. Should
I be experiencing this behavior?
Serializable but a subclass B implements
Serializable, will the fields of class A be serialized
when B is serialized?
Naming.lookup?
Even if the server is mistaken about its hostname or IP address (or has a hostname that simply isn't resolvable by clients), it will still export all of its objects using that mistaken hostname, but you will see an exception every time you try to receive one of those objects.
The hostname which you specified in Naming.lookup to
locate the registry has no effect on the hostname which is already
embedded in the remote reference to the server.
Usually, the mysterious hostname is the unqualified hostname of the server, or a private name unknown to the client's nameservice, or (in the case of Windows platforms) the server's Network->Identification->Machine Name.
The appropriate workaround is to set the system property
java.rmi.server.hostname when starting the server.
The value of the property should be the externally reachable
hostname (or IP address) of the server -- whatever works when
specified as the host-part in Naming.lookup is good
enough.
For more detail, see the questions on callbacks and fully qualified domain names.
_Stub file in the client's
CLASSPATH? I thought it could be downloaded.
java.rmi.server.codebase property, which indicates
the location from where the stub class can be loaded.
You should set the java.rmi.server.codebase property
on the server exporting a remote object.
While remote clients could set this property, they would then be
limited to only getting remote objects from the specified
codebase.
You should not assume that any client VM will have specified a
codebase that resolves to the location of your object.
When a remote object is marshalled by Java RMI (whether as an argument
to a remote call or as a return value), the codebase for the stub
class is retrieved by Java RMI and used to annotate the serialized
stub.
When the stub is unmarshalled, the codebase is used to load the
stub classfile using the RMIClassLoader,
unless the class can already be found in the
CLASSPATH or by the context classloader for the
receiving object, such as an applet codebase.
If the _Stub class was loaded by an RMIClassLoader,
then Java RMI already knows which codebase to use for its annotation.
If the _Stub class was loaded from the CLASSPATH,
then there is no obvious codebase, and Java RMI consults the
java.rmi.server.codebase system property to find the
codebase.
If the system property is not set, then the stub is marshalled
with a null codebase, which means that it cannot be used unless
the client has a matching copy of the _Stub classfile in the
client's CLASSPATH.
It is easy to forget to specify the codebase property.
One way to detect this error is to start the
rmiregistry separately and without access to the
application classes.
This will force Naming.rebind to fail if the codebase
is omitted.
For more information on the java.rmi.server.codebase
property, please take a look at our tutorial, Dynamic code downloading using Java RMI (Using the
java.rmi.server.codebase Property).
java.rmi.server.codebase property
to use any valid URL protocol, such as file or
ftp. Using an HTTP server just makes your life
simpler by providing an automated mechanism for class file
downloading. If you don't have access to an HTTP server nor the
inclination to set one up, you can use our small class file server
found at
.
ClassNotFoundException?
java.rmi.server.codebase property has
not been set (or has not been set correctly) on a VM that is
exporting your remote object(s). Please take a look at our tutorial,
Dynamic code downloading using Java RMI (Using the
java.rmi.server.codebase Property).
hashCode and equals methods
appropriately. If the client socket factory does not implement
these methods correctly, another ramification is that stubs
(using the client socket factory) that refer to the same remote
object will not be equal.
The Java RMI implementation attempts to reuse server-side ports
as well. It will only do so if there is an existing server socket
for the port created by an equivalent socket factory. Make sure
the server socket factory class implements the hashCode and
equals methods too.
If your socket factory has no instance state, a trivial
implementation of the hashCode and
equals methods are the following:
public int hashCode() { return 57; }
public boolean equals(Object o) { return this.getClass() == o.getClass() }
javaw command throws away output to stdout and
stderr, so for debugging purposes it is better to run the
java command in a separate window so that you can see
reported errors.
To do this, execute a command like the following:
start java EchoImpl
It is advised not to use the javaw command during
development.
To watch the server activity, start the server with
-Djava.rmi.server.logCalls=true.
java.lang.ClassMismatchError
while running my program?
java.rmi.registry.RegistryImpl).
This should clear things up.
ArrayStoreException. What's going on?
FooRemote[] f = new FooRemote[10];
for (int i = 0; i < f.length; i++) {
f[i] = new FooRemoteImpl();
}
Now Java RMI can put the stub into each cell of the array without an exception on the remote call.
Distributed objects behave differently than local objects. If you simply reuse a local implementation without handling locking and failure, you will probably get unpredictable results.
ClassNotFoundException for my stub
class when I try to register a remote object in the registry.
What's happening?
When you make a call to the registry to bind an object, the
registry actually binds a reference to the stub for the remote
object. In order to instantiate a stub object, the registry VM
needs to be able to load its class definition. The VM (in this case
the server VM) that sends the serialized forms of a stub in a
remote method call to the registry is responsible for annotating
the stub with the location from which its classes can be
downloaded. If stubs are not annotated properly, Java RMI will throw a
ClassNotFoundException when it tries to instantiate
the stub.
To annotate classes properly, the server needs to set the
value of the java.rmi.server.codebase property value
to the location(s) of the stub classes. Java RMI will automatically
annotate the serialized form of outgoing object instances with the
value of the java.rmi.server.codebase property.
NOTE: It is possible (and in a small number of environments appropriate) to enable the rmiregistry to unmarshal stub objects by placing all relevant stub class files in the CLASSPATH of the rmiregistry. However, the rmiregistry does not have to download stub classes. If stub classes are available locally, it will use those classes. Using the rmiregistry's CLASSPATH for stub deployment requires that all VMs that reference a stub instance obtained from that registry have the stub's class file installed locally (in the VM's CLASSPATH).
For example, if the registry loads stub classes from its CLASSPATH,
when the registry sends serialized stub objects to other VMs, those
serialized objects will be annotated with the value of the
registry's java.rmi.server.codebase property (which
will almost always be null). If the VMs receiving serialized stub
objects from the registry do not have the class files for those
stubs installed locally then those VMs are likely to throw a
ClassNotFoundException.
Instead, if classes are downloaded dynamically from a server VM's
java.rmi.server.codebase annotation, only the
server VM needs to have the stub classes in its CLASSPATH.
With this approach, application deployment is simpler and it is
possible to introduce new stub versions into a running distributed
system.
For more information on dynamic code downloading in Java RMI, please
see the tutorial,
Dynamic code downloading using Java RMI (Using the java.rmi.server.codebase).
java -Djava.rmi.server.logCalls=true YourServerImpl
where YourServerImpl is the name of your server.
If your server has hung, you can get a monitor dump and thread
dump by doing a ctrl-\ on the SolarisTM
Operating System (Solaris OS) and a ctrl-break on
Windows platforms.
java.rmi." are elements of the public
specification and are documented in the Java RMI Specification.
Properties that begin with
"sun.rmi." are only supported by certain
versions of the JavaTM SE Development Kit (JDK) software from
Sun Microsystems. While these
"sun.rmi.*" properties can be quite useful for
debugging and tuning at runtime, please note that they are not
considered part of the public API, and their use is
subject to change (or may be removed completely) in future versions
of the implementation.
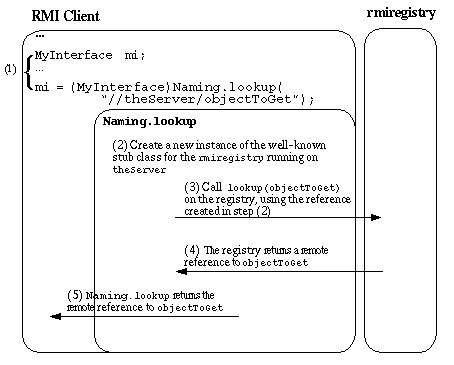
For an Java RMI client to contact a remote Java RMI server, the client must
first hold a reference to the server.
The Naming.lookup method call is the most common
mechanism by which clients initially obtain references to remote
servers.
Remote references may be obtained by other means, for example: all
remote method calls can return remote references.
This is what Naming.lookup does; it uses a well-known
stub to make a remote method call to the rmiregistry,
which sends back the remote reference to the object requested by
the lookup method.
Every remote reference contains a server hostname and port number that allow clients to locate the VM that is serving a particular remote object. Once a Java RMI client has a remote reference, the client will use the hostname and port provided in the reference to open a socket connection to the remote server.
Please note that with Java RMI the terms client and server can refer to the same program. A Java program that acts as a Java RMI server contains an exported remote object. A Java RMI client is a program that invokes one or more methods on a remote object in another virtual machine. If a VM performs both of these functions, it may be referred to as an RMI client and a Java RMI server.
java.net.UnknownHostException?
UnknownHostException.
In order to generate functional remote references, Java RMI servers
must be able to supply a fully qualified hostname or IP address
that is resolvable from all Java RMI clients (an example of a
fully qualified hostname is foo.bar.com).
If a Java RMI program provides a remote callback operation, then that
program serves a Java RMI object and consequently, must be able to
determine a resolvable hostname to use as its server hostname in
the remote references it passes to Java RMI clients.
VMs that make calls to applets that serve remote objects may
throw UnknownHostExceptions because the applet has
failed to provide a usable server hostname.
If your Java RMI application throws an UnknownHostException,
you can look at the resulting stack trace to see if the hostname
that the client is using to contact its remote server is incorrect
or not fully qualified.
If necessary, you can set the
java.rmi.server.hostname property on the server to
the correct IP address or hostname of the server machine and Java RMI
will use this property's value to generate remote references to
the server.
UnknownHostException?
java.rmi.server.hostname property to the
correct IP address of the Java RMI server machine.
You can also specify that your server use a fully qualified
hostname obtained from a name service by setting the property:
java.rmi.server.useLocalHostname=true
java.net.InetAddress.getLocalHost() to return a
fully qualified domain name.
InetAddress objects initialized local hostnames
in a static block of code, performing a reverse lookup on the
local IP address to retrieve a local hostname.
However, on machines that were not connected to the network,
this behavior caused the program to hang while
InetAddress looked for a hostname that could not
be found.
InetAddress was modified in JDK v1.1.1 to only
retrieve the [potentially unqualified] hostname returned from
a native system call, which did not attempt to consult a name
service.
Java RMI was not modified to compensate for this change since the
property java.rmi.server.hostname allowed users
to override incorrect hostnames provided by
InetAddress.
Java RMI made no attempt to consult a name service and could
default to using unqualified hostnames.
InetAddress, the
following behavior has been integrated into the most recent
versions of the JDK:
Java RMI will use an IP address or a fully qualified domain name to identify a machine that serves a remote object. Server hostnames are initialized to the value obtained by performing the following actions:
java.rmi.server.hostname is
set, Java RMI will use its value as the server hostname, and
will not attempt to find a fully qualified domain name
through any other method.
This property takes precedence over all other means of
finding a Java RMI server name.
java.rmi.server.useLocalHostname is set to
true (by default, the value of this property
is false), Java RMI applies the following routine to
obtain a hostname for the Java RMI server:
InetAddress.getLocalHost().getHostName()
method contains a "." character, then Java RMI will assume
that this value is the server's fully qualified domain
name and will use it as the server hostname.
InetAddress.getLocalHost().getHostAddress().
sun.rmi.transport.tcp.localHostnameTimeOut=timeOutMillis
java -Dsun.rmi.transport.tcp.localHostnameTimeOut=2000 MyServerApp
java.rmi.server.useLocalHostname property to
true.
In general, hostnames are more stable than IP addresses.
Activatable remote objects tend to last longer than transient
remote objects (for example, surviving a reboot).
A Java RMI client will be more likely to locate a remote object
over a long period of time if it uses a qualified hostname
rather than an explicit IP address.
Naming.bind and Naming.lookup
take an extraordinarily long time on Windows platforms?
java.net.InetAddress, which will cause TCP/IP host
name lookups - both host to address mapping and address to
hostname mapping (the InetAddress class does this for
security reasons).
On Windows platforms, the lookup functions are performed by the native
socket library, so the delays are happening not in Java RMI,
but in the libraries.
If your host is set up to use DNS, then it is usually a problem
with the DNS server not knowing about the hosts involved in
communication, and what you are experiencing are DNS lookup
timeouts.
Try specifying all the involved hostnames/addresses in the local
file \winnt\system32\drivers\etc\hosts or
\windows\hosts.
The format of a typical host file is:
IPAddress Machine Name
e.g.:
208.2.84.61 homer
This should dramatically cut down the time it takes to make the
first lookup.
192.168.1.1).
You should then find that from a DOS Shell, you can ping yourself
(for example, ping mymachine).
You should now be able to use Java RMI on the machine.
java.net.SocketException:
Address already in use" when I try to run the registry?
RegistryImpl
uses (by default 1099) is already in use.
You may have another registry running on your machine and
will need to stop it.
If Java RMI fails to make a normal (or SOCKS) connection to the intended server, and it notices that a HTTP proxy server is configured, it will attempt to tunnel Java RMI requests through that proxy server, one at a time.
There are two forms of HTTP tunnelling, tried in order. The first is http-to-port; the second is http-to-cgi.
In http-to-port tunneling, Java RMI attempts a HTTP POST request
to a http: URL directed at the exact hostname and
port number of the target server.
The HTTP request contains a single Java RMI request.
If the HTTP proxy accepts this URL, it will forward the POST
request to the listening Java RMI server, which will recognize the
request and unwrap it.
The result of the call is wrapped in a HTTP reply, which is
returned through the same proxy.
Often, HTTP proxies will refuse to proxy requests to unusual
port numbers.
In this case, Java RMI will fall back to http-to-cgi tunneling.
The Java RMI request is encapsulated in a HTTP POST request as
before, but the request URL is of the form
http://hostname:80/cgi-bin/java-rmi.cgi?port=n
(where hostname and n are the hostname and
port number of the intended server).
There must be a HTTP server listening on port 80 on the server
host, which will run the java-rmi.cgi script
(supplied with the JDK), which will in turn forward the
request to a Java RMI server listening on port n.
Java RMI can unwrap a HTTP-tunneled request without help from a
http server, CGI script, or any other external entity.
So, if the client's HTTP proxy can connect directly to the
server's port, then you don't need a java-rmi.cgi
script at all.
To trigger the use of HTTP tunneling, the standard system
property http.proxyHost must be set to the
hostname of the local HTTP proxy.
(There are reports that some Navigator versions do not set
this property.)
The major disadvantage of HTTP tunneling is that it does not permit inward calls or multiplexed connections. A secondary disadvantage is that the http-to-cgi method opens a dramatic security hole on the server side, since without modification it will redirect any incoming request to any port.
socksProxyHost must have been
set to the hostname of the SOCKS server; if the port number of
the SOCKS server is not 1080, it must be specified in the
socksProxyPort property.
This approach would appear to be the most generally useful
solution. As yet, ServerSockets do not use
SOCKS, so incoming calls must use another mechanism.
The disadvantage of this approach is that the traversal of the firewall must be done by code provided by the Java RMI server side, which does not necessarily know how that traversal must be done, nor does it automatically have sufficient privilege to traverse the firewall.
exportObject method to specify the exact port
number.
In JDK v1.1, the server must subclass the
RMISocketFactory and intercept requests to
createServerSocket(0), replacing it with a
request to bind to a specific port number.
This approach has the disadvantage that it requires the
assistance of the network administrator responsible for the
local firewall.
If the exported object is being run in a different location
(because code was downloaded to that site), then the local
firewall may be run by network administrators who don't know who you
are.
The idea here is to export objects in such a way that anyone outside the firewall who wants to call remote methods on that object instead contacts a different port (perhaps on a different machine). That different port has a running program which makes a second connection to the real server and then pumps bytes each way.
The tricky part is convincing the client to connect to the
bridge.
A downloadable socket factory (JDK, v1.2 or later) can do this
efficiently; otherwise, it is possible to set the
java.rmi.server.hostname property to name the
bridge host and arrange for port numbers to be the same.
When an outsider makes a call on the proxy, the proxy immediately forwards the call to its original object on the internal server. The use of the proxy is transparent to the outsider (but not to the internal server, who has to decide whether to pass the original reference or the proxy reference when talking to anyone).
Needless to say, this requires considerable setup and the cooperation of the local network administrators.
In the most pessimistic case, the client-side firewall allows
no direct TCP connections and has only a HTTP proxy
server so that firewalled clients can "surf the web".
In this case, your server host will receive connections at port 80
containing Java RMI requests embedded in HTTP requests.
You can use a HTTP server with the java-rmi.cgi
program, or you can run the Java RMI server directly on port 80.
Either way, the server cannot use callback objects exported by
the clients..
A more optimistic case is that the client can make direct connections to the server but cannot receive incoming connections from the server. In this case, callback objects are not normally possible either.
The most conservative approach, assuming no help from the client firewall administrators, is:
java-rmi.cgi script; or
DeleGate) on
port 80, which will accept connections and immediately
connect to the real server port to pass bytes back and
forth. This will cause getClientHost() to
return misleading information, so don't make the Registry
available through this method unless it's on a different
host.
java-rmi.cgi script that comes with
the JDK distribution with a servlet?
java-rmi.cgi script using a servlet. The example also
explains how to run a remote object inside a servlet VM.
Note: If you do not understand the role that
java-rmi.cgi plays in tunnelling remote method calls
over HTTP, please see the FAQ question regarding HTTP tunnelling in Java RMI.
java.rmi.server.Unreferenced interface (in
addition to any other necessary interfaces).
Java RMI will provide the notification by calling the
unreferenced method when all clients disconnect.
Your implementation of the unreferenced method will
determine what action your remote object should take upon
receiving such a notification.
However, if there is a reference in the registry, then the
Unreferenced.unreferenced method will never be
called.
OutOfMemoryError).
Although the Java API does not specify the timeliness of collection anyway, there is a particular reason for the what can seem like indefinitely delayed collection of remote objects in the JDK v1.1 implementation. Under the covers, the Java RMI runtime holds a weak reference to exported remote objects in a table (to keep track of local as well as remote references to the object). The only weak reference mechanism available in the JDK v1.1 VM uses a non-aggressive, caching collection policy (well-suited for a browser), so objects that are only "weakly reachable" will not get collected until the local GC decides that it really needs that memory to satisfy another allocation. For an idle server, this could never happen. But if memory is needed, an unreferenced server object will be collected.
The Java SE platform includes a new infrastructure that Java RMI will use to reduce significantly the number of conditions under which this problem occurs.
System.exit for
graceful client termination?
System.exit() is
considered abnormal termination, because it does not allow the RMI
runtime to send the appropriate "unreferenced" messages to the
server.
Executing System.runFinalizersOnExit in the client
before termination is not sufficient, because not all of the
necessary processing is handled in a finalizer; i.e. the
"unreferenced" message will not get sent to the server.
(Using "runFinalizersOnExit" is generally ill-advised and
deadlock-prone anyway.)
If you need to use System.exit() to terminate a
client VM, to ensure that remote references held in that VM are
cleaned up in a more timely fashion, you should make sure that
there are no remote references still reachable. Explicitly null
any local references to make them unreachable from running
threads. It also may help to run a full garbage collection and
to run finalizers before exiting:
System.gc();
System.runFinalization();
unreferenced() method will then be called by the Java RMI
implementation (remember that the registry is also a client for
this purpose, since it holds references for all its bindings).
If a client is holding a remote reference, it also holds a lease
for that reference, which must be renewed (by contacting the
server and making a dirty() call).
When the final lease for an exported object has expired or closed,
the object is considered unreferenced, and (if it implements
java.rmi.Unreferenced) its
unreferenced() method will be invoked.
If two or more clients have references to the same remote object,
the unreferenced() method will not be called until
all of them have expired their leases on it.
Consequently, if you are using this technique to track individual
clients, each client must have a reference to its own
Unreferenced object.
unreferenced() method doesn't get called until ten minutes
after I have stopped using the remote object! How can I shorten
this delay?
java.rmi.dgc.leaseValue, whose value is in
milliseconds.
To set this to a shorter time (for example: 30 seconds), start the
server like this:
java -Djava.rmi.dgc.leaseValue=30000 ServerMain
The default value is 600000 milliseconds (or 10 minutes).
The client will renew each lease when it is halfway expired. If the lease interval is too short, the client will waste a lot of network bandwidth needlessly renewing its lease. If the lease interval is much too short, the client will be unable to renew the lease in time, and the exported object may be deleted as a result.
Future releases of Java RMI may invalidate remote references if they fail to renew their leases (in order to preserve referential integrity); you should not rely on being able to use stale references to remote objects.
Note that you'll only have to wait for the timeout if the client
machine crashes.
If the client has some control when the disconnect occurs, it can
send out the DGC clean call quickly, making the use of
Unreferenced quite timely.
You can help this process along by nulling out any references the
client may have to the remote object and then calling
System.gc().
(In v1.1.x, you may have to run finalizers synchronously and then
run GC again.)
If or when the crashed client later restarts and contacts the server, the server can infer that the client has lost its state. If a TCP connection is held open between the client and the server throughout their interaction, then the server can detect the client reboot when a later attempt to write to the connection fails (including the hourly TCP keepalive packet, if enabled). However, Java RMI is designed not to require such permanent connections, as it impairs scalability and doesn't help very much.
Given that it is absolutely impossible to instantly determine when a network peer crashes or becomes otherwise unavailable, you must decide how your application should behave when a peer stops responding.
The major tools you have for this task are timeouts and resets. After a timeout, you may conclude that a peer is unreachable, but the peer must be aware of the timeout so that it gives up trying to reach you. The leasing mechanism is designed to do this semi-automatically.
A reset is a purge of existing state held for a peer. For example, a client may cause a reset when it first registers with its server, causing the server to discard any previous state held for that client (having deduced that the client has restarted without memory of the previous, dead, session).
Frequently, the aim is to have and maintain a definitive list of clients at the server, and to keep it up-to-date without error or failure. Since failure and delay can happen at any time in a networked system, some degree of error in the list must be anticipated. If a lease or other mechanism is used to enforce a timeout, then the problem of resource leakage is solved. If the problem of stale data is more serious -- that is, if it would interfere with correct operation -- then it must be explicitly purged in cases where it would otherwise have an effect.
For example, if a business object is locked for editing by a human, and the session dies, then the lock must be broken somehow. In this case, the lock would need a timeout, but if the same human logs in immediately and expects not to have to wait for the timeout to expire, the new session must either take over the lock or assert that the user holds no locks (allowing the server to safely kill the lock).
rmic command in a DOS batch file?
call before the executable in order for control to
return to the batch file.
For example:
call rmic ClientHandler
call rmic Server
call rmic ServerHandler
call rmic Client
java.rmi.server.RemoteServer.getClientHost method
returns the client host for the current invocation on the current
thread.
So, you cannot pass a remote object reference from a server to a client, and then send it back to the server and be able to cast it back to the original implementation class. You can, though, use the remote object reference on the server to make a remote call to the object.
If you need to find the implementation class again, you'll need to keep a table that maps the remote reference to the implementation class.
java.util.Observable and
java.util.Observer with new interfaces (you could
call them RemoteObservable and RemoteObserver).
In these new interfaces, make each of the methods throw
java.rmi.RemoteException.
Then, your remote objects can implement these interfaces.
Note that since the "wrapped" non-remote object does not extend
java.rmi.server.UnicastRemoteObject, you will need to
explicitly export the object using the exportObject
method of UnicastRemoteObject.
In doing this though, you lose the
java.rmi.server.RemoteObject implementations of the
equals, hashCode, and
toString methods.
rmiregistry on the specified host.
In general, a new connection may or may not be created for a
remote call.
Connections are cached by the Java RMI transport for future use, so if
a connection is free to the right destination for a remote call,
then it is used.
A client cannot explicitly close a connection to a server, since
connections are managed at the Java RMI transport level.
Connections will time out if they are unused for a period of time.
select()
call. Is the registry implemented by polling?
LocateRegistry.getRegistry(String host)
does not contact the registry on the host, but rather just looks
up the host to make sure it exists.
So, even though this method succeeded, this does not necessarily
mean that a registry is running on the specified host.
It just returns a stub that can then access the registry.
Users of both Java RMI and object serialization can discuss issues and
tips with other users via the mailing list
rmi-users@java.sun.com.
You can subscribe by sending an email
message containing the line
subscribe RMI-USERS
to listserv@java.sun.com, and unsubscribe by sending a message
containing the line
unsubscribe RMI-USERS
Serializable in order to be written to an
ObjectOutputStream?java.io.Serializable
interface was not made lightly. The design called for a balance between
the needs of developers and the needs of the system to be able to provide
a predictable and safe mechanism. The most difficult design constraint
to satisfy was the safety and security of classes for the Java
programming language.
If classes were to be marked as being serializable the design team worried
that a developer, either out of forgetfulness, laziness, or ignorance might
not declare a class as being Serializable and then make that class
useless for RMI or for purposes of persistence. We worried that the requirement
would place on a developer the burden of knowing how a class was to be
used by others in the future, an essentially unknowable condition. Indeed,
our preliminary design, as reflected in the alpha API, concluded that the
default case for a class ought to be that the objects in the class be serializable.
We changed our design only after considerations of security and correctness
convinced us that the default had to be that an object not be serialized.
No such restriction can be made on an object once it has been serialized; the stream of bytes that is the result of object serialization can be read and altered by any object that has access to that stream. This allows any object access to the state of a serialized object, which can violate the privacy guarantees users of the language expect. Further, the bytes in the stream can be altered in arbitrary ways, allowing the reconstruction of an object that was never created within the protections of a Java platform. There are cases in which the re-creation of such an object could compromise not only the privacy guarantees expected by users of the Java platform, but the integrity of the platform itself.
These violations cannot be guarded against, since the whole idea of serialization is to allow an object to be converted into a form that can be moved outside of the Java platform (and therefore outside of the privacy and integrity guarantees of that environment) and then be brought back into the environment. Requiring objects to be declared serializable does mean that the class designer must make an active decision to allow the possibility of such a breach in privacy or integrity. A developer who does not know about serialization should not be open to compromise because of this lack of knowledge. In addition, we would hope that the developer who declares a class to be serializable does so after some thought about the possible consequences of that declaration.
Note that this sort of security problem is not one that can be dealt with by the mechanism of a security manager. Since serialization is intended to allow the transport of an object from one virtual machine to some other (either over space, as it is used in RMI, or over time, as when the stream is saved to a file), the mechanisms used for security need to be independent of the runtime environment of any particular virtual machine. We wanted to avoid as much as possible the problem of being able to serialize an object in one virtual machine and not being able to deserialize that object in some other virtual machine. Since the security manager is part of the runtime environment, using the security manager for serialization would have violated this requirement.
Examples are easy to cite. Many classes deal with information that only
makes sense in the context of the runtime in which the particular object
exists; examples of such information include file handles, open socket
connections, security information, etc. Such data can be dealt with easily
by simply declaring the fields as transient, but such a declaration
is only necessary if the object is going to be serialized. A novice (or
forgetful, or hurried) programmer might neglect to mark fields as
transient in much the same way he or she might neglect to
mark the class as implementing the Serializable
interface. Such a case should not lead to incorrect behavior;
the way to avoid this is to not serialize objects not marked as
implementing Serializable.
Another example of this sort is the "simple" object that is the root of a graph that spans a large number of objects. Serializing such an object could result in serializing lots of others, since serialization works over an entire graph. Doing something like this should be a conscious decision, not one that happens by default.
The need for this sort of thought was brought home to us in the
group when we were going through the base Java API class libraries,
marking the system classes as serializable (where appropriate). We had
originally thought that this would be a fairly simple process, and
that most of the system classes could just be marked as implementing
Serializable and then use the default implementation with
no other changes. What we found was that this was far less often the
case than we had suspected. In a large number of the classes, careful
thought had to be given to whether or not a field should be marked as
transient or whether it made sense to serialize the class
at all.
Of course, there is no way to guarantee that a programmer or class
designer is actually going to think about these issues when marking a
class as serializable. However, by requiring the class to declare
itself as implementing the Serializable interface we do
require that some thought be given by the programmer. Having
serialization be the default state of an object would mean that lack
of thought could cause bad effects in a program, something that the
overall design of the Java platform has attempted to avoid.
javadoc tool.
As a work around, you should first remove the top-level widget from its
container (so the widgets are no longer "live"). The peers are discarded
at this point and you will save only the AWT widget state. When you later
deserialize and read the widgets back in, add the top level widget to the
frame to make the AWT widgets appear. You may need to add a show
call.
In JDK v1.1 and later, AWT widgets are serializable. The java.awt.Component
class implements Serializable.
RMI's use of serialization leaves encryption and decryption to the lower network transport. We expect that when a secure channel is needed the network connections will be made using SSL or the like (see Using RMI with SSL).
You can use ByteArrayInputStream and
ByteArrayOutputStream objects as intermediate places to
write and read bytes to and from the random access file and create
ObjectInputStreams and ObjectOutputStreams
from the byte streams to transport the objects. You just have to make
sure that you have the entire object in the byte stream or
reading/writing the object will fail.
For example, java.io.ByteArrayOutputStream can be used
to receive the bytes of ObjectOutputStream. From it you
can get a result in the form of a byte array. That in turn can be
used with ByteArrayInputStream as input to an
ObjectInput stream.
ObjectOutputStream, but the object's class may
need to be loaded by the receiver if the class is not already
available locally. The class files themselves are not serialized,
just the names of the classes. All classes must be able to be loaded
during deserialization using the normal class loading mechanisms. For
applets, this means they are loaded by the AppletClassLoader.
There are no coherency guarantees for local objects passed to a remote VM since such objects are passed by copying their contents (a true pass-by-value).
ObjectInputStream from an ObjectOutputStream
without a file in between?ObjectOutputStream and ObjectInputStream
work to/from any stream object. You could use a
ByteArrayOutputStream and then get the array and insert
it into a ByteArrayInputStream. You could also use the
piped stream classes as well. Any java.io class that extends the
OutputStream and InputStream classes can be
used.
writeObject method and receive it using the
readObject method. If I then change the value of a field
in the object and send it as before, the object that the
readObject method returns appears to be the same as the
first object and does not reflect the new value of the field. Should
I be experiencing this behavior?ObjectOutputStream class keeps track of each
object it serializes and sends only the handle if that object is seen
again. This is the way it deals with graphs of objects. The
corresponding ObjectInputStream keeps track of all of the
objects it has created and their handles so when the handle is seen
again it can return the same object. Both output and input streams
keep this state until they are freed.
Alternatively, the ObjectOutputStream class implements a reset
method that discards the memory of having sent an object, so sending an
object again will make a copy.
The difficulty with threads is that they have so much state which is intricately tied into the virtual machine that it is difficult or impossible to re-establish the context somewhere else. For example, saving the VM call stack is insufficient because if there were native methods that had called C procedures that in turn called code for the Java platform, there would be an incredible mix of Java programming language constructs and C pointers to deal with. Also, serializing the stack would imply serializing any object reachable from any stack variable.
If a thread were resumed in the same VM, it would be sharing a lot of state with the original thread, and would therefore fail in unpredictable ways if both threads were running at once, just like two C threads trying to share a stack. When deserialized in a separate VM, it's hard to tell what might happen.
ObjectOutputStream to
serialize each object.
ObjectOutputStream produces an
OutputStream; if your zip object extends the
OutputStream class there is no problem compressing it.
Here's a brief example that shows how to serialize a tree of objects.
import java.io.*;
class tree implements java.io.Serializable {
public tree left;
public tree right;
public int id;
public int level;
private static int count = 0;
public tree(int depth) {
id = count++;
level = depth;
if (depth > 0) {
left = new tree(depth-1);
right = new tree(depth-1);
}
}
public void print(int levels) {
for (int i = 0; i < level; i++)
System.out.print(" ");
System.out.println("node " + id);
if (level <= levels && left != null)
left.print(levels);
if (level <= levels && right != null)
right.print(levels);
}
public static void main (String argv[]) {
try {
/* Create a file to write the serialized tree to. */
FileOutputStream ostream = new FileOutputStream("tree.tmp");
/* Create the output stream */
ObjectOutputStream p = new ObjectOutputStream(ostream);
/* Create a tree with three levels. */
tree base = new tree(3);
p.writeObject(base); // Write the tree to the stream.
p.flush();
ostream.close(); // close the file.
/* Open the file and set to read objects from it. */
FileInputStream istream = new FileInputStream("tree.tmp");
ObjectInputStream q = new ObjectInputStream(istream);
/* Read a tree object, and all the subtrees */
tree new_tree = (tree)q.readObject();
new_tree.print(3); // Print out the top 3 levels of the tree
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
Serializable but a subclass B implements
Serializable, will the fields of class A be serialized
when B is serialized?Serializable objects are written
out and restored. The object may be restored only if class A has a no-arg
constructor that will initialize the fields of non-serializable
supertypes. If the subclass has access to the state of the superclass
it can implement writeObject and readObject
to save and restore that state.
Talk with Java RMI developers via the mailing list RMI-USERS
Copyright © 2006
All Rights Reserved.
To subscribe, send subscribe rmi-users to listserv@javasoft.com
![]()
Java Software