Основание Unicode объектов CFString
Концептуально, объект CFString представляет массив 16-разрядных символов Unicode (UniChar) вместе с количеством числа символов. Основанные на Unicode строки в Базовой Основе обеспечивают существенное основание для интернационализации программного обеспечения, которое Вы разрабатываете. Unicode позволяет разработать и локализовать единственную версию приложения для пользователей, говорящих на большинстве письменных языков в мире, включая российскую (Кириллицу), арабский, китайский и японский язык.
Стандарт Unicode публикуется Консорциумом Unicode (http://www .unicode.org), Международная организация по стандартизации. Стандарт определяет три формы кодирования (UTF-8, UTF-16, UTF-32), которые используют общий репертуар символов и допускают кодирование целого миллион символов. Это достаточно для всех известных требований кодировки символов. «Символ» в этой схеме является самым маленьким полезным элементом текста на языке; таким образом это может быть символ, как понято на большинстве европейских языков, идеограмма (китайские ханьцы), слог (японский hiragana), или некоторая другая лингвистическая единица. Закодированные символы также включают математические, технические, и другие символы, а также символы автоматизированного контроля и диакритические знаки. Каждый символ Unicode представлен «кодовой точкой», имеющей глиф, имя и уникальное числовое значение.
С UTF-16 (16-разрядное) кодирование Unicode передает 65 000 возможных кодовых точек. Эта способность находится на отмеченном контрасте по отношению к стандартным 8-разрядным кодировкам, разрешающим только 256 символов и таким образом требующим тщательно продуманных вспомогательных схем, таких как сдвиг или выходящим из битов к явно выраженным символам кроме найденных в общих индоевропейских сценариях. В то время как все другие символы доступны через пар вызванных суррогатных пар 16-разрядных элементов кода, все в большой степени используемые символы вписываются в единственный 16-разрядный элемент кода. Суррогатная пара является последовательностью двух модулей UTF-16, взятых от определенных зарезервированных диапазонов, вместе представляющих единственную кодовую точку Unicode. CFString имеет функции для преобразования между суррогатными парами и представлением UTF-32 соответствующей кодовой точки Unicode.
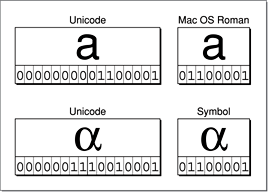
В дополнение к его схеме кодирования стандарт Unicode указывает отображения от схемы Unicode до репертуаров международных, национальных, и отраслевые наборы символов. Рисунок 1 иллюстрирует два из этих отображений. Строковые объекты делают частое использование из отображений кодирования. Базовое представление (и во многих случаях базовая система хранения) строк основано на Unicode. Однако кодировки, требуемые интерфейсами программирования и устройствами вывода, фактически выводящими на экран строки в пользовательском интерфейсе, являются обычно 8-разрядными. Таким образом существует потребность в эффективном и точном преобразовании между Unicode и другими кодировками. Строковые объекты имеют функции что цель, как описано в Преобразовании Между Строковыми Кодировками.
Для получения дополнительной информации о стандарте Unicode посмотрите веб-сайт консорциума. Консорциум также публикует диаграммы кодовых точек Unicode и глифов в www.unicode.org/charts/.