Построение древовидных структур XML
Обычно, если Вы хотите добавить или изменить содержание XML-документа, необходимо создать статическую древовидную структуру, полностью представляющую элементы и другие конструкции в документе. Древовидные представления также важны, если Вы намереваетесь проверить XML-документ против DTD (или другая схема языка), который предписывает логическую структуру документа.
Когда большинство разработчиков хочет создать представления дерева СТИЛЯ DOM XML-документов, они используют основанный на дереве синтаксический анализатор, не синтаксический анализатор потоковой передачи, такой как NSXMLParser. (Основанные на дереве механизмы парсинга, однако, обычно создаются поверх потоковой передачи синтаксических анализаторов.), Тем не менее, который не означает, что Вы не можете создать древовидные структуры с помощью экземпляра NSXMLParser. Несмотря на то, что эта статья не вдается в большие подробности о методах для построения древовидных структур XML с помощью NSXMLParser, это обрисовывает в общих чертах общий подход, который Вы могли проявить.
Можно представлять любой XML-документ как иерархическое дерево, «узлы» которого являются элементами, показывающими отношения родителя и дочернего элемента с другими элементами. Каждый элемент может иметь один или несколько дочерних элементов и, за исключением корневого элемента, имеет точно один родительский элемент. Дерево привязывается корневым элементом, который является единственным элементом в дереве без родителя. «Листовые» узлы дерева обычно являются теми элементами, содержащими только текст, несмотря на то, что они могут также быть смешанными элементами или пустыми элементами.
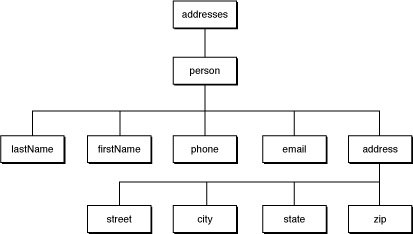
Например, рассмотрите следующий короткий XML-документ:
<?xml version="1.0" encoding="UTF-8"?> |
<!DOCTYPE addresses SYSTEM "addresses.dtd"> |
<addresses> |
<person idnum="0123"> |
<lastName>Doe</lastName> |
<firstName>John</firstName> |
<phone location="mobile">(201) 345-6789</phone> |
<email>jdoe@foo.com</email> |
<address> |
<street>100 Main Street</street> |
<city>Somewhere</city> |
<state>New Jersey</state> |
<zip>07670</zip> |
</address> |
</person> |
</addresses> |
Следующее дерево узлов элемента представляет этот документ:
Существует несколько возможных способов создать древовидное представление XML-документа с помощью NSXMLParser. Эта статья, однако, смотрит на рекурсивный, объектно-ориентированный подход, динамично передающий ответственность делегации среди объектов, представляющих элементы документа. (Это стратегическое смещение делегата NSXMLParser обсуждено далее в Использовании Многократных Делегатов.) Программируемым результатом являются двунаправленные связанные списки объектов и массивы объектов; абстрактным результатом является древовидное представление документа.
Процедура для построения дерева с помощью этого подхода влечет за собой следующие шаги:
Создайте класс, экземпляры которого представляют элементы XML-документа. Класс должен определить имя элемента и его (непосредственного) родителя и дочерние элементы (one-many) отношения; это должно также инкапсулировать атрибуты, связанные с элементом. Как краткая нотация для этой процедуры, мы вызовем этот класс MyElement.
От объекта верхнего уровня в приложении загрузите XML-документ, создайте экземпляр NSXMLParser для него, присвойте объект верхнего уровня как делегата и начните анализировать документ (см., что XML Анализирует Основы).
Синтаксический анализатор встречается с корневым элементом документа сначала и отправляет
parser:didStartElement:namespaceURI:qualifiedName:attributes:его делегату. Делегат создает объект MyElement представлять этот корневой элемент и устанавливает его родителя вnil. Метод, создающий и инициализирующий объект также, устанавливает его, чтобы быть новым делегатом экземпляра NSXMLParser.Синтаксический анализатор встречается со следующим элементом документа — первого дочернего элемента корневого элемента — и снова отправляет делегата
parser:didStartElement:namespaceURI:qualifiedName:attributes:. Делегат является теперь объектом MyElement, недавно созданным для представления корневого элемента. Это создает другой объект MyElement представлять новый элемент (в процессе, устанавливающем новый объект быть делегатом и устанавливающий себя, чтобы быть родителем), и добавляет новый объект к его списку дочерних элементов.Новый делегат получает следующее
parser:didStartElement:namespaceURI:qualifiedName:attributes:сообщение, идентифицируя его первый дочерний элемент, и это создает его и добавляет его к его списку дочерних элементов.Когда «листовые» элементы обнаружения синтаксического анализатора, содержащие текст, смешали содержание или пустые элементы, этот рекурсивный спуск посредством первого ответвления дерева заканчивается. Если там смешан содержание, спуск не действительно закончен с тех пор
parser:didStartElement:namespaceURI:qualifiedName:attributes:отправляется делегату даже после того, как это получитparser:foundCharacters:для элемента тока. Обработка зависит от вида элемента:Если это - пустой элемент, обработка переходит непосредственно к следующему шагу (тег элементов конца)
Если существует только текст, связанный с узлом элемента тока, делегат отвечает на
parser:foundCharacters:сообщение путем накопления текста (в последовательномparser:foundCharacters:вызовы).Если там будет смешан содержание, то делегат обработает текст даже после того, как это получит сообщения, уведомляющие его относительно начинать-элемента и тегов элементов конца для встроенных элементов. Один способ обработать это состоит в том, чтобы обернуть текст в специальные объекты текстового элемента и вставить их (в надлежащий порядок) в дочернем списке элемента.
Наконец, синтаксический анализатор отправляет
parser:didEndElement:namespaceURI:qualifiedName:делегату, уведомляя его, что элемент теперь завершен. Делегат устанавливает нового делегата, чтобы быть его родителем и возвратами.Если родитель имеет больше дочерних элементов, синтаксический анализатор отправляет ему следующее
parser:didStartElement:namespaceURI:qualifiedName:attributes:сообщение; родительский объект MyElement создает экземпляр MyElement для представления его следующего дочернего элемента (в процессе, устанавливающем его, чтобы быть новым делегатом и устанавливающий себя, чтобы быть родителем нового MyElement), и добавляет недавно созданный объект к его списку дочерних элементов. Однако, если родитель больше не имеет дочерних элементов для добавления к его списку (т.е. он получаетparser:didEndElement:namespaceURI:qualifiedName:обменивайтесь сообщениями вместо этого), это устанавливает нового делегата, чтобы быть его родителем и возвратами.Процедура продолжается этим способом, пока весь XML-документ не обрабатывается, и все ответвления дерева создаются.
Объекты, которые являются узлами дерева (представляющий главным образом элементы) должны быть в состоянии распечатать себя как код XML. Ваше приложение должно также реализовать алгоритм, спрашивающий объекты распечатать себя в надлежащей последовательности документа.