Управление данными
Водительская существенная работа должна переставить данные в и из системы в ответ на клиентские запросы, а также события, такие как сгенерированные аппаратными средствами прерывания. Набор I/O определяет стандартные механизмы для драйверов, чтобы сделать это использование ряда классов. Драйверы используют классы IOMemoryDescriptor и IOMemoryCursor (и, в OS X v10.4.7 и позже, класс IODMACommand) для выполнения pre-I/O и post-I/O, обрабатывающего на буферах данных, таких как перевод их между клиентскими форматами и специфичными для аппаратных средств форматами. В этой главе рассматриваются эти классы и различные проблемы, связанные с драйверами устройств и управлением данными.
Драйверы обрабатывают клиентские запросы и другие события с помощью классов IOWorkLoop и IOEventSource, чтобы сериализировать доступ и таким образом защитить их критические данные. Из-за этих механизмов драйверы редко должны волноваться о таких проблемах как защита критических данных или прерываний отключения и включения во время нормального хода обрабатывания запроса. См., что глава Обрабатывает События для получения информации.
Обработка Передач I/O
Передача I/O немного больше, чем перемещение данных между одним или более буферами в системной памяти и устройстве. «Системная память» в этом контексте, однако, относится к фактической физической памяти, не адресному пространству виртуальной памяти, используемому и пользователем и задачами ядра в OS X. Поскольку передачи I/O на уровне драйверов устройств чувствительны к ограничениям аппаратных средств, и аппаратные средства могут «видеть» только физическую память, они требуют специального режима.
Операции ввода-вывода в OS X происходят в контексте системы виртуальной памяти с приоритетным планированием задач и потоков. В этом контексте буфер данных со стабильным виртуальным адресом может быть расположен где угодно в физической памяти, и что расположение физической памяти может измениться, поскольку виртуальная память разбита на страницы в и. Для того буфера данных возможно не быть в физической памяти вообще в любой момент времени. К даже памяти ядра, не подвергающейся перемещению, получает доступ CPU в виртуальном адресном пространстве.
Для операции записи, где данные в системе отсылаются, буфер данных должен быть разбит на страницы в при необходимости от хранилища виртуальной памяти. Для операции чтения, где буфер будет заполнен данными, принесенными в систему, существующее содержание буфера данных не важно, таким образом, никакая страница - в не необходима; новая страница просто выделяется в физической памяти, с предыдущим содержанием той перезаписываемой страницы (после того, чтобы быть разбитым на страницы, если необходимый).
Все же требование для передач I/O - то, что данные в системной памяти не перемещены во время продолжительности передачи. Чтобы гарантировать, что устройство может получить доступ к данным в буферах, буферы должны быть резидентным объектом в физической памяти и должны быть соединены проводом вниз так, чтобы они не становились разбитыми на страницы или перемещенными. Тогда физические адреса буферов должны быть сделаны доступными для устройства. После того, как устройство закончено с буферами, они должны быть неподключенными так, чтобы они могли еще раз быть разбиты на страницы системой виртуальной памяти.
Чтобы помочь Вам иметь дело с этими и другими ограничениями аппаратных средств, I/O, Кит помещает несколько классов в вашем распоряжении.
Дескрипторы памяти и курсоры памяти
В операционной системе вытесняющей многозадачности со встроенной виртуальной памятью передачи I/O требуют специальной обработки подготовки и постзавершения:
Пространство, необходимое для передачи I/O, должно находиться в физической памяти и должно быть соединено проводом вниз, таким образом, это не может быть разбито на страницы, пока передача не завершается.
Адреса виртуальной памяти, используемые программным обеспечением, должны быть преобразованы в физические адреса, и буферные адреса и длины должны быть собраны в рассеиваться/собирать списки, описывающие данные, которые будут переданы.
После того, как передача завершается, память должна быть неподключенной, таким образом, это может быть разбито на страницы.
В Наборе I/O вся эта работа выполняется объектами классов IOMemoryDescriptor и IOMemoryCursor (см. Поддержку DMA на 64-разрядных Архитектурах системы для получения информации о классе IODMACommand, заменяющем IOMemoryCursor в OS X v10.4.7 и позже). Запрос I/O обычно включает объект IOMemoryDescriptor, описывающий области памяти, вовлеченной в передачу. Первоначально, описание принимает форму массива структур, каждый состоящий из идентификатора клиентской задачи (task_t), смещение в виртуальное адресное пространство клиента и длина в байтах. Драйвер использует дескриптор памяти для подготовки страниц памяти — разбивки на страницы их в физическую память, при необходимости, и проводное соединение их вниз — путем вызова дескриптора prepare функция.
Когда память подготовлена, драйвер на более низком уровне штабеля — обычно драйвер, управляющий DMA (Прямой доступ к памяти), механизм — тогда использует объект курсора памяти получить буферные сегменты дескриптора памяти, и с ними генерируют рассеиваться/собирать список, подходящий для использования с аппаратными средствами. Это делает это путем вызова getPhysicalSegments функция курсора памяти и выполнения любой необходимой обработки на сегментах это получает. Когда передача I/O завершена, драйвер, порождающий запрос I/O, вызывает дескриптор памяти complete функционируйте, чтобы не соединить память проводом и обновить состояние виртуальной памяти. Когда все это сделано, это сообщает клиенту завершенного запроса.
Начинаясь в OS X v10.2, IOBufferMemoryDescriptor (подкласс IOMemoryDescriptor) позволяет буферу быть выделенным в любой задаче для I/O или совместного использования посредством отображения. В предыдущих версиях OS X объект IOBufferMemoryDescriptor мог только представлять буфер, выделенный в адресном пространстве ядра. В OS X v10.2 и позже, однако, изменения в IOBufferMemoryDescriptor API поддерживают лучший способ обработать I/O, сгенерированный по воле клиента неядра. Apple рекомендует, чтобы такой I/O был отправлен в буферы, которые ядро выделяет в адресном пространстве клиента с помощью IOBufferMemoryDescriptor API. Это дает контроль метода назначения для ядра, гарантируя, что буфер выделяется в соответствии с внутренними инструкциями, продиктованными системой виртуальной памяти. Пользовательская задача может все еще указать вид буфера, который будет выделен, такой как листаемая или с обеспечением совместного доступа. И, пользовательская задача может все еще получить доступ к буферу с помощью vm_address_t и vm_size_t переменные это получает от пользовательского клиента. Для программного обеспечения, работающего в OS X v10.2 и позже, Apple рекомендует что:
Пользовательские задачи больше не используют
mallocили другие библиотечные функции пользовательского уровня для выделения буферов I/O в их собственном адресном пространстве.Пользовательские клиенты используют объекты IOBufferMemoryDescriptor представлять выделенные ядру буферы вместо объектов IOMemoryDescriptor что представленный пользователь выделенные задаче буферы.
Сетевые драйверы являются исключением к использованию объектов IOMemoryDescriptor. Семья Network вместо этого использует mbuf структура определяется сетевыми стеками ядра BSD. BSD mbuf структуры уже оптимизированы для обработки сетевых пакетов, и перевод между ними и дескрипторами памяти просто представил бы ненужные издержки. Сетевая семья определяет подклассы IOMemoryCursor для извлечения, рассеиваются/собирают списки непосредственно от mbuf структуры, по существу делая этот аспект I/O, обрабатывающего то же для сетевых драйверов что касается любого другого вида драйвера.
IOMemoryDescriptor и IOMemoryCursor способны к обработке управления и повторного использования буферов памяти для большинства драйверов. Драйверы с особыми требованиями, такими как та вся буферная память быть непрерывным или расположенным в определенной области в физической памяти, должен выполнить дополнительную работу, необходимую, чтобы удовлетворить эти требования, но все еще использовать дескрипторы памяти и курсоры для их взаимодействия с Набором I/O.
Память в Запросе I/O
Несмотря на то, что предыдущий раздел обсуждает, как драйверы Набора I/O передают данные между устройством и системной памятью при помощи объектов классов IOMemoryDescriptor и IOMemoryCursor, это делает так на довольно общем уровне. Это также поучительно для рассмотрения запроса I/O на более подробном уровне: Что происходит с момента, которому пользовательский процесс звонит, чтобы записать или считать данные в момент, данные передаются или от устройства? Что точные роли играют IOMemoryDescriptors, IOMemoryCursors и другие объекты Набора I/O в этой цепи событий?
Все операции чтения и операции записи в пространстве пользователя — т.е. сделанный приложениями или другими процессами неядра — базируются в конечном счете на векторах I/O. Вектор I/O является массивом структур, каждая из которых дает адрес и длину непрерывного блока памяти определенного процесса; эта память выражена в виртуальном адресном пространстве процесса. Вектор I/O иногда известен как рассеиваться/собирать список.
Для запуска с более определенного примера процесс звонит для записи некоторых данных в устройство. Это должно передать в минимальном наборе параметров: дескриптор к цели вызова (io_service_t), команда («запись»), базовый адрес векторного массива I/O и число элементов матрицы. Эти параметры передаются к ядру. Но как ядро для понимания их, особенно базовый адрес массива, вводящегося как void *. Жизни ядра в его собственном виртуальном адресном пространстве и виртуальном адресном пространстве пользовательского процесса, непереведенного, ничего не значат для него.
Прежде, чем идти далее, давайте рассмотрим карты распределения памяти, сохраняемые операционной системой. В OS X существует три различных видов адресного пространства:
Виртуальное адресное пространство процессов отдельного пользователя (таких как приложения и демоны)
Виртуальное адресное пространство ядра (который включает Набор I/O),
Когда пользовательский процесс издает приказ I/O, вызов (с его параметрами) проникает вниз к ядру. Там Набор I/O преобразовывает параметр дескриптора в объект, полученный из надлежащего подкласса IOUserClient. Пользовательский объект клиента логически сидит верхом на границе, разделяющей ядро и пространство пользователя. Существует один пользовательский клиент на пользовательский процесс для каждого устройства. С точки зрения ядра пользовательский клиент является клиентским драйвером наверху штабеля, связывающегося с объектом куска ниже его (см. рисунок 8-1).
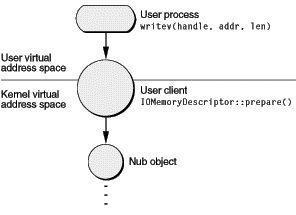
Пользовательский клиент также переводит между адресными пространствами, отображая буферы пользовательского процесса в виртуальное адресное пространство ядра. Чтобы сделать это, это создает объект IOMemoryDescriptor из других параметров, указанных в первоначальном вызове. Определенное питание объекта IOMemoryDescriptor состоит в том, что он может описать часть памяти в течение ее использования в операции I/O и в каждом из адресных пространств системы. Это может быть передано между различными драйверами вверх и вниз по штабелю драйвера, дав каждому драйверу возможность совершенствовать или управлять командой. Драйвер может также снова использовать дескриптор памяти; при некоторых обстоятельствах лучше — если непрерывное выделение собирается включить хит производительности — чтобы создать пул IOMemoryDescriptors заранее и переработать их.
После того, как пользовательский клиент создает (или повторные использования) объект IOMemoryDescriptor, он сразу вызывает дескриптор памяти prepare функция членства. prepare вызов сначала удостоверяется, что физическая память доступна для передачи I/O. Поскольку это - операция записи, системе виртуальной памяти, вероятно, придется разбить на страницы в данных от его хранилища. Если это была операция чтения, пейджеру виртуальной памяти (VM), возможно, придется выгрузить некоторые другие страницы от физической памяти для создания места для передачи I/O. Или в случае, когда пейджер VM вовлечен в подготовку физической памяти, существуют импликации для драйверов контроллера шины, что программа, механизмы DMA или иначе должны иметь дело непосредственно с требованиями устройств (см. DMA и Системную память). После того, как достаточная физическая память защищается для передачи I/O, prepare функционируйте соединяет память проводом вниз, таким образом, она не может быть разбита на страницы.
prepare вызов должен быть выполнен, прежде чем команда I/O пересекается формально в Набор I/O, и это должно также быть сделано на потоке клиента запроса и прежде, чем взять любые блокировки. Никогда не вызывайте prepare в контексте логического элемента команды, потому что prepare синхронный вызов и может блокировать (т.е. ожидать некоторого другого процесса для завершения), неопределенно. Когда prepare возвраты, пользовательский клиент (обычно) инициирует вызов для планирования запроса I/O, передавая дескриптор памяти драйверу вниз штабель (через установленные интерфейсы, как описано в Передаче Запросов I/O). Дескриптор памяти мог бы быть передан другим драйверам, каждый из которых мог бы управлять своим содержанием, пока это в конечном счете не достигает объекта, который является близко к самим аппаратным средствам — обычно драйвер контроллера шины или что водительский клиентский кусок. Этот объект планирует запрос I/O и принимает управление (см. Запросы I/O и Логические элементы Команды для получения информации о логических элементах команды). В команде пропускают его, обычно стоит в очереди запрос на обработку, как только аппаратные средства свободны.
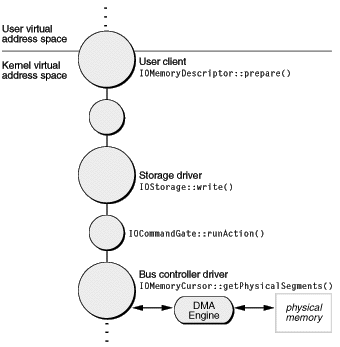
В конечном счете получение запроса на более низких уровнях штабеля драйвера является драйвером контроллера шины (такой что касается ATA или SCSI). Этот объект драйвера низшего уровня должен программировать механизм DMA контроллера или иначе создать рассеиваться/собирать список для перемещения данных непосредственно в и из устройства. Используя объект IOMemoryCursor, этот драйвер генерирует физические адреса и длины от буферных сегментов дескриптора памяти и выполняет любую другую работу, необходимую для создания рассеиваться/собирать списка с выравниванием, форматом порядка байтов и факторами размера, требуемыми аппаратными средствами. Для генерации сегментов это должно вызвать getPhysicalSegments функция курсора памяти. Эта целая процедура выполняется в контексте цикла работы. При завершении передачи аппаратное прерывание обычно сгенерировано для инициирования передачи I/O в другом направлении.
Когда передача I/O завершена, вызвавший объект prepare вызывает дескриптор памяти complete функционируйте, чтобы не соединить память проводом и обновить состояние виртуальной памяти. Важно сбалансировать каждого prepare с соответствием complete. Когда все это сделано, пользовательский клиент сообщает инициирующему процессу завершенного запроса.
Проблемы с 64-разрядными архитектурами системы
Начав с OS X v10.3 и позже, Apple представил некоторые изменения, чтобы позволить существующим драйверам устройств работать с новыми 64-разрядными архитектурами системы. Проблема, которая будет решена включенный коммуникация между устройствами на шине PCI, которая может обработать 32-разрядные адреса и 64-разрядную оперативную память.
Затем в OS X v10.4.7, Apple представил IODMACommand класс для разрешения драйверов устройств, выполняющих DMA для обращения 64-разрядной оперативной памяти в основанных на Intel компьютерах Macintosh. Следующие разделы описывают эти изменения.
Преобразование адресов на 64-разрядных архитектурах системы
Apple решил проблему с преобразованием адресов, «отображающим» блоки памяти в 32-разрядное адресное пространство устройства PCI. В этой схеме устройство PCI все еще видит пространство на 4 гигабайта, но то пространство может быть составлено из блоков состоящих из нескольких несмежных участков памяти. Часть контроллера памяти вызвала DART (таблица разрешения адреса устройства) переводит между адресным пространством PCI и намного большим адресным пространством оперативной памяти. DART обрабатывает это путем хранения таблицы переводов для использования при отображении между физическими адресами, которые процессор видит и адреса, которые устройство PCI видит (названный адресами I/O).
Если Ваш драйвер придерживается задокументированного, предоставленного Apple APIS, процесс преобразования адресов прозрачен. Например, когда Ваш драйвер вызывает метод IOMemoryDescriptor prepare, отображение автоматически помещается в DART. С другой стороны, когда Ваш драйвер вызывает IOMemoryDescriptor release метод, отображение удалено. Несмотря на то, что это всегда было рекомендуемой процедурой, отказ сделать это в драйвере, работающем на OS X v10.3, или позже может привести к случайному повреждению данных или панике. Знайте что release метод не занимает место complete метод. Как всегда, каждый вызов prepare должен быть сбалансирован с вызова complete.
Если Ваш драйвер испытывает трудность на OS X v10.3 система, необходимо сначала гарантировать, что Вы следуете этим инструкциям:
Всегда вызывайте
IOMemoryDescriptor::prepareподготавливать физическую память к передаче I/O (это также помещает отображение в DART).Сбалансируйте каждого
IOMemoryDescriptor::prepareсIOMemoryDescriptor::completeне соединять память проводом.Всегда вызывайте
IOMemoryDescriptor::releaseудалить отображение из DART.На аппаратных средствах, включающих DART, обратите внимание на направление DMA для чтений и записей. В 64-разрядной системе драйвер, пытающийся записать в область памяти, направление DMA которой устанавливается для чтения, вызовет панику ядра.
Один побочный эффект этих изменений в подсистеме памяти состоит в том, что OS X, вероятно, возвратит физически непрерывные диапазоны страницы в областях памяти. В более ранних версиях OS X система возвратила многостраничные области памяти в обратном порядке, начавшись с последней страницы и двинув первую страницу. Из-за этого многостраничная область памяти редко содержала физически непрерывный диапазон страниц.
Значительно увеличенная вероятность наблюдения физически непрерывных блоков памяти в областях памяти могла бы представить скрытые ошибки в драйверах, которые не должны были ранее обрабатывать физически непрерывные страницы. Обязательно проверьте на эту возможность, если Ваш драйвер ведет себя неправильно или паникует.
Другой результат изменений подсистемы памяти касается физических адресов, которые драйвер мог бы получить непосредственно из pmap уровня. Поскольку нет взаимно-однозначного соответствия между физическими адресами и адресами I/O, физические адреса, полученные из pmap уровня, не имеют никакой цели вне самой системы виртуальной памяти. Драйверы, использующие вызовы pmap (такой как pmap_extract) получить такие адреса не будет работать над системами с DART. Для предотвращения использования этих вызовов OS X v10.3 откажется загружать расширение ядра, использующее их, даже в системах без DART.
Поддержка DMA на 64-разрядных архитектурах системы
Как описано в Преобразовании адресов на 64-разрядных драйверах Архитектур системы, работающих в OS X v10.3 и позже что использование задокументированный, предоставленный Apple APIs испытывает немногих (если таковые имеются) проблемы при обращении физической памяти в 64-разрядных системах, потому что преобразование адресов, выполняемое DART, очевидно для них. Однако текущие основанные на Intel компьютеры Macintosh не включают DART, и это имеет разветвления для драйверов устройств, которые должны использовать физические адреса, такие как те, которые выполняют DMA.
Поскольку нет никакого поддерживаемого аппаратными средствами преобразования адресов или переотображения, выполняемого в текущих основанных на Intel компьютерах Macintosh, драйверы устройств, которые должны получить доступ к физической памяти, должны быть в состоянии адресовать память выше 4 гигабайтов. В OS X v10.4.7 и выше, можно использовать класс IODMACommand, чтобы сделать это.
IODMACommand класс заменяет класс IOMemoryCursor: это обеспечивает всю функциональность IOMemoryCursor и добавляет способ для Вас указать возможность обращения Ваших аппаратных средств, и функции для копирования памяти в возврат буферизуют при необходимости. При инстанцировании объекта IODMACommand можно указать следующие атрибуты:
Число адресных битов Ваши аппаратные средства может поддерживать (например, 32, 40, или 64)
Максимальный размер сегмента
Любые ограничения выравнивания требуются Вашими аппаратными средствами
Максимальный I/O передает размер
Формат возвратов сегментов IODMACommand физического адреса (например, 32-разрядный или 64-разрядный и с обратным порядком байтов, с прямым порядком байтов, или порядок байтов узла)
В типичном случае Вы используете объект IODMACommand следующим образом:
Создайте объект IODMACommand на транзакцию I/O (можно создать пул объектов IODMACommand, когда драйвер запускается).
Когда запрос I/O поступит, использовать
IODMACommand::setMemoryDescriptorпредназначаться для объекта IOMemoryDescriptor представление запроса.Вызвать
IODMACommand::prepare(среди прочего эта функция выделяет отображающиеся ресурсы, которые могут требоваться для передачи).Используйте функции IODMACommand для генерации надлежащих физических адресов и длин (
IODMACommand::gen64IOVMSegmentsвозвращает 64-разрядные адреса и длины иIODMACommand::gen32IOVMSegmentsвозвращает 32-разрядные адреса и длины).Запустите аппаратные средства I/O.
Когда I/O будет закончен, вызвать
IODMACommand::complete(для завершения обработки отображений DMA), сопровождаемыйIODMACommand::clearMemoryDescriptor(чтобы скопировать данные с буфера возврата, при необходимости, и высвободить средства).
Если Ваш механизм DMA делает сложные вещи, такие как выполнение частичного I/Os или синхронизация множественных доступов к единственному IOMemoryDescriptor, необходимо записать драйвер, предполагающий, что будет возвращена память. Вы не должны добавлять код, проверяющий на возврат, потому что IODMACommand функционирует, такой как synchronize, без операций в секунду, когда они являются ненужными.
Передача Запросов I/O
Клиентские запросы поставлены драйверам через определенные функции, определяемые водительской семьей. Драйвер семейства систем хранения, например, обрабатывает запросы чтения путем реализации функции read. Точно так же сетевой драйвер семьи обрабатывает запросы для передачи сетевых пакетов путем реализации функции outputPacket.
Запрос I/O всегда включает буферное, содержащее данные для записи или обеспечивающий пространство для данных, которые будут считаны. В Наборе I/O этот буфер принимает форму объекта IOMemoryDescriptor для всех семей кроме сетей, использующих mbuf структура определяется BSD для сетевых пакетов. Эти два буферных механизма предоставляют всем драйверам оптимизированное управление буферами данных вверх и вниз по штабелям драйвера, минимизируя копирование данных и выполнение всех шагов, требуемых подготавливать и завершать буферы для операций I/O.
Семья I/O Kit определяет I/O и другие интерфейсы запроса. Вы обычно не должны волноваться о защите ресурсов в повторно используемом контексте для Вашего драйвера, если это в частности не воздерживается от защиты, предлагаемой семьей или Набором I/O обычно.
Больше на дескрипторах памяти
Дескриптор памяти является объектом, наследовавшимся от класса IOMemoryDescriptor, описывающего, как поток данных, в зависимости от направления, должен или быть положен в память или извлечен из памяти. Это представляет сегмент памяти, содержащей данные, вовлеченные в передачу I/O, и указано как один или несколько диапазонов физических адресов или диапазоны виртуальных адресов (диапазон, являющийся начальным адресом и длиной в байтах).
IOMemoryDescriptor возражает объектам разрешений на различных уровнях штабеля драйвера для обращения к той же части данных, как отображено в физическую память, виртуальное адресное пространство ядра или виртуальное адресное пространство пользовательского процесса. Дескриптор памяти обеспечивает функции, которые могут перевести между различными адресными пространствами. В некотором смысле это инкапсулирует различные отображения в течение жизни некоторой части данных, вовлеченных в передачу I/O.
IOMemoryDescriptor является абстрактным базовым классом, определяющим общие методы для описания физической памяти или виртуальной памяти. Несмотря на то, что это - абстрактный класс, Набор I/O обеспечивает конкретную реализацию общего назначения IOMemoryDescriptor для объектов, которые непосредственно инстанцируют от класса. Набор I/O также обеспечивает два специализированных общедоступных подкласса IOMemoryDescriptor: IOMultiMemoryDescriptor и IOSubMemoryDescriptor. Таблица 8-1 описывает эти классы.
Класс | Описание |
|---|---|
Обертки многократные дескрипторы памяти общего назначения в единственный дескриптор памяти. Это обычно делается для приспосабливания протоколу шины. | |
Представляет область памяти, прибывающую из определенного поддиапазона некоторого другого IOMemoryDescriptor. |
Сам базовый класс IOMemoryDescriptor определяет несколько методов, которые могут быть полезно вызваны от объектов всех подклассов. Некоторые методы возвращают физически непрерывные сегменты памяти дескриптора (для использования с объектом IOMemoryCursor), и другие методы отображают память в любое адресное пространство с кэшированием и помещенный отображенными опциями.
Связанным и обычно полезным классом является IOMemoryMap. Когда Вы вызываете IOMemoryDescriptor’s map метод для отображения дескриптора памяти в определенном адресном пространстве объект IOMemoryMap возвращается. Объекты класса IOMemoryMap представляют отображенный диапазон памяти, как описано IOMemoryDescriptor. Отображение может быть в ядре или задаче неядра, или это может быть в физической памяти. Отображение может иметь различные атрибуты, включая режим кэширования процессора.
Больше на курсорах памяти
IOMemoryCursor размечает буферные диапазоны в объекте IOMemoryDescriptor в физической памяти. Путем надлежащей инициализации курсора памяти и затем вызова, что объект getPhysicalSegments функция на IOMemoryDescriptor, драйвер может создать рассеиваться/собирать список, подходящий для определенного устройства или механизма DMA. Генерация рассеиваться/собирать списка может быть сделана удовлетворить требования длины сегмента, продолжительность передачи, формат порядка байтов и выравнивание, наложенное аппаратными средствами.
Драйвер контроллера для шины, такой как USB, ATA или FireWire обычно является объектом, использующим IOMemoryCursors. Такие драйверы должны создать IOMemoryCursor и сконфигурировать курсор памяти к ограничениям водительских аппаратных средств DMA или (если PIO используется вместо этого), ограничения самого устройства. Например, курсор памяти, используемый для протокола FireWire SBP-2, должен быть сконфигурирован к максимальному физическому размеру сегмента 65 535 и неограниченному размеру передачи.
Можно сконфигурировать IOMemoryCursor во множестве путей. Самый очевидный путь состоит в том, чтобы предоставить параметры инициализации: максимальный размер сегмента, максимум передает длину и указатель на функцию сегмента. Эта функция обратного вызова, введенная SegmentFunction, выписывает единственный физический сегмент к элементу в векторном массиве, определяющем рассеиваться/собирать список. Ваш драйвер может также выполнить последующую обработку на извлеченных сегментах, подкачав байты или иначе управляя содержанием сегментов. Наконец, можно создать подкласс IOMemoryCursor или использовать один из подклассов, предоставленных Apple. Посмотрите Подклассы IOMemoryCursor для больше по этой теме.
DMA и системная память
У писателей драйверов контроллера шины есть два основных соображения, когда они производят передачи I/O. Они получают данные, размеченные в памяти определенным способом, и они должны отправить те данные месту назначения, которое могло бы ожидать радикально различное расположение памяти. В зависимости от направления источник и место назначения могут быть или механизмом DMA (или определенным устройством) или клиентская память, представленная IOMemoryDescriptor. Кроме того, память, прибывающая из системы, могла бы быть обусловлена Unified Buffer Cache (UBC), и это имеет импликации для писателей драйвера. В этом разделе рассматриваются некоторые из этих факторов.
Прямой доступ к памяти (DMA) является встроенной возможностью определенных контроллеров шины для того, чтобы непосредственно передать данные между устройством, присоединенным к шине и системной памятью — т.е. физическая память на системной плате компьютера. DMA улучшает производительность системы путем освобождения микропроцессора от необходимости сделать передачу самих данных. В то время как механизм DMA заботится о движущихся данных в и из системы, микропроцессор может работать над другими задачами.
Каждая шина в системе OS X имеет свой собственный механизм DMA, и они все отличаются. Контроллер шины PCI на OS X использует устройство управления шиной DMA, тип DMA в чем, контроллер управляет всеми операциями I/O от имени микропроцессора. Другие контроллеры шины (ATA, SCSI или USB, например) реализуют различные механизмы DMA. Каждый механизм может иметь свое собственное выравнивание, формат порядка байтов и ограничения размера.
Альтернатива DMA является интерфейсом Programmed Input/Output (PIO), обычно находимым на более старом или под - разработанные аппаратные средства. В PIO, все данные, переданные между устройствами и системной памятью, проходит через микропроцессор. PIO медленнее, чем DMA, потому что это использует больше циклов шины для выполнения той же передачи данных.
OS X поддерживает и устройство управления шиной DMA и PIO для движущихся данных в и из системы. Фактически, некоторые драйверы могли очевидно использовать обе модели для той же передачи I/O — например, обработав большинство байтов с помощью DMA и затем обработав последние несколько байтов с помощью PIO, или с помощью PIO для обработки состояний ошибки.
Unified Buffer Cache (UBC) является оптимизацией ядра, комбинирующей кэш файловой системы и кэш виртуальной памяти (VM). UBC устраняет ситуацию, где та же страница дублирована в обоих кэшах. Вместо этого существует всего одно изображение в памяти и указателях на нее и от файловой системы и от системы VM. Глубинной структурой UBC является Universal Page List (UPL). Пейджер VM имеет дело с памятью, как определено UPLs; когда запрос I/O основывается разбитый на страницы - в памяти, его вызывают соответствующим запросом. Не соответствующий запрос является не UPL-определяющимся тем. Сегмент UPL памяти имеет определенные характеристики; это:
Измеренные (4 килобайта) страницы
Выровненная страница
Имеет максимальный размер сегмента 128 килобайтов
Уже отображается в виртуальное адресное пространство ядра
Набор I/O адаптировал свой APIs к модели UPL, потому что это более эффективно для передач I/O; кроме того, это упрощает обрабатывать запросы I/O в пакетном режиме. Объект IOMemoryDescriptor мог бы быть поддержан — полностью или частично — UPL-определенной памятью. Если объект поддерживается UPL, то не может быть больше, чем заранее подготовленное число физических сегментов. Драйвер контроллера шины, извлекающий сегменты (использующий IOMemoryCursor) должен выделить достаточные ресурсы для выпуска запроса I/O, связанного с дескриптором памяти.
Контакт с аппаратными ограничениями
Политика Apple по тому, как драйверы должны иметь дело с аппаратными ограничениями, щедра к клиентам драйверов контроллера DMA и помещает определенные ожидания в сами драйверы.
У клиентов драйверов контроллера DMA нет ограничений выравнивания, установленных для них. Обычно UPL-определенные данные (выровненный страницей и размера страницы) должны быть оптимальными, но они не требуются.
Если память UPL-определяется, то во избежание заведения в тупик драйвера не должен выделять память. Драйверы контроллера должны быть в состоянии обработать UPL, не выделяя буферов, или они должны предварительно выделить достаточные ресурсы до любой определенной основанной на UPL передачи I/O. Операции, не встречающие ограничения пейджера (т.е. которые не основаны на UPL) могут выделить буферы.
Драйвер контроллера должен приложить все усилия для удостаивания любого запроса, который он получает. Если необходимо, это должно даже создать буфер (или даже использовать статический буфер), или предварительно выделите ресурсы и скопируйте данные. (Помните, что выделение во время запроса I/O может вызвать мертвую блокировку.), Если драйвер не может выполнить запрос I/O, он должен возвратить надлежащий ошибочный код результата.
Таким образом, писатели драйвера должны быть подготовлены обработать запрос для любого выравнивания, размера или другого ограничения. Они должны сначала попытаться обработать запрос как соответствующий спецификациям UPL; если предположение о UPL подтверждается, они никогда не должны выделять память, потому что выполнение так могло вести для заведения в тупик. Если запрос является не соответствующим, драйвер должен (и может) делать то, что это должно сделать для удовлетворения запроса, включая выделение ресурсов.
Подклассы IOMemoryCursor
Apple обеспечивает несколько подклассов IOMemoryCursor для различных ситуаций. Если Ваш механизм DMA требует определенного формата данных порядка байтов для своих физических сегментов, Ваш драйвер может использовать подклассы, имеющие дело с форматами данных с прямым порядком байтов и с обратным порядком байтов (и таким образом не должен будет выполнять этот перевод, когда это создает рассеиваться/собирать списки для механизма DMA). Другой подкласс позволяет Вашему драйверу разметить данные в ориентации байта, ожидаемой процессором системы. Таблица 8-2 описывает эти подклассы.
Подкласс | Описание |
|---|---|
Выдержки и размечают рассеиваться/собирать список физических сегментов в естественном порядке байтов для данного CPU. | |
Выдержки и размечают рассеиваться/собирать список физических сегментов, закодированных в формате байта с обратным порядком байтов. Используйте этот курсор памяти, когда механизм DMA потребует адреса с обратным порядком байтов и длины для каждого сегмента. | |
Выдержки и размечают рассеиваться/собирать список физических сегментов, закодированных в формате байта с прямым порядком байтов. Используйте этот курсор памяти, когда механизм DMA потребует адреса с прямым порядком байтов и длины для каждого сегмента. |
Конечно, можно создать собственный подкласс виртуального IOMemoryCursor, или одного из его подклассов для имения курсора памяти выполняют точно, что Вам нужен он, чтобы сделать. Но во многих случаях, Вам не, вероятно, придется создать подкласс для получения поведения, которое Вы ищете. Используя один из предоставленных классов курсора памяти, можно реализовать собственное outputSegment функция обратного вызова (который должен соответствовать SegmentFunction прототип). Эта функция вызвана курсором памяти для выписывания физического сегмента в рассеиваться/собирать списке, подготавливаемом к механизму DMA. В Вашей реализации этой функции можно удовлетворить любые специальные разметки, требуемые аппаратными средствами, такие как границы выравнивания.