Соображения безопасности
Безопасность уровня ядра может означать много вещей, в зависимости от того, какой код ядра Вы пишете. Эта глава указывает на некоторые проблемы коллективной безопасности на уровне ядра или почти уровне ядра и где применимо, описывает способы избежать их. Эти проблемы охвачены в следующих разделах:
Многие из этих проблем также важны для прикладного программирования, но крайне важны для программистов, работающих в ядре. Другие являются специальными замечаниями, которые программисты приложения не могли бы ожидать или ожидать.
Для понимания безопасности в OS X важно понять, что существует две модели обеспечения безопасности на работе. Один из них является моделью обеспечения безопасности ядра, основывающейся на пользователях, группах и очень основных правах на группу и в расчете на пользователя, которые являются, в свою очередь, вместе со списками управления доступом для увеличенной гибкости. Другой модель обеспечения безопасности пользовательского уровня, основывающаяся на ключах, цепочках для ключей, группах, пользователях, основанной на пароле аутентификации и узле других подробных данных, выходящих за рамки этого документа.
Пользовательский уровень безопасности содержит две основных характеристики, о которых необходимо знать как программист ядра: Сервер безопасности и менеджер по Цепочке для ключей.
Сервер безопасности состоит из демона и различных библиотек доступа для кэширования разрешения сделать определенные задачи, основанные на различных средних значениях аутентификации, включая пароли и состав группы. Когда программа запрашивает разрешение сделать что-то, Сервер безопасности в основном говорит «да» или «нет» и кэши, что решение так, чтобы дальнейшие запросы от того пользователя (для подобных действий в единственном контексте) не требовали переаутентификации сроком на время.
Менеджер по Цепочке для ключей является демоном, предоставляющим услуги, связанные с цепочкой для ключей, центральным репозиторием для шифрования/аутентификационных ключей пользователя. Дополнительные сведения о ключах см. в Основанной на ключе Аутентификации и Шифровании.
Подробные данные использования модели обеспечения безопасности пользовательского уровня далеко вне объема этого документа. Однако, если Вы пишете приложение, требующее служб этой природы, необходимо рассмотреть использование в своих интересах менеджера по Серверу безопасности и Цепочке для ключей от части пространства пользователя приложения, вместо того, чтобы делать попытку эквивалентных служб в ядре. Больше информации об этих службах может быть найдено в веб-сайте Документации Разработчика Apple в http://developer .apple.com/documentation.
Импликации безопасности разбивки на страницы
Разбивка на страницы долго была основной проблемой для сознательных безопасность программистов. Если Вы пишете программу, делающую шифрование, существования даже небольшой части открытого текста документа в запоминающем устройстве могло быть достаточно для сокращения сложности повреждения того шифрования порядками величины.
Действительно, много типов данных, таких как хеши, незашифрованные версии уязвимых данных, и аутентификационные маркеры, не должны обычно писаться в диск вследствие потенциала для злоупотребления. Это повышает интересную проблему. Нет никакого хорошего способа иметь дело с этим в пространстве пользователя (если программа не работает как root). Однако для кода ядра, возможно препятствовать тому, чтобы страницы были выписаны к запоминающему устройству. Этот процесс упоминается как “соединяющий проводом вниз” память и описан далее в Копировании Отображения и Блока Памяти.
Основная цель соединенной проводом памяти состоит в том, чтобы позволить основанный на DMA I/O. Так как аппаратные средства, контроллеры DMA обычно не понимают виртуальное обращение, информация, используемая в I/O, должны быть физически в памяти в определенном расположении и не должны перемещаться, пока операция I/O не завершена. Этот механизм может также использоваться, чтобы препятствовать тому, чтобы уязвимые данные были записаны в запоминающее устройство.
Поскольку соединенная проводом память никогда не может разбиваться на страницы (пока это не является неподключенным), проводное соединение больших объемов памяти имеет решительные последствия производительности, особенно в системах с мелкими суммами памяти. Если у Вас есть очень серьезное основание сделать так, поэтому необходимо заботиться, чтобы не соединить проводом вниз память без разбора и только соединить проводом вниз память.
В OS X можно соединить проводом вниз память во время выделения или впоследствии. Соединять память проводом во время выделения:
В Наборе I/O вызвать
IOMallocиIOFreeвыделить и освободить соединенную проводом память.В других расширениях ядра вызвать
OSMallocиOSFreeи передайте тип тега, флаги которого установлены вOSMT_DEFAULT.В коде пространства пользователя выделите количества размера страницы со своим выбором API, и затем вызовите
mlockсоединять их проводом.В самом ядре (не в расширениях ядра), можно также использовать
kmem_allocи связанные функции.
Для получения дополнительной информации о соединенной проводом памяти посмотрите, что Память Отображается и Блочное Копирование.
Переполнение буфера и недопустимый ввод
Переполнение буфера является одной из более общих ошибок и в приложении и в программировании ядра. Наиболее распространенной причине не удается выделить площадь для Символа Нулевого, завершающего строку в C или C++. Однако ввод данных пользователем может также вызвать переполнение буфера, если входные буферы фиксированного размера используются, и надлежащую заботу не соблюдают для предотвращения переполнения этих буферов.
Самая очевидная защита, в этом случае, является лучшей. Или не используйте буферы фиксированной длины или добавляйте код, чтобы отклонить или усечь ввод, переполняющий буфера. Подробные данные реализации в любом случае зависят от типа кода, который Вы пишете.
Например, если Вы работаете со строками, и усечение приемлемо вместо использования strcpy, необходимо использовать strlcpy ограничить объем данных для копирования. OS X обеспечивает ограниченные длиной версии многих строковых функций, включая strlcpy, strlcat, strncmp, snprintf, и vsnprintf.
Если усечение данных не приемлемо, необходимо явно вызвать strlen определить длину входной строки и возвратить ошибку, если это превышает максимальную длину (меньше, чем размер буфера).
Другие типы недопустимого ввода может быть несколько более трудно обработать, как бы то ни было. Как правило необходимо быть уверены, что операторы переключения имеют случай по умолчанию, если Вы не перечислили каждое юридическое значение для ширины типа.
Частая ошибка предполагает что, перечисляя каждое возможное значение enum тип обеспечивает защиту. Перечисление обычно реализуется как любой a char или int внутренне. Небрежный или злонамеренный программист мог легко передать любое значение функции ядра, включая не явно перечисленных в типе, просто при помощи различного прототипа, определяющего параметр как, например, int.
Другая частая ошибка состоит в том, чтобы предположить, что можно разыменовать указатель, переданный функции другой функцией. Необходимо всегда проверять на нулевых указателей прежде, чем разыменовать их. Запуск функции с
int do_something(bufptr *bp, int flags) { |
char *token = bp->b_data; |
самый верный способ гарантировать, что кто-то еще передаст в нулевом буферном указателе, или злонамеренно или из-за ошибки программиста. В пользовательской программе это является раздражающим. В файловой системе это разрушительно.
Безопасность особенно важна для кода ядра, рисующего ввод из сети. Предположения о размере пакета часто являются причиной проблем безопасности. Всегда наблюдайте за пакетами, которые являются слишком большими и обрабатывают их разумным способом. Аналогично, всегда проверяйте контрольные суммы на пакетах. Это может помочь Вам определить, был ли пакет изменен, поврежден или усеченный в пути, хотя это далеко от защиты от случайных ошибок. Если законность данных от сети имеет огромное значение, необходимо использовать удаленную аутентификацию, подписание и механизмы шифрования, такие как описанные в Удаленной аутентификации и Основанной на ключе Аутентификации и Шифровании.
Удостоверения пользователя
Как описано во введении в эту главу, OS X имеет два различных средних значения аутентификации пользователей. Модель обеспечения безопасности пользовательского уровня (включая менеджера по Цепочке для ключей и Сервер безопасности) выходит за рамки этого документа. Модель обеспечения безопасности ядра, однако, представляет больший интерес для разработчиков ядра и является намного более прямой, чем модель пользовательского уровня.
Модель обеспечения безопасности ядра основывается на двух механизмах: учетные данные рядового пользователя и полномочия ACL. Первые учетные данные рядового пользователя, розданы в ядре для идентификации текущего пользователя и группы обработки вызовов. Второй механизм аутентификации, списки управления доступом (ACLs), обеспечивает управление доступом на более прекрасном уровне гранулярности.
Одна из самых важных вещей помнить, когда работа с учетными данными состоит в том, что они для каждого процесса, не на контекст. Это важно, потому что процесс может не работать как пользователь консоли. Двумя примерами этого являются процессы, запущенные с ssh сеанс (так как ssh работает в контексте запуска), и setuid программы (которые работают как различный пользователь в том же контексте входа в систему).
Крайне важно знать об этих проблемах. Если Вы связываетесь с a setuid root Приложение GUI в контексте входа в систему пользователя, и если Вы выполняете другое приложение или считываете уязвимые данные, Вы, вероятно, хочет обработать его, как будто это имело те же полномочия как пользователь консоли, не полномочия эффективного идентификатора пользователя, вызванного путем выполнения setuid. Это особенно проблематично при контакте с программами, работающими как setuid root если пользователь консоли не находится в администраторской группе. Отказ выполнить разумные проверки может привести к главным дырам в системе безопасности в будущем.
Однако это не жесткое правило. Иногда не очевидно, использовать ли учетные данные рабочего процесса или тех из пользователя консоли. В таких случаях часто разумно иметь вспомогательное приложение, показывают диалоговое окно на консоли для требования взаимодействия от пользователя консоли. Если это не возможно, хорошее эмпирическое правило должно принять меньшие из полномочий текущих и пользователей консоли, поскольку почти всегда лучше иметь код ядра, иногда не удаются предоставить необходимую услугу, чем предоставить ту услугу непреднамеренно неавторизованному пользователю или процессу.
Обычно проще определить пользователя консоли из приложения пространства пользователя, чем от кода пространства ядра. Таким образом необходимо обычно делать такие проверки от пространства пользователя. Если это не возможно, однако, переменная console_user (сохраняемый подсистемой VFS), даст Вам uid последнего владельца /dev/console (сохраняемый небольшим количеством кода в chown системный вызов). Это - конечно, не идеальное решение, но оно действительно обеспечивает наиболее вероятные идентификационные данные пользователя консоли. Так как это - только “лучшее предположение”, однако, необходимо использовать это, только если Вы не можете сделать надлежащей регистрации в пространстве пользователя.
Учетные данные рядового пользователя
Учетные данные рядового пользователя, используемые в ядре, сохранены в переменной типа struct ucred. Они главным образом используются в специализированных частях ядра — обычно в местах, где определяющий фактор в полномочиях - работает ли вызывающая сторона как пользователь root.
Эта структура имеет четыре поля:
cr_ref— подсчет ссылок (используемый внутренне)cr_uid— идентификатор пользователяcr_ngroups— число групп вcr_groupscr_groups[NGROUPS]— список групп, которым принадлежит пользователь
Эта структура имеет внутреннюю ссылку в противоречии с, предотвращают непреднамеренно освобождение памяти, связанной с ним, в то время как это все еще используется. Поэтому Вы не должны без разбора копировать этот объект, но должны вместо этого или использовать crdup копировать его или использование crcopy копировать его и (потенциально) освободить оригинал. Необходимо быть уверены crfree любые копии Вы могли бы сделать. Можно также создать новое, пустое ucred структура с crget.
Прототипы для этих функций следуют:
struct ucred *crdup(struct ucred *cr)struct ucred *crcopy(struct ucred *cr)struct ucred *crget(void)void crfree(struct ucred *cr)
Списки управления доступом
Списки управления доступом являются новой функцией в OS X v10.4. Списки управления доступом прежде всего используются в части файловой системы ядра OS X и поддерживаются с помощью kauth API.
kauth API описан в заголовочном файле /System/Library/Frameworks/Kernel.framework/Headers/sys/kauth.h. Поскольку этот API все еще развивается, подробная документация еще не доступна.
Удаленная аутентификация
Это - одна из более трудных проблем в компьютерной безопасности: возможность идентифицировать кого-то соединяющегося с компьютером удаленно. Один из самых безопасных методов является использованием шифрования с открытым ключом, описанного более подробно в Основанной на ключе Аутентификации и Шифровании. Однако много других средних значений аутентификации возможны с различными степенями безопасности.
Некоторые другие схемы аутентификации включают:
слепое доверие
Аутентификация только для IP
комбинация IP и аутентификации по паролю
Большинство из них очевидно, и не требует никакого дальнейшего объяснения. Однако шифры Вернама и основанную на времени аутентификацию могут быть незнакомыми многим людям вне кругов безопасности и таким образом стоит упомянуть более подробно.
Шифры Вернама
На основе понятия пар «ответа проблемы» аутентификация шифра Вернама (OTP) требует, чтобы у обеих сторон был идентичный список пар чисел, слов, символов, или что бы то ни было, сортированный первым элементом. При попытке получить доступ к удаленной системе, удаленная система предлагает пользователю с проблемой. Пользователь находит проблему в первом столбце, затем передает соответствующий ответ обратно. Также это могло быть автоматизированным обменом между двумя частями программного обеспечения.
Для максимальной безопасности никакая проблема никогда не должна выпускаться дважды. Поэтому и потому что эти системы были первоначально реализованы с блокнотом, содержащим ответ проблемы или пар CR, такие системы часто вызывают шифрами Вернама.
Разовая природа аутентификации OTP лишает возможности кого-то предполагать надлежащий ответ на любую определенную проблему атакой грубой силой (путем отвечания на тот вызов неоднократно с различными ответами). В основном единственный способ повредить такую систему, за исключением удачного предположения, состоит в том, чтобы фактически знать некоторую часть содержания списка пар.
Поэтому шифры Вернама могут использоваться по небезопасным каналам передачи. Если кто-то отслеживает коммуникацию, они могут получить ту пару ответа проблемы. Однако та информация бесполезна им, с тех пор которые определенная проблема никогда не будет выпускаться снова. (Это даже не сокращает потенциальное выборочное пространство для ответов, так как только проблемы должны быть уникальными.)
Основанная на времени аутентификация
Это - вероятно, наименее понятые средние значения аутентификации, хотя она обычно используется такими технологиями как SecurID. Понятие является относительно прямым. Вы начинаете с математической функции, берущей небольшое количество параметров (два, например) и возвращающей новый параметр. Хорошим примером такой функции является функция, генерирующая набор Чисел Фибоначчи (возможно усеченный после определенного числа битов с произвольными начальными значениями семени).
Возьмите эту функцию и добавьте третий параметр, t, представление времени в модулях k секунды. Заставьте функцию быть производящей функцией на t, с двумя значениями семени, a и b, где
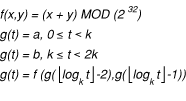
Другими словами, каждый k секунды, Вы вычисляете новое значение на основе предыдущих двух и некоторого уравнения. Тогда отбросьте самое старое значение, заменив его вторым по возрасту значением, и замените второе по возрасту значение значением, которое Вы просто сгенерировали.
Пока оба конца имеют то же понятие текущего времени и исходных двух чисел, они могут тогда вычислить последний раз сгенерированное число и использовать это в качестве совместно используемого секрета. Конечно, если Вы пишете код, делающий это, необходимо использовать закрытую форму этого уравнения, начиная с вычисления Чисел Фибоначчи рекурсивно без дополнительного хранения растет на O(2^(t/k)), который не практичен когда t измеряется в годах и k маленькая константа, измеренная в секундах.
Безопасность такой схемы зависит от различных свойств функции генератора, и подробные данные такой функции выходят за рамки этого документа. Для получения дополнительной информации необходимо получить вводный текст на криптографии. такой как Прикладная Криптография Брюса Шнайера.
Временные файлы
Временные файлы являются основным источником головных болей безопасности. Если программа не устанавливает полномочия правильно и в правильном порядке, это может предоставить средние значения атакующему, чтобы произвольно изменить или считать эти файлы. Влияние безопасности таких модификаций зависит от содержания файлов.
Временные файлы имеют намного меньше беспокойства программистам ядра, так как большая часть кода ядра не использует временные файлы. Действительно, код ядра не должен обычно использовать файлы вообще. Однако много людей, программирующих в ядре, делают так для упрощения использования приложений, которые могут использовать временные файлы. Также, эту проблему стоит отметить.
Наиболее распространенная проблема с временными файлами состоит в том, что для злонамеренного третьего лица часто возможно удалить временный файл и заменить различным с расслабленными полномочиями в его месте. В зависимости от содержания файла это могло колебаться от того, чтобы быть незначительным неудобством к тому, чтобы быть относительно большой дырой в системе безопасности, особенно если файл содержит сценарий оболочки, собирающийся быть выполненным с полномочиями пользователя программы.
/dev/mem и /dev/kmem
Одно особенно болезненное удивление людям, делающим программирование безопасности в большей части UNIX или подобных UNIX средах, является существованием /dev/mem и /dev/kmem. Эти файлы устройств позволяют root пользователь для произвольного доступа к содержанию физической памяти и памяти ядра, соответственно. Нет абсолютно ничего, что можно сделать для предотвращения этого. С точки зрения ядра корень является вездесущим и всезнающим. Если это - проблема безопасности для Вашей программы, то необходимо рассмотреть, должна ли программа использоваться в системе, которой кто-то еще управляет, и принять необходимые меры предосторожности.
Основанная на ключе аутентификация и шифрование
Основанная на ключе аутентификация и шифрование являются якобы некоторыми более безопасными средними значениями аутентификации и шифрования, и могут существовать во многих формах. Наиболее распространенные формы основаны на совместно используемом секрете. DES, 3DES (тройной DES), IDEA, twofish и шифры шифра является примерами схем шифрования на основе совместно используемого секрета. Пароли являются примером схемы аутентификации на основе совместно используемого секрета.
Идея позади большей части основанного на ключе шифрования состоит в том, что у Вас есть ключ шифрования некоторой произвольной длины, использующейся для кодирования данных, и тот же самый ключ используется противоположным способом (или в некоторых случаях, таким же образом) для декодирования данных.
Проблема с совместно используемой секретной безопасностью состоит в том, что начальный ключевой обмен должен произойти безопасным способом. Если целостность ключа поставилась под угрозу во время передачи, целостность данных потеряна. Если ключ может быть сгенерирован заранее и помещен в обе транспортных конечных точки безопасным способом, это не беспокойство. Однако во многих случаях это не возможно или практично, потому что этими двумя конечными точками (быть ими физические устройства или системные задачи) управляют различные люди или объекты. К счастью, альтернатива существует, известная как доказательства нулевого знания.
Понятие доказательства нулевого знания - то, что созданы две на вид произвольных ценности ключа, x и y, и что эти значения связаны некоторым ƒ математической функции таким способом который
ƒ(ƒ(a,k1),k2) = a |
Т.е. применение известной функции к исходному открытому тексту с помощью первого ключа приводит к шифрованному тексту, когда та же самая функция применяется к шифрованному тексту с помощью второго ключа, возвращающему исходные данные. Это также обратимо, означая это
ƒ(ƒ(a,k2),k1) = a |
Если функция f выбран правильно, чрезвычайно трудно получить x из y и наоборот, который означал бы, что нет никакой функции, которая может легко преобразовать шифрованный текст назад в открытый текст, основанный на ключе, используемом для кодирования его.
Пример этого должен выбрать математическую функцию, чтобы быть
f(a,k)=((a*k) MOD 256) + ((a*k)/256) |
где a байт открытого текста, и k некоторые ключевые 8 битов в длине. Это - чрезвычайно слабый шифр, начиная с функции f позволяет Вам легко определять один ключ от другого, но это иллюстративно из фундаментального понятия.
Выбрать k1 быть 8 и k2 быть 32. Таким образом для a=73, (a * 8)=584. Это берет два байта, поэтому добавьте биты в высоком байте к битам младшего байта, и Вы добираетесь 74. Повторите этот процесс с 32. Это дает Вам 2368. Снова, добавьте биты от высокого байта до битов младшего байта, и Вы имеете 73 снова.
Это математическое понятие (с совсем другими функциями), когда помещено в практическое применение, известно как криптография с открытым ключом (PK) и формирует основание для шифрования DSA и RSA.
Слабые места с открытым ключом
Шифрование с открытым ключом может быть очень мощным, когда используется должным образом. Однако это имеет много свойственных слабых мест. Полное объяснение этих слабых мест выходит за рамки этого документа. Однако важно, чтобы Вы поняли эти слабые места на высоком уровне, чтобы избежать попадать в некоторые общие прерывания. Некоторая обычно упоминаемая слабость шифрования с открытым ключом включает:
Доверительные модели
Обычно обсужденная слабость шифрования с открытым ключом является самим начальным ключевым обменным процессом. Если кто-то управляет прервать ключ во время начального обмена, он или она мог бы вместо этого дать Вам его или ее собственный открытый ключ и прервать сообщения, идущие к намеченной стороне. Это известно как атака «человек посередине».
Для таких служб как ssh, большинство людей или вручную копирует ключи от одного сервера до другого или просто предполагает, что начальный ключевой обмен был успешен. В большинстве целей это достаточно.
В особенно чувствительных ситуациях, однако, это не достаточно хорошо. Поэтому существует процедура, известная как ключевое подписание. Существует две базовых модели для ключевого подписания: модель центральной власти и сеть доверительной модели.
Модель центральной власти является прямой. Центральное агентство по сертификации подписывает данный ключ и говорит, что они полагают, что владелец ключа - то, кем он или она утверждает, что был. Если Вы полагаете полномочия, то по ассоциации, доверию ключам, что требования полномочий допустимы.
Сеть доверительной модели несколько отличается. Вместо центральной власти, частные лица подписывают ключи, принадлежащие другим частным лицам. Путем подписания чьего-то ключа Вы говорите, что полагаете, что лицо действительно, кем он или она утверждает, что был и что Вы полагаете, что ключ действительно принадлежит ему или ей. Методы, которые Вы используете для определения, что доверие в конечном счете повлияет, доверяют ли другие Вашим подписям, чтобы быть допустимыми.
Существует много различных способов определить доверие, и таким образом у многих групп есть свои собственные правила для того, кто должен и не должен подписывать чей-либо ключ. Те правила предназначаются, чтобы заставить доверительный уровень ключа зависеть на доверительном уровне ключей, подписавших его.
Строка между центральными властями и сетью доверительных моделей не совсем так ясна, как Вы могли бы думать, как бы то ни было. Много центральных властей являются иерархиями полномочий, и в некоторых случаях, они - фактически сети доверия среди многократных полномочий. Аналогично, много сетей доверия могут включать централизованные репозитории для ключей. В то время как те репозитории не обеспечивают сертификации о ключах, они действительно обеспечивают централизованный доступ. Наконец, централизованные полномочия могут легко подписать ключи как часть сети доверия.
Существует много веб-сайтов, описывающих сети доверительных и централизованных систем сертификации. Хорошее общее описание нескольких таких моделей может быть найдено в http://world .std.com/~cme/html/web.html.
Чувствительность к образцам и коротким сообщениям
Существующие алгоритмы шифрования с открытым ключом выполняют хорошую работу при шифровании полуслучайных данных. Они терпят неудачу при шифровании данных с определенными образцами, поскольку эти образцы могут непреднамеренно показать информацию о ключах. Определенные образцы зависят от схемы шифрования. Непреднамеренно удар такого образца не позволяет Вам определять закрытый ключ. Однако они могут сократить пространство поиска, должен был декодировать данное сообщение.
Короткая слабость данных тесно связана с чувствительностью образца. Если информация, которую Вы шифруете, состоит из единственного числа, например номер 1, Вы в основном получаете значение, которое тесно связано математически с открытым ключом. Если намерение состоит в том, чтобы удостовериться, что только кто-то с закрытым ключом может получить исходное значение, у Вас есть проблема.
Другими словами, схемы шифрования с открытым ключом обычно не шифруют все образцы одинаково хорошо. Поэтому (и потому что шифрование с открытым ключом имеет тенденцию быть медленнее, чем единственная ключевая криптография), открытые ключи почти никогда не используются для шифрования данных конечного пользователя. Вместо этого они используются для шифрования сеансового ключа. Этот сеансовый ключ тогда используется для шифрования фактических данных с помощью совместно используемого секретного механизма такой в качестве 3DES, AES, шифр, и т.д.
Используя открытые ключи для обмена сообщениями
Шифрование с открытым ключом может использоваться во многих отношениях. Когда оба ключа являются частными, это может использоваться для отправки данных назад и вперед. Однако, это использование не более полезно, чем совместно используемый секретный механизм. Фактически, это часто более слабо по причинам, упомянутым ранее в главе. Когда один ключ обнародован, шифрование с открытым ключом становится мощным.
Предположите, что Эрни и Берт хотят отправить кодированные сообщения. Эрни дает Берту свой открытый ключ. Предположение, что ключ не был прерван и заменен чьим-либо ключом, Берт, может теперь отправить данные Эрни надежно, потому что данные, зашифрованные с открытым ключом, могут только быть дешифрованы с закрытым ключом (который только Эрни имеет).
Берт использует этот механизм для отправки совместно используемого секрета. Берт и Эрни могут теперь связаться друг с другом использующим совместно используемый секретный механизм, уверенный в знании, что никакое третье лицо не прервало тот секрет. Поочередно, Берт мог дать Эрни свой открытый ключ, и они могли оба зашифровать данные с помощью открытых ключей друг друга, или более обычно при помощи тех открытых ключей для шифрования сеансового ключа и шифруя данные с тем сеансовым ключом.
Используя открытые ключи для проверки идентификационных данных
Шифрование с открытым ключом может также использоваться для проверки идентификационных данных. Кайл хочет знать, является ли кто-то в Интернете, кто утверждает, что был Стэном, действительно Стэном. Несколькими месяцами ранее Стэн вручил Кайлу свой открытый ключ на гибком диске. Таким образом, так как у Кайла уже есть открытый ключ Стэна (и доверяет источнику того ключа), он может теперь легко проверить идентификационные данные Стэна.
Для достижения этого Кайл отправляет сообщение открытого текста и просит, чтобы Стэн зашифровал его. Стэн шифрует его со своим закрытым ключом. Кайл тогда использует открытый ключ Стэна для декодирования шифрованного текста. Если получающийся открытый текст соответствует, то лицом на другом конце должен быть Стэн (если у кого-то еще нет закрытого ключа Стэна).
Используя открытые ключи для проверки целостности данных
Наконец, шифрование с открытым ключом может использоваться для подписания. Ахмед отвечает за встречи тайного общества, названного клубом Stupid Acronym Preventionists. Абрахам является участником клуба и получает файл TIFF, содержащий уведомление об их следующей встрече, переданной посредством такого же участника научного клуба, Альберта. Абрахам обеспокоен, однако, что уведомление, возможно, прибыло из Bubba, пытающегося пропитать SAPs.
Ахмед, однако, был одним шагом вперед, и взял контрольную сумму исходного сообщения и зашифровал контрольную сумму с его закрытым ключом и отправил зашифрованную контрольную сумму как присоединение. Абрахам использовал открытый ключ Ахмеда для дешифрования контрольной суммы и нашел, что контрольная сумма не соответствовала контрольную сумму фактического документа. Он мудро избежал встречи. Айзек, однако, был обманут в раскрытие себя как SAP, потому что он не не забывал проверять подпись на сообщении.
Мораль этой истории? Нужно всегда остерегаться фанатов, совместно использующих TIFFs — т.е. если безопасность некоторой части данных важна и если у Вас нет прямого, безопасного средства сообщения между двумя приложениями, компьютерами, людьми, и т.д., необходимо проверить подлинность любой коммуникации с помощью подписей, ключей или некоторого другого похожего метода. Это может сохранить Ваши данные и также спасти репутацию.
Сводка шифрования
Если начальный ключевой обмен происходит безопасным способом, шифрование является мощным методом для хранения данных, безопасных. Каждый имеет в виду для этого, должен иметь открытый ключ, сохраненный в известном (и доверял), расположение. Это допускает одностороннюю зашифрованную коммуникацию, через которую совместно используемый секрет может быть передан для более поздней двухсторонней зашифрованной коммуникации.
Можно использовать шифрование не только для защиты данных, но также и для проверки подлинности данных путем шифрования контрольной суммы. Можно также использовать его для проверки идентификационных данных клиента путем требования, чтобы клиент зашифровал некоторую случайную часть данных как доказательство, что клиент содержит надлежащий ключ шифрования.
Шифрование, однако, не является заключительным словом в компьютерной безопасности. Поскольку это зависит от наличия некоторой формы доверяемой ключевой обменной, дополнительной инфраструктуры, необходим для достижения общей безопасности в средах, где коммуникация может быть прервана и изменена.
Консольная отладка
В традиционном UNIX и подобных UNIX системах, консоль принадлежит корню. Только корень видит консольные сообщения. Поэтому операторы печати в ядре относительно безопасны.
В OS X любой пользователь может выполнить Консольное приложение. Это представляет основное отбытие от других подобных UNIX систем. В то время как это никогда не хорошая идея включать уязвимую информацию в отладочные операторы ядра, особенно важно не сделать так в OS X. Необходимо предположить, что любые информации, выведенные на экран к консоли, могли потенциально быть считаны любым пользователем в системе (так как консоль виртуализируется в форме просматриваемого пользователем окна).
Печать любой информации, включающей уязвимые данные, включая его расположение на диске или в памяти, представляет дыру в системе безопасности, однако небольшую, и необходимо записать код соответственно. Очевидно, это представляет меньше интереса, если та информация только распечатана, когда пользователь устанавливает флаг отладки где-нибудь, но для нормальной эксплуатации, распечатыванию потенциально частной информации к консоли строго обескураживают.
Необходимо также бояться непреднамеренно распечатывать информацию, которую Вы используете для генерации хэшей пароля, или ключи шифрования, такие как значения семени передали генератору случайных чисел.
Это, при необходимости, не полный список информации, чтобы избежать распечатывать к консоли. Необходимо использовать собственное решение при решении, могли ли бы данные быть ценными, если замечено третьим лицом, и затем решать, является ли надлежащим распечатать его к консоли.
Передача кода
Существует много способов передать исполняемый код в ядро от пространства пользователя. В целях этого раздела исполняемый код не ограничивается скомпилированным объектным кодом. Это включает любые инструкции, переданные в ядро, это значительно влияет на поток управления. Примеры переданных - в исполняемом коде колеблются от простых правил, таких как код фильтрации, загруженный во многих проектах брандмауэра на загрузки байт-кода для платы SCSI.
Если возможно выполнить Ваш код в пространстве пользователя, Вы даже не должны собираться продвигать код в ядро. Для редкого случая, где никакое другое разумное решение не существует, однако, Вы, возможно, должны передать некоторую форму исполняемого кода в ядро. Этот раздел объясняет некоторые разветвления безопасности продвижения кода в ядро, и уровень проверки должен был гарантировать непротиворечивую работу.
Вот некоторые инструкции для минимизации потенциала для дыр в системе безопасности:
Никакой необработанный объектный код.
Прямое выполнение кода, переданного в от пространства пользователя, очень опасно. Интерпретируемые языки являются единственным разумным решением для этого вида проблемы, и даже это чревато трудностью. Традиционный машинный код не может быть проверен достаточно для обеспечения соответствия безопасности.
Проверка границ.
Так как Вы находитесь в ядре, Вы ответственны за проверку, что любой загруженный код случайным образом не получает доступ к памяти и не пытается сделать прямой доступ к оборудованию. Вы обычно делали бы это функцией самого языка, ограничивая доступ к элементу данных, на который воздействует байт-код.
Проверка завершения.
С очень, очень немного исключений, выбранный язык должен быть ограничен для кодирования, который может быть проверен для завершения, и необходимо проверить соответственно. Если Ваш драйвер застревает в плотно прокрученном цикле, это, вероятно, неспособно выполнить свою работу и может повлиять на полную производительность системы в процессе. Язык, не позволяющий (неограниченные) циклы (например, позволяя
forно нетwhileилиgotoмог быть один способ гарантировать завершение.Проверка законности.
Ваш интерпретатор байт-кода был бы ответственен за проверку вперед любые потенциально недопустимые операции и принятие надлежащих карательных мер против загруженного кода. Например, если загруженному коду позволяют сделать математику, то надлежащая защита должна существовать для обработки, делятся на нулевые ошибки.
Проверка здравомыслия.
Необходимо проверить, что вывод является чем-то удаленно разумным, если это возможно. Не всегда возможно проверить, что вывод корректен, но обычно возможно создать правила, предотвращающие в высшей степени недопустимый вывод.
Например, сетевое правило фильтра должно вывести что-то напоминающее пакеты. Если контрольные суммы плохи, или если другая информация отсутствует или повреждение, ясно загруженный код является дефектным, и соответствующие меры должны быть приняты. Было бы очень неуместно для OS X отослать плохой сетевой трафик.
В целом, чем более строгий набор языка, тем ниже угроза безопасности. Например, интерпретация простых политик сетевой маршрутизации, менее вероятно, будет проблемой безопасности, чем интерпретация пакетных правил перезаписи, который, менее вероятно, будет проблемой, чем выполнение Байт-кода Java в ядре. Как с чем-либо еще, необходимо тщательно взвесить потенциальные выгоды против потенциальных недостатков и принять лучшее решение, данное доступную информацию.