Spec-Zone .ru
спецификации, руководства, описания, API
|
|
Spec-Zone .ru
спецификации, руководства, описания, API
|
Этот раздел использует XSLT, чтобы преобразовать произвольную структуру данных в XML.
Вот схема процесса:
Измените существующую программу, которая читает данные, чтобы заставить это генерировать события SAX. (Является ли та программа реальным синтаксическим анализатором, или просто фильтр данных некоторого вида не важен в настоящий момент).
Используйте SAX "синтаксический анализатор", чтобы создать SAXSource для преобразования.
Используйте тот же самый объект StreamResult как создающийся в последнем осуществлении, чтобы вывести на экран результаты. (Но отметьте, что Вы могли так же, как легко создать объект DOMResult создать ДОМА в памяти).
Соедините источник проводом к результату, используя объект преобразователя сделать преобразование.
Для стартеров Вы нуждаетесь в наборе данных, который Вы хотите преобразовать и программа, способная к чтению данных. Следующие два раздела создают простой файл данных и программу, которая читает его.
Этот пример использует набор данных для адресной книги, PersonalAddressBook.ldif. Если Вы так уже не сделали, download the XSLT examples и разархивируйте их в install-dir/jaxp-1_4_2-release-date/samples каталог. Файл, показанный здесь, был произведен, создавая новую адресную книгу в Средстве рассылки Netscape, давая его некоторые фиктивные данные (одна карта адреса), и затем экспортируя его в Формате обмена данными LDAP (LDIF) формат. Это содержало в каталоге xslt/data после того, как Вы разархивировали примеры XSLT.
Следующие данные показывают запись адресной книги, которая создавалась.
Изобразите Запись Адресной книги
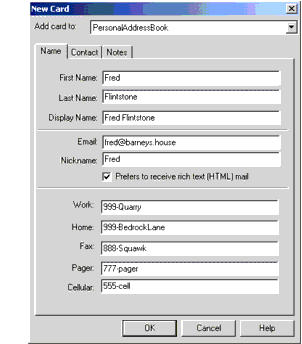
Экспорт адресной книги производит файл как один показанный затем. Части файла, о котором мы заботимся, показывают полужирным.
dn: cn=Fred Flintstone,mail=fred@barneys.house modifytimestamp: 20010409210816Z cn: Fred Flintstone xmozillanickname: Fred mail: Fred@barneys.house xmozillausehtmlmail: TRUE givenname: Fred sn: Flintstone telephonenumber: 999-Quarry homephone: 999-BedrockLane facsimiletelephonenumber: 888-Squawk pagerphone: 777-pager cellphone: 555-cell xmozillaanyphone: 999-Quarry objectclass: top objectclass: person
Отметьте, что каждая строка файла содержит имя переменной, двоеточие, и пространство, сопровождаемое значением для переменной. Переменная sn содержит фамилию человека (фамилия), и переменный cn содержит поле DisplayName от записи адресной книги.
Следующий шаг должен создать программу, которая анализирует данные.
Отметьте - код, обсужденный в этом разделе, находится в AddressBookReader01.java, который находится в каталоге xslt после того, как Вы разархивировали XSLT examples в install-dir/jaxp-1_4_2-release-date/samples каталог.
Текст для программы показывают затем. Это - чрезвычайно простая программа, которая даже не циклично выполняется для многократных записей, потому что, в конце концов, это - только демонстрационный пример.
import java.io.*;
public class AddressBookReader01 {
public static void main(String argv[]) {
// Check the arguments
if (argv.length != 1) {
System.err.println("Usage: java AddressBookReader01 filename");
System.exit (1);
}
String filename = argv[0];
File f = new File(filename);
AddressBookReader01 reader = new AddressBookReader01();
reader.parse(f);
}
// Parse the input file
public void parse(File f) {
try {
// Get an efficient reader for the file
FileReader r = new FileReader(f);
BufferedReader br = new BufferedReader(r);
// Read the file and display its contents.
String line = br.readLine();
while (null != (line = br.readLine())) {
if (line.startsWith("xmozillanickname: "))
break;
}
output("nickname", "xmozillanickname", line);
line = br.readLine();
output("email", "mail", line);
line = br.readLine();
output("html", "xmozillausehtmlmail", line);
line = br.readLine();
output("firstname","givenname", line);
line = br.readLine();
output("lastname", "sn", line);
line = br.readLine();
output("work", "telephonenumber", line);
line = br.readLine();
output("home", "homephone", line);
line = br.readLine();
output("fax", "facsimiletelephonenumber", line);
line = br.readLine();
output("pager", "pagerphone", line);
line = br.readLine();
output("cell", "cellphone", line);
}
catch (Exception e) {
e.printStackTrace();
}
}
}
Эта программа содержит три метода:
Метод main получает имя файла из командной строки, создает экземпляр синтаксического анализатора, и устанавливает это, чтобы работать, анализируя файл. Этот метод исчезнет, когда мы преобразуем программу в синтаксический анализатор SAX. (Который является одной причиной помещения кода парсинга в отдельный метод).
Этот метод работает на объекте File, отправленном этому основной подпрограммой. Как можно видеть, это очень прямо. Единственная концессия эффективности является использованием BufferedReader, который может стать важным, когда Вы начинаете работать на больших файлах.
Выходной метод содержит логику для структуры строки. Требуется три параметра. Первый параметр дает методу имя к дисплею, таким образом, это может вывести html как имя переменной вместо xmozillausehtmlmail. Второй параметр дает имя переменной, сохраненное в файле (xmozillausehtmlmail). Третий параметр дает строку, содержащую данные. Подпрограмма тогда снимает изоляцию с имени переменной от запуска строки и выводит требуемое имя плюс данные.
% cd install-dir/jaxp-1_4_2-release-date/samples.
Download the XSLT examples by clicking this link и разархивируйте их в install-dir/jaxp-1_4_2-release-date/samples каталог.cd xslt
Введите следующую команду:
% javac AddressBookReader01.java
В случае ниже, AddressBookReader01 выполняется на файле, который PersonalAddressBook.ldif, показанный выше, нашел в каталоге xslt/data после того, как Вы разархивировали демонстрационный пакет.
% java AddressBookReader01 data/PersonalAddressBook.ldif
Вы будете видеть следующий вывод:
nickname: Fred email: Fred@barneys.house html: TRUE firstname: Fred lastname: Flintstone work: 999-Quarry home: 999-BedrockLane fax: 888-Squawk pager: 777-pager cell: 555-cell
Это немного больше читаемо чем файл, показанный в Создании Простого Файла.
Этот раздел шоу, как заставить синтаксический анализатор генерировать события SAX, так, чтобы можно было использовать это в качестве основания для объекта SAXSource в XSLT, преобразовывает.
Отметьте - код, обсужденный в этом разделе, находится в AddressBookReader02.java, который находится в каталоге xslt после того, как Вы разархивировали XSLT examples в install-dir/jaxp-1_4_2-release-date/samples каталог. AddressBookReader02.java адаптируется от AddressBookReader01.java, таким образом, только различия в коде между этими двумя примерами будут обсуждены здесь.
AddressBookReader02 требует следующих выделенных классов, которые не использовались в AddressBookReader01.
import java.io.*; import org.xml.sax.*; import org.xml.sax.helpers.AttributesImpl;
Приложение также расширяет XmlReader. Это изменение преобразовывает приложение в синтаксический анализатор, который генерирует соответствующие события SAX.
public class AddressBookReader02 implements XMLReader { /* ... */ }
В отличие от выборки AddressBookReader01, у этого приложения нет метода main.
Следующие глобальные переменные будут использоваться позже в этом разделе:
public class AddressBookReader02 implements XMLReader {
ContentHandler handler;
String nsu = "";
Attributes atts = new AttributesImpl();
String rootElement = "addressbook";
String indent = "\n ";
// ...
}
ContentHandler SAX является объектом, который генерирует события SAX синтаксическим анализатором. Чтобы подать заявку в XmlReader, приложение определяет метод setContentHandler. Переменная обработчика будет содержать ссылку на объект, который отправляется, когда setContentHandler вызывается.
Когда синтаксический анализатор генерирует события элемента SAX, он должен будет предоставить пространство имен и информацию атрибута. Поскольку это - простое приложение, оно определяет нулевые значения для обоих из тех.
Приложение также определяет корневой элемент для структуры данных (addressbook) и устанавливает строку отступа, чтобы улучшить удобочитаемость вывода.
Кроме того метод синтаксического анализа изменяется так, чтобы он взял InputSource (а не File) как параметр и учел исключения, которые он может генерировать:
public void parse(InputSource input) throws IOException, SAXException
Теперь, вместо того, чтобы создать новый экземпляр FileReader, как был сделан в AddressBookReader01, читатель инкапсулируется объектом InputSource:
try {
java.io.Reader r = input.getCharacterStream();
BufferedReader Br = new BufferedReader(r);
// ...
}
Отметьте - следующие шоу раздела, как создать входной исходный объект и что вставляется, это, фактически, будет буферизованный читатель. Но AddressBookReader мог использоваться кем-то еще, где-нибудь по линии. Этот шаг удостоверяется, что обработка будет эффективна, независимо от читателя, которого Вам дают.
Следующий шаг должен изменить метод синтаксического анализа, чтобы генерировать события SAX для запуска документа и корневого элемента. Следующий выделенный код делает это:
public void parse(InputSource input) {
try {
// ...
String line = br.readLine();
while (null != (line = br.readLine())) {
if (line.startsWith("xmozillanickname: "))
break;
}
if (handler == null) {
throw new SAXException("No content handler");
}
handler.startDocument();
handler.startElement(nsu, rootElement, rootElement, atts);
output("nickname", "xmozillanickname", line);
// ...
output("cell", "cellphone", line);
handler.ignorableWhitespace("\n".toCharArray(),
0, // start index
1 // length
);
handler.endElement(nsu, rootElement, rootElement);
handler.endDocument();
}
catch (Exception e) {
// ...
}
}
Здесь, проверки приложения, чтобы удостовериться, что синтаксический анализатор должным образом конфигурируется с ContentHandler. (Для этого приложения мы не заботимся ни о чем больше). Это тогда генерирует события для запуска документа и корневого элемента, и заканчивается, отправляя событие конца за корневым элементом и событие конца для документа.
Два элемента примечательны в этой точке:
Событие setDocumentLocator не было отправлено, потому что это является дополнительным. Было это важный, то событие будет сразу отправлено перед событием startDocument.
Событие ignorableWhitespace сгенерировано перед концом корневого элемента. Это, также, является дополнительным, но это решительно улучшает удобочитаемость вывода, как будет замечен коротко. (В этом случае пробел состоит из единственной новой строки, которая отправляется таким же образом, что символы отправляются методу символов: как символьный массив, начальное значение индекса, и длина).
Теперь, когда события SAX сгенерированы для документа и корневого элемента, следующий шаг должен изменить выходной метод, чтобы генерировать соответствующие события элемента для каждого элемента данных. Удаление звонка в System.out.println(name + ": " + text) и добавление следующего выделенного кода достигают этого:
void output(String name, String prefix, String line)
throws SAXException {
int startIndex =
prefix.length() + 2; // 2=length of ": "
String text = line.substring(startIndex);
int textLength = line.length() - startIndex;
handler.ignorableWhitespace (indent.toCharArray(),
0, // start index
indent.length()
);
handler.startElement(nsu, name, name /*"qName"*/, atts);
handler.characters(line.toCharArray(),
startIndex,
textLength;
);
handler.endElement(nsu, name, name);
}
Поскольку методы ContentHandler могут отослать назад SAXExceptions к синтаксическому анализатору, синтаксический анализатор должен быть подготовлен иметь дело с ними. В этом случае ни один не ожидается, таким образом, приложению просто позволят перестать работать, если кто-либо происходит.
Длина данных тогда вычисляется, снова генерируя некоторый игнорируемый пробел для удобочитаемости. В этом случае есть только один уровень данных, таким образом, мы можем использовать строку фиксированного отступа. (Если бы данные были более структурированы, то мы должны были бы вычислить сколько пространства, чтобы сделать отступ, в зависимости от вложения данных).
Отметьте - строка отступа не имеет никакого значения к данным, но сделает вывод намного легче читать. Без той строки все элементы были бы связаны вплотную:
<addressbook> <nickname>Fred</nickname> <email>...
Затем, следующий метод конфигурирует синтаксический анализатор с ContentHandler, который должен получить события, которые это генерирует:
void output(String name, String prefix, String line)
throws SAXException {
// ...
}
// Allow an application to register a content event handler.
public void setContentHandler(ContentHandler handler) {
this.handler = handler;
}
// Return the current content handler.
public ContentHandler getContentHandler() {
return this.handler;
}
Несколько других методов должны быть реализованы, чтобы удовлетворить интерфейс XmlReader. С целью этого осуществления нулевые методы сгенерированы для всех них. Производственное приложение, однако, потребовало бы, чтобы методы обработчика ошибок были реализованы, чтобы произвести более устойчивое приложение. Для этого примера, тем не менее, следующий код генерирует нулевые методы для них:
// Allow an application to register an error event handler.
public void setErrorHandler(ErrorHandler handler) { }
// Return the current error handler.
public ErrorHandler getErrorHandler() {
return null;
}
Затем следующий код генерирует нулевые методы для остатка от интерфейса XmlReader. (Большинство из них значимо для реального синтаксического анализатора SAX, но имеет небольшое опирание на приложение преобразования данных как этот).
// Parse an XML document from a system identifier (URI).
public void parse(String systemId) throws IOException, SAXException
{ }
// Return the current DTD handler.
public DTDHandler getDTDHandler() { return null; }
// Return the current entity resolver.
public EntityResolver getEntityResolver() { return null; }
// Allow an application to register an entity resolver.
public void setEntityResolver(EntityResolver resolver) { }
// Allow an application to register a DTD event handler.
public void setDTDHandler(DTDHandler handler) { }
// Look up the value of a property.
public Object getProperty(String name) { return null; }
// Set the value of a property.
public void setProperty(String name, Object value) { }
// Set the state of a feature.
public void setFeature(String name, boolean value) { }
// Look up the value of a feature.
public boolean getFeature(String name) { return false; }
У Вас теперь есть синтаксический анализатор, который можно использовать, чтобы генерировать события SAX. В следующем разделе Вы будете использовать это, чтобы создать исходный объект SAX, который позволит Вам преобразовывать данные в XML.
Учитывая синтаксический анализатор SAX, чтобы использовать в качестве источника события, можно создать преобразователь, чтобы привести к результату. В этом разделе TransformerApp будет обновлен, чтобы привести к потоковому выходному результату, хотя это могло так же, как легко привести к результату ДОМА.
Отметьте - Примечание: код, обсужденный в этом разделе, находится в TransformationApp03.java, который находится в каталоге xslt после того, как Вы разархивировали XSLT examples в install-dir/jaxp-1_4_2-release-date/samples каталог.
Чтобы запуститься с, TransformationApp03 отличается от TransformationApp02 в классах, которые это должно импортировать, чтобы создать объект SAXSource. Эти классы показывают выделенные ниже. Классы ДОМА больше не необходимы в этой точке, так были отброшены, хотя оставление внутри их не делает ничего плохого.
import org.xml.sax.SAXException; import org.xml.sax.SAXParseException; import org.xml.sax.ContentHandler; import org.xml.sax.InputSource; import javax.xml.transform.sax.SAXSource; import javax.xml.transform.stream.StreamResult;
Затем, вместо того, чтобы создать экземпляр ДОМА DocumentBuilderFactory, приложение создает синтаксический анализатор SAX, который является экземпляром AddressBookReader:
public class TransformationApp03 {
static Document document;
public static void main(String argv[]) {
// ...
// Create the sax "parser".
AddressBookReader saxReader = new AddressBookReader();
try {
File f = new File(argv[0]);
// ...
}
// ...
}
}
Затем, следующий выделенный код создает объект SAXSource
// Use a Transformer for output // ... Transformer transformer = tFactory.newTransformer(); // Use the parser as a SAX source for input FileReader fr = new FileReader(f); BufferedReader br = new BufferedReader(fr); InputSource inputSource = new InputSource(br); SAXSource source = new SAXSource(saxReader, inputSource); StreamResult result = new StreamResult(System.out); transformer.transform(source, result);
Здесь, TransformationApp03 создает буферизованного читателя (как отмечалось ранее) и инкапсулирует это во входном исходном объекте. Это тогда создает объект SAXSource, передавая это читатель и объект InputSource, и передачи это к преобразователю.
Когда приложение работает, преобразователь конфигурирует себя как ContentHandler для синтаксического анализатора SAX (AddressBookReader) и говорит синтаксическому анализатору работать на объекте inputSource. События, сгенерированные синтаксическим анализатором тогда, идут в преобразователь, который делает соответствующую вещь и передает данные на объект результата.
Наконец, TransformationApp03 не генерирует исключения, таким образом, код обработки исключений, замеченный в TransformationApp02, больше не присутствует.
% cd install-dir/jaxp-1_4_2-release-date/samples.
Download the XSLT examples by clicking this link и разархивируйте их в install-dir/jaxp-1_4_2-release-date/samples каталог.cd xslt
Введите следующую команду:
% javac TransformationApp03.java
В случае ниже, TransformationApp03 выполняется на файле PersonalAddressBook.ldif, найденном в каталоге xslt/data после того, как Вы разархивировали демонстрационный пакет.
% java TransformationApp03 data/PersonalAddressBook.ldif
Вы будете видеть следующий вывод:
<?xml version="1.0" encoding="UTF-8"?>
<addressbook>
<nickname>Fred</nickname>
<email>Fred@barneys.house</email>
<html>TRUE</html>
<firstname>Fred</firstname>
<lastname>Flintstone</lastname>
<work>999-Quarry</work>
<home>999-BedrockLane</home>
<fax>888-Squawk</fax>
<pager>777-pager</pager>
<cell>555-cell</cell>
</addressbook>
Как можно видеть, файл формата LDIF, PersonalAddressBook был преобразован в XML!
|
