Spec-Zone .ru
спецификации, руководства, описания, API
|
|
Spec-Zone .ru
спецификации, руководства, описания, API
|
API JDBC является API Java, который может получить доступ к любому виду табличных данных, особенно данные, хранившие в Реляционной базе данных.
JDBC помогает Вам записать приложения Java, которые управляют этими тремя действиями программирования:
Следующий простой фрагмент кода дает простой пример этих трех шагов:
public void connectToAndQueryDatabase(String username, String password) {
Connection con = DriverManager.getConnection(
"jdbc:myDriver:myDatabase",
username,
password);
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery("SELECT a, b, c FROM Table1");
while (rs.next()) {
int x = rs.getInt("a");
String s = rs.getString("b");
float f = rs.getFloat("c");
}
}
Этот короткий фрагмент кода инстанцирует a DriverManager объект соединиться с драйвером базы данных и журналом в базу данных, инстанцирует a Statement возразите, что переносит Ваш запрос языка SQL к базе данных; инстанцирует a ResultSet объект, который получает результаты Вашего запроса, и выполняет простое while цикл, который получает и выводит на экран те результаты. Это - это простое.
JDBC включает четыре компонента:
API JDBC — API JDBC™ обеспечивает программируемый доступ к реляционным данным от языка программирования Java™. Используя API JDBC, приложения могут выполнить SQL-операторы, получить результаты, и распространить, возвращается к базовому источнику данных. API JDBC может также взаимодействовать с многократными источниками данных в распределенной, неоднородной среде.
API JDBC является частью платформы Java, которая включает Java™ Standard Edition (Java™ SE) и Java™ Enterprise Edition (EE Java™). JDBC 4.0 API делится на два пакета: java.sql и javax.sql. Оба пакета включаются в Java SE и платформы EE Java.
Менеджер по Драйверу JDBC — JDBC DriverManager class определяет объекты, которые могут соединить приложения Java с драйвером JDBC. DriverManager традиционно была магистраль архитектуры JDBC. Это является довольно маленьким и простым.
Стандартные Пакеты расширения javax.naming и javax.sql позвольте Вам использовать a DataSource объект, зарегистрированный в Именовании Java и Каталоге Interface™ (JNDI) именование службы, чтобы установить соединение с источником данных. Можно использовать любой соединительный механизм, но использование a DataSource объект рекомендуется когда бы ни было возможно.
Тестовый Комплект JDBC — тестовый комплект драйвера JDBC помогает Вам решить, что драйверы JDBC выполнят Вашу программу. Эти тесты не являются всесторонними или исчерпывающими, но они действительно осуществляют многие из важных функций в API JDBC.
Мост JDBC-ODBC — мост программного обеспечения Java обеспечивает доступ JDBC через драйверы ODBC. Отметьте, что Вы должны загрузить двоичный код ODBC на каждую клиентскую машину, которая использует этот драйвер. В результате драйвер ODBC является самым соответствующим на корпоративной сети, где клиентские установки не являются большой проблемой, или для кода сервера приложений, записанного в Java в трехуровневой архитектуре.
Этот След использует первые два из этих этих четырех компонентов JDBC, чтобы соединиться с базой данных и затем создать программу java, которая использует команды SQL, чтобы связаться с тестовой Реляционной базой данных. Последние два компонента используются в специализированных средах, чтобы протестировать веб-приложения, или связаться с осведомленным о ODBC DBMSs.
API JDBC поддерживает и двухуровневые и трехуровневые модели обработки для доступа к базе данных.
Рисунок 1: двухуровневая Архитектура для Доступа к данным.
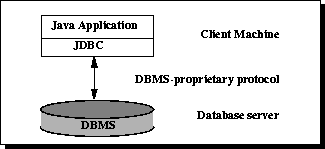
В двухуровневой модели, апплете Java или приложении говорит непосредственно с источником данных. Это требует драйвера JDBC, который может связаться с определенным получаемым доступ источником данных. Команды пользователя поставляются базе данных или другому источнику данных, и результаты тех операторов отсылают назад к пользователю. Источник данных может быть расположен на другой машине, с которой пользователь соединяется через сеть. Это упоминается как клиент-серверная конфигурация с машиной пользователя как клиент, и машинный корпус источник данных как сервер. Сеть может быть интранет, которая, например, соединяет сотрудников в пределах корпорации, или это может быть Интернет.
В трехуровневой модели команды отправляются "среднему уровню" служб, который тогда отправляет команды источнику данных. Источник данных обрабатывает команды и отсылает результаты назад к среднему уровню, который тогда отправляет их пользователю. Директора MIS считают трехуровневую модель очень привлекательной, потому что средний уровень позволяет обеспечить контроль над доступом и видами обновлений, которые могут быть сделаны к корпоративным данным. Другое преимущество состоит в том, что это упрощает развертывание приложений. Наконец, во многих случаях, трехуровневая архитектура может обеспечить преимущества производительности.
Рисунок 2: трехуровневая Архитектура для Доступа к данным.
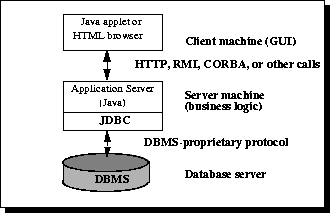
До недавнего времени средний уровень часто писался на языках, таких как C или C++, которые предлагают быструю производительность. Однако, с введением оптимизирующих компиляторов, которые преобразовывают Байт-код Java в эффективный специфичный для машины код и технологии, такие как Предприятие JavaBeans™, платформа Java быстро становится стандартной платформой для разработки среднего уровня. Это - большое плюс, позволяя использовать в своих интересах устойчивость Java, многопоточность, и средства защиты.
С предприятиями, все более и более используя язык программирования Java для того, чтобы записать серверный код, API JDBC используется все больше в среднем уровне трехуровневой архитектуры. Некоторые из функций, которые делают JDBC технологией сервера, являются ее поддержкой объединения в пул соединения, распределенных транзакций, и разъединенных наборов строк. API JDBC также, что предоставляет доступ к источнику данных от среднего уровня Java.
База данных является средством того, чтобы хранить информацию таким способом, которым информация может быть получена от этого. В самых простых сроках реляционная база данных является той, которая представляет информацию в таблицах со строками и столбцами. Таблица упоминается как отношение в том смысле, что это - набор объектов того же самого типа (строки). Данные в таблице могут быть связаны согласно общим ключам или понятиям, и возможность получить связанные данные от таблицы является основанием для термина реляционная база данных. Система управления базами данных (DBMS) обрабатывает способ, которым данные сохранены, сохраняются, и получаются. В случае реляционной базы данных Система управления реляционными базами данных (RDBMS) выполняет эти задачи. DBMS как использующийся в этой книге является общим термином, который включает RDBMS.
Реляционные таблицы следуют за определенными правилами целостности гарантировать, что данные, которые они содержат, остаются точными и всегда доступны. Во-первых, строки в реляционной таблице должны все быть отличными. Если есть дублирующиеся строки, могут быть проблемы, решающие, какой из двух возможных выборов является корректным. Для большинства DBMSs пользователь может определить, что дублирующиеся строки не позволяются, и если это будет сделано, то DBMS предотвратит добавление любых строк, которые копируют существующую строку.
Второе правило целостности традиционной реляционной модели состоит в том, что значения столбцов не должны повторять группы или массивы. Третий аспект целостности данных включает понятие нулевого значения. База данных заботится о ситуациях, где данные, возможно, не доступны при использовании нулевого значения, чтобы указать, что значение отсутствует. Это не приравнивается к пробелу или нулю. Пробел считают равным другому пробелу, нуль равен другому нулю, но два нулевых значения не считают равными.
Когда каждая строка в таблице отличается, возможно использовать один или более столбцов, чтобы идентифицировать определенную строку. Этот уникальный столбец или группу столбцов вызывают первичным ключом. Любой столбец, который является частью первичного ключа, не может быть нулем; если бы это было, то первичный ключ, содержащий это, больше не был бы полным идентификатором. Это правило упоминается как объектная целостность.
Employees таблица иллюстрирует некоторые из этих понятий реляционной базы данных. У этого есть пять столбцов и шесть строк с каждой строкой, представляющей различного сотрудника.
Employees Таблица
Employee_Number |
First_name |
Last_Name |
Date_of_Birth |
Car_Number |
|---|---|---|---|---|
| 10001 | Аксель | Вашингтон | 28-Aug-43 | 5 |
| 10083 | Arvid | Шарма | 24-Nov-54 | нуль |
| 10120 | Джонас | Гинсберг | 01-Jan-69 | нуль |
| 10005 | Флоренция | Войоковский | 04-Jul-71 | 12 |
| 10099 | Шон | Вашингтон | 21-Sep-66 | нуль |
| 10035 | Элизабет | Ямагучи | 24-Dec-59 | нуль |
Первичный ключ для этой таблицы обычно был бы числом сотрудника, потому что каждый, как гарантируют, будет отличаться. (Число также более эффективно чем строка для того, чтобы сделать сравнения.) Также было бы возможно использовать First_Name и Last_Name потому что комбинация двух также идентифицирует только одну строку в нашей базе данных-образце. Используя одну только фамилию не работал бы, потому что есть два сотрудника с фамилией "Вашингтона". В данном случае имена все отличаются, таким образом, можно было очевидно использовать, что столбец как первичный ключ, но лучше избегать использования столбца, где копии могли произойти. Если Элизабет Ямэгучи получает задание в этой компании, и первичный ключ First_Name, RDBMS не будет позволять ее имени быть добавленным (если это было определено, что никакие копии не разрешаются). Поскольку уже есть Элизабет в таблице, добавляя, что второй сделал бы первичный ключ бесполезным как способ идентифицировать только одну строку. Отметьте это, хотя используя First_Name и Last_Name уникальный составной ключ для этого примера, это не могло бы быть уникально в большей базе данных. Отметьте также что Employee таблица предполагает, что может быть только один автомобиль на сотрудника.
SELECT ОператорыSQL является языком, разработанным, чтобы использоваться с реляционными базами данных. Есть ряд основных команд SQL, который считают стандартным и используется всем RDBMSs. Например, все RDBMSs используют SELECT оператор.
A SELECT оператор, также названный запросом, используется, чтобы получить информацию от таблицы. Это определяет одни или более заголовков столбцов, одну или более таблиц, из которых можно выбрать, и некоторые критерии для выбора. RDBMS возвращает строки записей столбца, которые удовлетворяют установленные требования. A SELECT оператор, такой как следующее выберет первые и последние имена сотрудников, у которых есть служебные машины:
SELECT First_Name, Last_Name FROM Employees WHERE Car_Number IS NOT NULL
Набор результатов (набор строк, которые удовлетворяют требование не наличия нуля в Car_Number столбец), следует. Имя и фамилия печатаются для каждой строки, которая удовлетворяет требование потому что SELECT оператор (первая строка) определяет столбцы First_Name и Last_Name. FROM пункт (вторая строка) дает таблицу, из которой будут выбраны столбцы.
| FIRST_NAME | LAST_NAME |
|---|---|
| Аксель | Вашингтон |
| Флоренция | Войоковский |
Следующий код производит набор результатов, который включает целую таблицу, потому что это просит все столбцы в табличных Сотрудниках без ограничений (нет WHERE пункт). Отметьте это SELECT * означает "ИЗБРАННЫЙ все столбцы."
SELECT * FROM Employees
WHERE Пункты WHERE пункт в a SELECT оператор обеспечивает критерии для того, чтобы они выбрали значения. Например, в следующем фрагменте кода, значения будут выбраны, только если они происходят подряд, в котором столбец Last_Name начинается со строки 'Вашингтон'.
SELECT First_Name, Last_Name FROM Employees WHERE Last_Name LIKE 'Washington%'
Ключевое слово LIKE используется, чтобы сравнить строки, и это предлагает функцию, что образцы, содержащие подстановочные знаки, могут использоваться. Например, во фрагменте кода выше, есть знак процента (%) в конце 'Вашингтона', который показывает, что любое значение, содержащее строку 'Вашингтон' плюс нуль или больше дополнительных символов, удовлетворит этот критерий выбора. Таким образом, 'Вашингтон' или 'Washingtonian' были бы соответствиями, но 'Промывка' не будет. Другой подстановочный знак, используемый в LIKE пункты являются underbar (_), который обозначает любой символ. Например,
WHERE Last_Name LIKE 'Ba_man'
соответствовал бы 'Бэтмэну', 'Бармену', 'Бандиту', 'Balman', 'Лоточнику', 'Bamman', и так далее.
У фрагмента кода ниже есть a WHERE пункт, который использует знак "равно" (=), чтобы сравнить числа. Это выбирает первое и последнее имя сотрудника, который является присвоенным автомобилем 12.
SELECT First_Name, Last_Name FROM Employees WHERE Car_Number = 12
Следующий фрагмент кода выбирает первые и последние имена сотрудников, число сотрудника которых больше чем 10005:
SELECT First_Name, Last_Name FROM Employees WHERE Employee_Number > 10005
WHERE пункты могут стать довольно тщательно продуманными, с многократными условиями и, в некотором DBMSs, вложенных условиях. Этот краткий обзор не будет касаться сложный WHERE пункты, но следующий фрагмент кода имеет a WHERE пункт с двумя условиями; этот запрос выбирает первые и последние имена сотрудников, число сотрудника которых - меньше чем 10100 и у кого нет служебной машины.
SELECT First_Name, Last_Name FROM Employees WHERE Employee_Number < 10100 and Car_Number IS NULL
Специальный тип WHERE пункт включает соединение, которое объясняется в следующем разделе.
Отличительный признак реляционных баз данных - то, что возможно получить данные больше чем от одной таблицы в том, что вызывают соединением. Предположите, что после получения имен сотрудников, у которых есть служебные машины, один, хотел узнать, кто имеет который автомобиль, включая то, чтобы делать, модель, и год автомобиля. Эта информация хранится в другой таблице, Cars:
Cars Таблица
Car_Number |
Make |
Model |
Year |
|---|---|---|---|
| 5 | Хонда | Гражданский DX | 1996 |
| 12 | Тойота | Венчик | 1999 |
Должен быть один столбец, который появляется в обеих таблицах, чтобы связать их друг с другом. Этот столбец, который должен быть первичным ключом в одной таблице, вызывают внешним ключом в другой таблице. В этом случае столбец, который появляется в двух таблицах, Car_Number, который является первичным ключом для таблицы Cars и внешний ключ в табличных Сотрудниках. Если Honda Civic 1996 года была разрушена и удалена из Cars таблица, тогда Car_Number 5 должен был бы также быть удален из таблицы Сотрудников, чтобы поддержать то, что вызывают ссылочной целостностью. Иначе, столбец внешнего ключа (Car_Number) в Employees таблица содержала бы запись, которая ни к чему не обращалась в Cars. Внешний ключ должен или быть нулем или равный существующему значению первичного ключа таблицы, к которой это обращается. Это отличается от первичного ключа, который, возможно, не является нулем. Есть несколько нулевых значений в Car_Number столбец в таблице Employees потому что для сотрудника возможно не иметь служебную машину.
Следующий код просит первые и последние имена сотрудников, у которых есть служебные машины и для того, чтобы делать, модели, и год тех автомобилей. Отметьте что FROM пункт перечисляет и Сотрудников и Автомобили, потому что запрошенные данные содержатся в обеих таблицах. Используя имя таблицы и точку (.) прежде, чем имя столбца указывает, какая таблица содержит столбец.
SELECT Employees.First_Name, Employees.Last_Name,
Cars.Make, Cars.Model, Cars.Year
FROM Employees, Cars
WHERE Employees.Car_Number = Cars.Car_Number
Это возвращает набор результатов, который будет выглядеть подобным следующему:
FIRST_NAME |
LAST_NAME |
MAKE |
MODEL |
YEAR |
|---|---|---|---|---|
| Аксель | Вашингтон | Хонда | Гражданский DX | 1996 |
| Флоренция | Войоковский | Тойота | Венчик | 1999 |
Команды SQL делятся на категории, два основных, являющиеся Языком манипулирования данными (DML) команды и Язык определения данных (DDL) команды. Команды DML имеют дело с данными, или получение этого или изменение этого, чтобы сохранить это актуальным. Команды DDL создают или изменяют таблицы и другие объекты базы данных, такие как представления, и индексирует.
Список более общих команд DML следует:
SELECT — используемый, чтобы запросить и вывести на экран данные от базы данных. SELECT оператор определяет который столбцы включать в набор результатов. Огромное большинство команд SQL, используемых в приложениях, SELECT операторы.
INSERT — добавляют новые строки к таблице. INSERT используется, чтобы заполнить недавно составленную таблицу или добавить новую строку (или строки) к уже существующей таблице.
DELETE — удаляет указанную строку или набор строк от таблицы
UPDATE — изменяет существующее значение в столбце или группе столбцов в таблице
Более общие команды DDL следуют:
CREATE TABLE — составляет таблицу с именами столбцов, которые обеспечивает пользователь. Пользователь также должен определить тип для данных в каждом столбце. Типы данных изменяются от одного RDBMS до другого, таким образом, пользователь, возможно, должен был бы использовать метаданные, чтобы установить типы данных, используемые определенной базой данных. CREATE TABLE обычно используется менее часто чем команды манипулирования данными, потому что таблица составляется только однажды, тогда как добавление или удаление строк или изменение отдельных значений обычно происходят более часто.
DROP TABLE — удаляет все строки и удаляет табличное определение из базы данных. Реализация API JDBC обязана поддерживать DROP TABLE команда как определено SQL92, Транзитным Уровнем. Однако, поддержка CASCADE и RESTRICT опции DROP TABLE является дополнительным. Кроме того, поведение DROP TABLE определяется с помощью реализации, когда есть представления или ограничения целостности, определенные что ссылка отбрасываемая таблица.
ALTER TABLE — добавляет или удаляет столбец из таблицы. Это также добавляет или отбрасывает табличные ограничения и изменяет атрибуты столбца
Строки, которые удовлетворяют условия запроса, вызывают набором результатов. Число строк, возвращенных в наборе результатов, может быть нулем, один, или многие. Пользователь может получить доступ к данным в наборе результатов одна строка за один раз, и курсор обеспечивает средства сделать это. Курсор может считаться указателем в файл, который содержит строки набора результатов, и у того указателя есть возможность отследить, из которых в настоящий момент получают доступ к строке. Курсор позволяет пользователю обрабатывать каждую строку набора результатов сверху донизу и следовательно может использоваться для итеративной обработки. Большинство DBMSs создает курсор автоматически, когда набор результатов сгенерирован.
Ранее добавленные новые возможности версий API JDBC курсора набора результатов, позволяя это переместить вперед обоих и назад и также позволяя это переместиться в указанную строку или в строку, позиция которой относительно другой строки.
Когда один пользователь получает доступ к данным в базе данных, другой пользователь может получать доступ к тем же самым данным одновременно. Если, например, первый пользователь обновляет некоторые столбцы в таблице одновременно, второй пользователь выбирает столбцы из той же самой таблицы, для второго пользователя возможно получить частично старые данные и частично обновленные данные. Поэтому DBMSs используют транзакции, чтобы поддержать данные в непротиворечивом состоянии (непротиворечивость данных), разрешая больше чем одному пользователю получить доступ к базе данных одновременно (параллелизм данных).
Транзакция является рядом той или большего количества SQL-операторов, которые составляют логическую единицу работы. Транзакция заканчивается или фиксацией или откатом в зависимости от того, есть ли какие-либо проблемы с параллелизмом данных или непротиворечивостью данных. Оператор фиксации делает постоянным изменения, следующие из SQL-операторов в транзакции, и оператор отката отменяет все изменения, следующие из SQL-операторов в транзакции.
Блокировка является механизмом, который мешает двум транзакциям управлять теми же самыми данными одновременно. Например, блокировка таблицы препятствует тому, чтобы таблица была отброшена, если есть незафиксированная транзакция на той таблице. В некотором DBMSs блокировка таблицы также блокирует все строки в таблице. Блокировка строки препятствует тому, чтобы две транзакции изменили ту же самую строку, или это препятствует тому, чтобы одна транзакция выбрала строку, в то время как другая транзакция все еще изменяет это.
Хранимая процедура является группой SQL-операторов, которые могут быть позваны по имени. Другими словами это - исполняемый код, минипрограмма, которая выполняет определенную задачу, которая может быть вызвана тем же самым путем, можно вызвать функцию или метод. Традиционно, хранимые процедуры были записаны в специфичном для DBMS языке программирования. Последняя генерация продуктов базы данных позволяет хранимым процедурам быть записанными, используя язык программирования Java и API JDBC. Хранимые процедуры, записанные в языке программирования Java, являются байт-кодом, переносимым между DBMSs. Как только хранимая процедура пишется, она может использоваться и снова использована, потому что DBMS, который поддерживает хранимые процедуры, поскольку его имя подразумевает, сохранит ее в базе данных.
Следующий код является примером того, как создать очень простую хранимую процедуру, используя язык программирования Java. Отметьте, что хранимая процедура является только статическим методом Java, который содержит нормальный код JDBC. Это принимает два входных параметра и использует их, чтобы изменить номер машины сотрудника.
Не волнуйтесь, не понимаете ли Вы пример в этой точке. Пример кода ниже представляется только, чтобы иллюстрировать то, на что похожа хранимая процедура. Вы изучите, как записать код в этом примере в учебных руководствах, которые следуют.
import java.sql.*;
public class UpdateCar {
public static void UpdateCarNum(int carNo, int empNo)
throws SQLException {
Connection con = null;
PreparedStatement pstmt = null;
try {
con = DriverManager.getConnection(
"jdbc:default:connection");
pstmt = con.prepareStatement(
"UPDATE EMPLOYEES " +
"SET CAR_NUMBER = ? " +
"WHERE EMPLOYEE_NUMBER = ?");
pstmt.setInt(1, carNo);
pstmt.setInt(2, empNo);
pstmt.executeUpdate();
}
finally {
if (pstmt != null) pstmt.close();
}
}
}
Базы данных хранят пользовательские данные, и они также хранят информацию о базе данных непосредственно. У большинства DBMSs есть ряд системных таблиц, которые перечисляют таблицы в базе данных, имена столбцов в каждой таблице, первичных ключах, внешних ключах, хранимых процедурах, и т.д. У каждого DBMS есть свои собственные функции для того, чтобы получить информацию о табличных разметках и функциях базы данных. JDBC обеспечивает интерфейс DatabaseMetaData, который должен реализовать писатель драйвера так, чтобы его методы возвратили информацию о драйвере и/или DBMS, для которого пишется драйвер. Например, большое количество методов возвращаются, поддерживает ли драйвер определенную функциональность. Этот интерфейс дает пользователям и оснащает стандартизованный способ, чтобы получить метаданные.
Вообще, инструменты записи разработчиков и драйверы - те наиболее вероятно, чтобы касаться метаданных.
|
