Порядок байтов
Архитектура микропроцессора обычно использует два различных метода для хранения отдельных байтов многобайтовых числовых данных в памяти. Это различие упоминается как «порядок байтов» или “природа порядка байтов”. Большую часть времени формат порядка байтов Вашего компьютера может быть безопасно проигнорирован, но при определенных обстоятельствах это становится критически важным. OS X обеспечивает множество функций для превращения данных одного порядка байтов в другого.
Процессоры Intel x86 хранят двухбайтовое целое число младшим значащим байтом сначала, сопровождаемый старшим значащим байтом. Это вызывают порядком байтов с прямым порядком байтов. Другой CPUs, такой как PowerPC CPU, хранит двухбайтовое целое число его старшим значащим байтом сначала, сопровождаемый его младшим значащим байтом. Это вызывают порядком байтов с обратным порядком байтов. Большую часть времени формат порядка байтов Вашего компьютера может быть безопасно проигнорирован, но при определенных обстоятельствах это становится критически важным. Например, при попытке считать данные из файлов, создававшихся на компьютере, который имеет различную природу порядка байтов, чем Ваш, различие в порядке байтов может привести к неправильным результатам. Та же проблема может произойти при чтении данных из сети.
Для предоставления конкретного примера, вокруг которого можно обсудить вопросы формата порядка байтов рассмотрите случай простой структуры C, определяющей два четырехбайтовых целых числа как показано в Перечислении 1.
Структура данных перечисления 1 В качестве примера
struct { |
UInt32 int1; |
UInt32 int2; |
} aStruct; |
Предположим, что код, показанный в Перечислении 2, используется для инициализации структуры, показанной в Перечислении 1.
Перечисление 2 , Инициализирующее структуру в качестве примера
ExampleStruct aStruct; |
aStruct.int1 = 0x01020304; |
aStruct.int2 = 0x05060708; |
Рассмотрите схему на рисунке 1, показывающем, как процессор с обратным порядком байтов или система памяти организовали бы данные в качестве примера. В системе с обратным порядком байтов физическая память организована с адресом каждого байта, увеличивающегося от старшего значащего до младшего значащего.
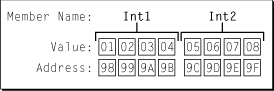
Заметьте, что поля сохранены более значительными байтами левым и менее значительными байтами вправо. Это означает что адрес старшего значащего байта поля адреса Int1 0x98, в то время как адрес 0x9B соответствует младшему значащему байту Int1.
Схема на рисунке 2 показывает, как система с прямым порядком байтов организовала бы данные.
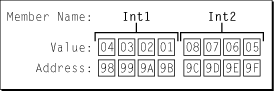
Заметьте, что самый низкий адрес каждого поля теперь соответствует младшему значащему байту вместо старшего значащего байта. Если необходимо было распечатать значение Int1 в системе с прямым порядком байтов Вы видели бы, что несмотря на то, чтобы быть сохраненным в различном порядке байтов, она все еще интерпретируется правильно как десятичное значение 16909060.
Теперь предположите, что значения данных в качестве примера, инициализированные кодом, показанным в Перечислении 2, сгенерированы в системе с прямым порядком байтов и сохранены на диск. Предположите, что данные записаны в диск в адресном байтом порядке. Когда считано из диска системой с обратным порядком байтов, данные были бы снова размечены в памяти, как проиллюстрировано на рисунке 2. Проблема состоит в том, что данные находятся все еще в прямом порядке байтов даже при том, что это интерпретируется в системе с обратным порядком байтов. Это различие заставляет значения быть оцененными неправильно. В этом примере, десятичном значении поля Int1 должен быть 16909060, но из-за неправильного порядка байтов это оценено как 67305985. Это явление вызывают свопингом байта и происходит, когда данные в одном формате порядка байтов считаны системой, использующей другой формат порядка байтов.
К сожалению, это - проблема, которая не может быть решена в общем случае. Причина состоит в том, что способ, которым Вы подкачиваете, зависит от формата Ваших данных. Символьные строки обычно не становятся подкачанными вообще, длинные слова получают подкачанный четырехбайтовый конец для конца, слова получают подкачанный двухбайтовый конец для конца. Любая программа, которая должна подкачать данные вокруг поэтому, должна знать тип данных, порядок порядка байтов исходных данных и порядок порядка байтов узла.
Функции в CFByteOrder.h позвольте Вам выполнять свопинг байта на двухбайтовых и четырехбайтовых целых числах, а также значениях с плавающей точкой. Надлежащее использование этих функций помогает Вам гарантировать, что данные, которыми управляет Ваша программа, находятся в корректном порядке порядка байтов. Посмотрите раздел Byte Swapping для подробных данных об использовании этих функций. Обратите внимание на то, что функции свопинга байта Базовой Основы доступны на OS X только.