Стратегии проектирования приложений OpenGL
OpenGL выполняет много сложных операций — трансформации, освещение, отсечение, текстурирование, воздействие на окружающую среду, и т.д. — на больших наборах данных. Размер Ваших данных и сложность вычислений, выполняемых на нем, могут повлиять на производительность, делая Ваше звездное 3D графическое сияние менее ярко, чем Вы хотели бы. Является ли Ваше приложение игрой с помощью OpenGL для обеспечения иммерсивных изображений в реальном времени для пользователя или приложения для обработки изображений, более заинтересованного качеством изображения, используйте информацию в этой главе, чтобы помочь Вам разработать свое приложение.
Визуализация OpenGL
Наиболее распространенный способ визуализировать OpenGL как графический конвейер, как показано на рисунке 9-1. Ваше приложение отправляет вершину и данные изображения, изменения конфигурации и изменения состояния и команды рендеринга к OpenGL. Вершины обработаны, собраны в примитивы и растеризированы во фрагменты. Каждый фрагмент вычисляется и объединяется в кадровый буфер. Конвейерная модель полезна для идентификации точно, что работает, Ваше приложение должно выполнить для генерации результатов, которые Вы хотите. OpenGL позволяет Вам настраивать каждый этап графического конвейера, или через специализированные программы программы построения теней или путем конфигурирования конвейера стандартных функций посредством вызовов функции OpenGL.
В большинстве реализаций каждая настройка канала связи может действовать параллельно с другими. Это - ключевой пункт. Если какая-либо настройка канала связи выполняет слишком много работы, то другие этапы простаивают, ожидая его для завершения. Ваш проект должен сбалансировать работу, выполняемую в каждой настройке канала связи к возможностям средства рендеринга. При настройке производительности приложения первый шаг должен обычно определять, какой этап приложение является имеющим узкие места в, и почему.
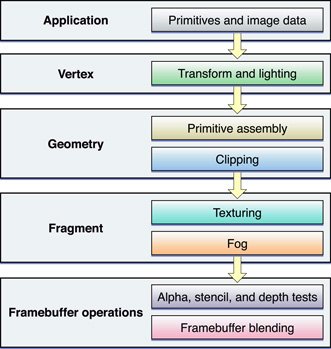
Другой способ визуализировать OpenGL как клиент-серверная архитектура, как показано на рисунке 9-2. Изменения состояния OpenGL, текстура и данные вершины и команды рендеринга должны все переместиться от приложения до клиента OpenGL. Клиент преобразовывает эти элементы так, чтобы аппаратное обеспечение машинной графики могло понять их, и затем вперед их к GPU. Мало того, что эти трансформации добавляют наверху, но и пропускная способность между CPU и аппаратным обеспечением машинной графики часто ниже, чем другие части системы.
Для достижения высокой эффективности приложение должно сократить частоту вызовов, которые они выполняют к OpenGL, минимизируют трансформацию наверху, и тщательно управляют потоком данных между приложением и аппаратным обеспечением машинной графики. Например, OpenGL обеспечивает механизмы, позволяющие некоторым видам данных кэшироваться в специализированной видеопамяти. Кэширование допускающих повторное использование данных в видеопамяти сокращает издержки передачи данных к аппаратному обеспечению машинной графики.
Разработка высокоэффективного приложения OpenGL
Для суммирования хорошо разработанное приложение OpenGL должно:
Параллелизм использования в конвейере OpenGL.
Управляйте потоком данных между приложением и аппаратным обеспечением машинной графики.
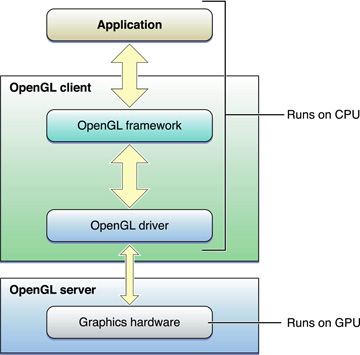
Рисунок 9-3 показывает предложенный технологический маршрут для приложения, использующего OpenGL для выполнения анимации к дисплею.
Когда приложение запускается, оно создает и инициализирует любые статические ресурсы, которые оно намеревается использовать в средстве рендеринга, инкапсулируя те ресурсы в объекты OpenGL, если это возможно. Цель состоит в том, чтобы создать любой объект, который может остаться неизменным в течение времени выполнения приложения. Это торгует увеличенным временем инициализации для лучшей производительности рендеринга. Идеально, сложные команды или пакеты изменений состояния должны быть заменены объектами OpenGL, которые могут быть переключены в с единственным вызовом функции. Например, конфигурирование конвейера стандартных функций может взять десятки вызовов функции. Замените его графической программой построения теней, компилирующейся во время инициализации, и можно переключиться на различную программу с единственным вызовом функции. В частности объекты OpenGL, которые являются дорогими, чтобы создать или изменить, должны быть созданы как статические объекты.
Цикл рендеринга обрабатывает все элементы, которые Вы намереваетесь представить к контексту OpenGL, затем подкачивает буферы для отображения результатов пользователю. В анимированной сцене некоторые данные должны быть обновлены для каждого кадра. Во внутреннем цикле рендеринга, показанном на рисунке 9-3, приложение чередуется между обновлением ресурсов рендеринга (возможно создающие или изменяющие объекты OpenGL в процессе) и представлением команд рендеринга, использующих те ресурсы. Цель этого внутреннего цикла состоит в том, чтобы сбалансировать рабочую нагрузку так, чтобы CPU и GPU работали параллельно, не блокируя друг друга при помощи тех же ресурсов одновременно.
Цель для внутреннего цикла состоит в том, чтобы избежать копировать данные назад от графического процессора до CPU. Операции, требующие, чтобы CPU считал результаты назад из аппаратного обеспечения машинной графики, иногда необходимы, но в общем чтении назад заканчивается, должен использоваться экономно. Если те результаты также используются для рендеринга текущего кадра, как показано в среднем цикле рендеринга, это может быть очень медленно. Копирование данных от GPU до CPU часто требует, чтобы некоторые или все ранее представленные команды рисования завершились.
После того, как приложение представляет все команды рисования, необходимые в кадре, оно представляет результаты экрану. Также неинтерактивное приложение могло бы считать заключительное изображение назад в CPU, но это также медленнее, чем представление результатов на экран. Этот шаг должен быть выполнен только для результатов, которые должны быть считаны назад в приложение. Например, Вы могли бы скопировать изображение в заднем буфере для сохранения его на диск.
Наконец, когда Ваше приложение готово закрыться, оно удаляет статические и динамические ресурсы для предоставления доступа больше к аппаратным ресурсам доступными для других приложений. Если Ваше приложение перемещено в фон, высвобождение средств к другим приложениям является также хорошей практикой.
Суммировать важные характеристики этого проекта:
Создайте статические ресурсы, каждый раз, когда практично.
Внутренний цикл рендеринга чередуется между изменением динамических ресурсов и представлением команд рендеринга. Достаточно работы должно быть включено в этот цикл так, чтобы, когда приложение должно читать или записать в любой объект OpenGL, графический процессор закончил обрабатывать любые команды, использовавшие его.
Избегите читать промежуточные результаты рендеринга в приложение.
Остальная часть этой главы обеспечивает полезные методы программирования OpenGL для реализования опций этого цикла рендеринга. Более поздние главы демонстрируют, как применить эти общие методы к определенным областям программирования OpenGL.
Обновите содержание OpenGL только, когда изменятся Ваши данные
Когда данные не изменились, приложения OpenGL должны избежать повторно вычислять сцену. Это критически важно на портативных устройствах, где сохранение питания критически важно по отношению к максимизации времени работы от батареи. Можно гарантировать, что приложение составляет только при необходимости следующим несколько простых инструкций:
Если Ваше приложение представляет анимацию, используйте Базовую ссылку Видеодисплея для управления циклом анимации. Перечисление 9-1 обеспечивает код, позволяющий Вашему приложению быть уведомленным, когда новый кадр должен быть выведен на экран. Этот код также синхронизирует обновления изображения с частотой обновления дисплея. Посмотрите Синхронизируются с Экранной Частотой обновления для получения дополнительной информации.
Если Ваше приложение не анимирует свое содержание OpenGL, необходимо позволить системе регулировать получение. Например, в Какао вызывают
setNeedsDisplay:метод, когда изменяются Ваши данные.Если Ваше приложение не использует Базовую ссылку Видеодисплея, необходимо все еще усовершенствовать анимацию только при необходимости. Для определения, когда нарисовать следующий кадр анимации вычислите различие между текущим временем и запуском последнего кадра. Используйте различие для определения, сколько усовершенствовать анимацию. Можно использовать Базовую функцию Основы
CFAbsoluteTimeGetCurrentполучить текущее время.
Перечисление 9-1 , Настраивающее Базовую ссылку Видеодисплея
@interface MyView : NSOpenGLView |
{ |
CVDisplayLinkRef displayLink; //display link for managing rendering thread |
} |
@end |
- (void)prepareOpenGL |
{ |
// Synchronize buffer swaps with vertical refresh rate |
GLint swapInt = 1; |
[[self openGLContext] setValues:&swapInt forParameter:NSOpenGLCPSwapInterval]; |
// Create a display link capable of being used with all active displays |
CVDisplayLinkCreateWithActiveCGDisplays(&displayLink); |
// Set the renderer output callback function |
CVDisplayLinkSetOutputCallback(displayLink, &MyDisplayLinkCallback, self); |
// Set the display link for the current renderer |
CGLContextObj cglContext = [[self openGLContext] CGLContextObj]; |
CGLPixelFormatObj cglPixelFormat = [[self pixelFormat] CGLPixelFormatObj]; |
CVDisplayLinkSetCurrentCGDisplayFromOpenGLContext(displayLink, cglContext, cglPixelFormat); |
// Activate the display link |
CVDisplayLinkStart(displayLink); |
} |
// This is the renderer output callback function |
static CVReturn MyDisplayLinkCallback(CVDisplayLinkRef displayLink, const CVTimeStamp* now, const CVTimeStamp* outputTime, |
CVOptionFlags flagsIn, CVOptionFlags* flagsOut, void* displayLinkContext) |
{ |
CVReturn result = [(MyView*)displayLinkContext getFrameForTime:outputTime]; |
return result; |
} |
- (CVReturn)getFrameForTime:(const CVTimeStamp*)outputTime |
{ |
// Add your drawing codes here |
return kCVReturnSuccess; |
} |
- (void)dealloc |
{ |
// Release the display link |
CVDisplayLinkRelease(displayLink); |
[super dealloc]; |
} |
Синхронизируйтесь с экранной частотой обновления
Разрыв является визуальной аномалией, вызванной, когда часть текущего кадра перезаписывает предыдущие данные кадра в кадровом буфере, прежде чем текущий кадр будет полностью представлен на экране. Чтобы избежать рваться, приложения используют контекст с двойной буферизацией и синхронизируют буферные подкачки с экранной частотой обновления (иногда называемый VBL, вертикальным пробелом или vsynch) для устранения разрыва кадра.
Частота обновления дисплея ограничивает, как часто может быть обновлен экран. Экран может быть обновлен на уровнях, которые являются делимыми целочисленными значениями. Например, дисплей CRT, имеющий частоту обновления 60 Гц, может поддерживать экранные частоты обновления 60 Гц, 30 Гц, 20 Гц и 15 Гц. Жидкокристаллические дисплеи не имеют вертикали, восстанавливают в CRT, распознаются и, как обычно полагают, имеют фиксированную частоту обновления 60 Гц.
После того, как Вы говорите контексту подкачивать буферы, OpenGL должен задержать любые команды рендеринга, следующие за той подкачкой, пока успешно не обменялись буферами. Приложения, пытающиеся нарисовать на экран в течение этого времени ожидания, напрасно тратят время, который мог быть потрачен, выполнив другие операции рисования или сохранив время работы от батареи и минимизировав работу вентилятора.
Перечисление 9-2 показывает как NSOpenGLView объект может синхронизироваться с экранной частотой обновления; если приложение использует контексты CGL, можно использовать аналогичный подход. Это предполагает установку контекста для двойной буферизации. Интервал подкачки может быть установлен только в 0 или 1. Если интервал подкачки установлен в 1, буферы подкачиваются только во время вертикали, восстанавливают.
Перечисление 9-2 , Настраивающее синхронизацию
GLint swapInterval = 1; |
[[self openGLContext] setValues:&swapInt forParameter:NSOpenGLCPSwapInterval]; |
Избегите синхронизировать и сбрасывать операции
OpenGL не требуется, чтобы выполнять большинство команд сразу. Часто, они ставятся в очередь к буферу команд и читаются и выполняются аппаратными средствами в более позднее время. Обычно, OpenGL ожидает, пока приложение не стояло в очереди значительное количество команд прежде, чем отправить буфер в аппаратные средства — разрешение аппаратного обеспечения машинной графики выполнить команды в пакетах часто более эффективно. Однако некоторые функции OpenGL должны сразу сбросить буфер. Другие функции не только сбрасывают буфер, но также и блок, пока ранее представленные команды не завершились перед возвращением управления к приложению. Ваше приложение должно ограничить использование сбрасывания и синхронизации команд только к тем случаям, где то поведение необходимо. Злоупотребление сбрасыванием или синхронизацией команд добавляет дополнительные остановы, ожидающие аппаратных средств, чтобы закончить представлять. На однобуферном контексте сбрасывание может также вызвать визуальные аномалии, такие как мерцание или разрыв.
Эти ситуации требуют, чтобы OpenGL представил буфер команд аппаратным средствам для выполнения.
Функция
glFlushожидает, пока команды не представлены, но не ожидает команд, чтобы закончить выполняться.Функция
glFinishожидает всех ранее представленных команд для завершения выполнения.Функции, получающие состояние OpenGL (например,
glGetError), также ожидайте представленных команд для завершения.Буферные подпрограммы свопинга (
flushBufferметодNSOpenGLContextкласс илиCGLFlushDrawableфункция), неявно вызываютglFlush. Обратите внимание на то, что при использованииNSOpenGLContextкласс или API CGL, термин сброс фактически относится к подкачивающей буфер работе. Для однобуферных контекстов,glFlushиglFinishэквивалентны работе подкачки, так как весь рендеринг имеет место непосредственно в переднем буфере.Буфер команд полон.
Используя glFlush Эффективно
Большую часть времени Вы не должны вызывать glFlush перемещать данные изображения в экран. Существует только несколько случаев, требующих, чтобы Вы вызвали glFlush функция:
Если Ваше приложение представляет команды рендеринга, использующие определенный объект OpenGL, и оно намеревается изменить тот объект в ближайшем будущем. При попытке изменить объект OpenGL, имеющий незаконченные команды рисования, Ваше приложение может быть вынуждено ожидать, пока не были завершены те команды. В этой ситуации, вызывая
glFlushгарантирует, что аппаратные средства начинают обрабатывать команды сразу. После сбрасывания буфера команд Ваше приложение должно выполнить работу, для которой не нужен тот ресурс. Это может выполнить другую работу (даже изменяющий другие объекты OpenGL).Ваше приложение должно изменить drawable объект, связанный с контекстом рендеринга. Прежде чем можно будет переключиться на другой drawable объект, необходимо вызвать
glFlushгарантировать, что были представлены все команды, записанные в очереди команды для предыдущего drawable объекта.Когда два контекста совместно используют объект OpenGL. После представления любых команд OpenGL вызвать
glFlushпрежде, чем переключиться на другой контекст.Продолжить рисовать синхронизировалось через многократные потоки, и предотвратите повреждение буфера команд, каждый поток должен представить свои команды рендеринга и затем вызвать
glFlush.
Избегите запрашивать состояние OpenGL
Вызовы к glGet*(), включая glGetError(), может потребовать, чтобы OpenGL выполнил предыдущие команды прежде, чем получить любые переменные состояния. Эта синхронизация вынуждает аппаратное обеспечение машинной графики работать жестко регламентированный с CPU, сокращая возможности для параллелизма.
Ваше приложение должно сохранить теневые копии любого состояния OpenGL, которое необходимо запросить и поддержать эти теневые копии, поскольку Вы изменяете состояние.
Когда ошибки происходят, OpenGL устанавливает флаг ошибки, который можно получить с функцией glGetError. Во время разработки крайне важно, чтобы Ваш код содержал подпрограммы проверки ошибок, не только для стандартных вызовов OpenGL, но и для специфичных для Apple функций, предоставленных API CGL. Если Вы разрабатываете важное приложение производительности, получаете информацию об ошибке только в фазу отладки. Вызов glGetError чрезмерно в сборке конечных версий ухудшает производительность.
Используйте пределы для синхронизации с более прекрасными зернами
Избегать использования glFinish в Вашем приложении, потому что это ожидает, пока все ранее представленные команды не завершаются перед возвращением управления к Вашему приложению. Вместо этого необходимо использовать расширение предела (APPLE_fence). Это расширение создавалось для обеспечения уровня гранулярности, которой не предоставлены glFinish. Предел является маркером, используемым для маркировки текущей точки в потоке команды. Когда используется правильно, это позволяет Вам гарантировать, что был завершен определенный ряд команд. Предел помогает скоординировать действие между CPU и GPU, когда они используют те же ресурсы.
Выполните эти шаги, чтобы установить и использовать предел:
Во время инициализации создайте объект предела путем вызывания функции
glGenFencesAPPLE.GLint myFence;
glGenFencesAPPLE(1,&myFence);
Вызовите функции OpenGL, которые должны завершиться до предела.
Установите предел путем вызывания функции
glSetFenceAPPLE. Эта функция вставляет маркер в поток команды и устанавливает состояние предела вfalse.void glSetFenceAPPLE(GLuint fence);
fenceуказывает маркер для вставки. Например:glSetFenceAPPLE(myFence);
Вызвать
glFlushвынудить команды быть отправленными в аппаратные средства. Этот шаг является дополнительным, но рекомендуемый гарантировать, что аппаратные средства начинают обрабатывать команды OpenGL.Выполните другую работу в своем приложении.
Ожидайте всех команд OpenGL, данных до предела для завершения путем вызывания функции
glFinishFenceAPPLE.glFinishFenceAPPLE(myFence);
Как альтернатива вызову
glFinishFenceAPPLE, можно вызватьglTestFenceAPPLEопределить, был ли достигнут предел. Преимущество тестирования предела состоит в том, что Ваше приложение не блокирует ожидание предела для завершения. Если Ваше приложение может продолжать обрабатывать другую работу при ожидании предела для инициирования, это полезно.glTestFenceAPPLE(myFence);
Когда для Вашего приложения больше не будет нужен предел, удалите его путем вызывания функции
glDeleteFencesAPPLE.glDeleteFencesAPPLE(1,&myFence);
Существует искусство к определению, где вставить предел в поток команды. При вставке предела для очень небольшого числа команд рисования Вы рискуете иметь свой останов приложения, в то время как он ожидает рисования для завершения. Вы захотите установить предел, таким образом, Ваше приложение будет работать максимально асинхронно без остановки.
Расширение предела также позволяет Вам синхронизировать буферные обновления для объектов, таких как массивы вершины и текстуры. Для этого Вы вызываете функцию glFinishObjectAPPLE, предоставление имени объекта вместе с маркером.
Для получения дальнейшей информации на этом расширении, посмотрите спецификацию OpenGL для расширения предела Apple.
Позвольте OpenGL управлять своими ресурсами
OpenGL позволяет многим типам данных постоянно быть сохраненными в OpenGL. Создание OpenGL возражает для хранения вершины, текстуры, или другие формы данных позволяют OpenGL сокращать издержки преобразования данных и отправки их к графическому процессору. Если данные используются более часто, чем они изменяются, OpenGL может существенно улучшить производительность Вашего приложения.
OpenGL позволяет Вашему приложению подсказывать, как это намеревается использовать данные. Эти подсказки позволяют OpenGL делать информированный выбор того, как обработать Ваши данные. Например, статические данные могли бы быть помещены в высокоскоростную видеопамять, непосредственно подключенную к графическому процессору. Данные, изменяющиеся часто, могли бы сохраняться в оперативной памяти и получаться доступ аппаратным обеспечением машинной графики через DMA.
Используйте двойную буферизацию для предотвращения конфликтов ресурса
Когда Ваше приложение и OpenGL хотят получить доступ к ресурсу одновременно, конфликты ресурса происходят. Когда один участник пытается изменить объект OpenGL, используемый другим, одним из двух проблемных результатов:
Участник, хотящий изменить объектные блоки, пока это больше не используется. Тогда другому участнику не разрешают читать из или записать в объект, пока модификации не завершены. Это безопасно, но они могут быть скрыты узкие места в Вашем приложении.
Некоторые расширения позволяют OpenGL получать доступ к памяти приложения, к которой может одновременно получить доступ приложение. В этой ситуации, синхронизирующейся между этими двумя участниками, оставлен приложению управлять. Ваши вызовы приложения
glFlushвынудить OpenGL выполнить команды и использование предел илиglFinishгарантировать что никакие команды что доступ, что память находится на рассмотрении.
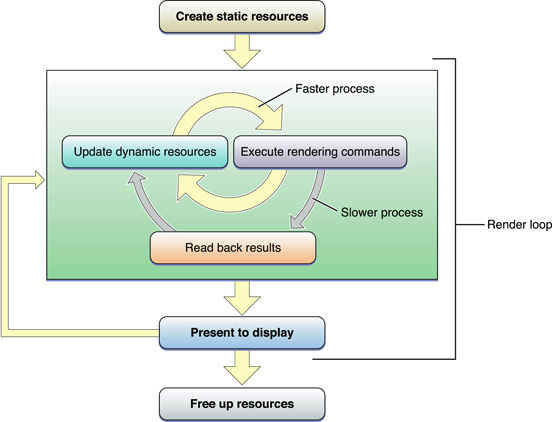
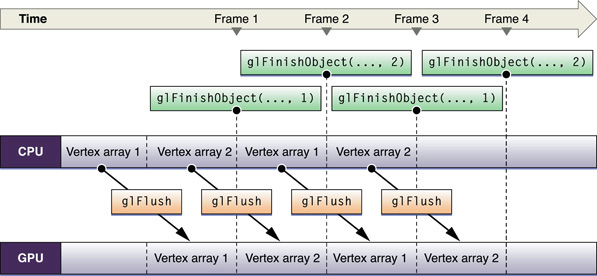
Полагается ли Ваше приложение на OpenGL для синхронизации доступа к ресурсу, или это вручную синхронизирует доступ, конкуренция ресурса вынуждает одного из участников ожидать, вместо того, чтобы позволить им обоим выполняться параллельно. Рисунок 9-4 демонстрирует эту проблему. Существует только единственный буфер для данных вершины, которые и приложение и OpenGL хотят использовать, и поэтому приложение должно ожидать до команд обработки концов GPU, прежде чем это изменит данные.
Для решения этой проблемы приложение могло заполниться на сей раз другой обработкой, даже другой OpenGL, обрабатывающий, которому не нужны рассматриваемые объекты. Если необходимо обработать больше команд OpenGL, решение состоит в том, чтобы создать два из того же типа ресурса и позволить каждому участвующему доступу ресурс. Рисунок 9-5 иллюстрирует подход с двойной буферизацией. В то время как GPU воздействует на один набор данных массива вершины, CPU изменяет другой. После начального запуска никакой блок обработки не неактивен. Этот пример использует предел, чтобы гарантировать, что синхронизируется доступ к каждому буферу.
Двойная буферизация достаточна для большинства приложений, но она требует, чтобы оба участника закончили обрабатывать свои команды, прежде чем сможет произойти подкачка. Для традиционной проблемы производителя-потребителя больше чем два буфера могут препятствовать тому, чтобы участник блокировал. С тройной буферизацией производителем и потребителем у каждого есть буфер с третьим неактивным буфером. Если производитель заканчивает, прежде чем потребитель заканчивает обрабатывать команды, это берет неактивный буфер и продолжает обрабатывать команды. В этой ситуации бездействует производитель, только если потребитель падает плохо позади.
Помните переменные состояния OpenGL
Аппаратные средства имеют одно текущее состояние, компилирующееся и кэширующееся. Переключение состояния является дорогим, поэтому лучше разрабатывать Ваше приложение для минимизации переключателей состояния.
Не устанавливайте состояние, это уже установлено. Как только опция активирована, она не должна быть включена снова. Вызов, кроме которого разрешать функция несколько раз не делает ничего, напрасно тратит время, потому что OpenGL не проверяет состояние функции, когда Вы вызываете glEnable или glDisable. Например, если Вы вызываете glEnable(GL_LIGHTING) несколько раз OpenGL не проверяет, чтобы видеть, включено ли уже состояние освещения. Даже если то значение идентично текущей стоимости, это просто обновляет значение состояния.
Можно избежать устанавливать состояние, более, чем необходимое при помощи специализированной установки, или завершить работу подпрограмм вместо того, чтобы поместить такие вызовы в цикл получения. Установите и завершите работу, подпрограммы также полезны для того, чтобы включить и выключить функции, достигающие определенного визуального эффекта — например, при рисовании каркасной схемы вокруг текстурированного многоугольника.
Если Вы - изображения получения 2D, отключаете все несоответствующие переменные состояния, подобные тому, что показано в Перечислении 9-3.
Перечисление 9-3 , Запрещающее переменные состояния
glDisable(GL_DITHER); |
glDisable(GL_ALPHA_TEST); |
glDisable(GL_BLEND); |
glDisable(GL_STENCIL_TEST); |
glDisable(GL_FOG); |
glDisable(GL_TEXTURE_2D); |
glDisable(GL_DEPTH_TEST); |
glPixelZoom(1.0,1.0); |
// Disable other state variables as appropriate. |
Замените изменения состояния объектами OpenGL
Помнить раздел OpenGL State Variables предполагает, что сокращение количества изменений состояния может улучшить производительность. Некоторые расширения OpenGL также позволяют Вам создавать объекты, собирающие многократные изменения состояния OpenGL в объект, который может быть связан с единственным вызовом функции. Где такие методы доступны, им рекомендуют. Например, конфигурирование конвейера стандартных функций требует многих вызовов функции изменить состояние различных операторов. Мало того, что это подвергается наверху для каждой вызванной функции, но код является более сложным и трудным управлять. Вместо этого используйте программу построения теней. Программа построения теней, когда-то скомпилированная, может иметь тот же эффект, но требует только единственного вызова к glUseProgram.
Другие примеры объектов, занимающих место многократных изменений состояния, включают Расширение диапазона Массива Вершины и Универсальные Буферы.
Используйте оптимальные типы данных и форматы
Если Вы не используете типы данных и форматы, которые являются собственными к аппаратному обеспечению машинной графики, OpenGL должен преобразовать те типы данных в формат, который понимает аппаратное обеспечение машинной графики.
Для данных вершины использовать GLfloat, GLshort, или GLubyte типы данных. Большая часть аппаратного обеспечения машинной графики обрабатывает эти типы исходно.
Для данных текстуры Вы получите лучшую производительность при использовании следующего типа формата и комбинации типа данных:
GL_BGRA,GL_UNSIGNED_INT_8_8_8_8_REV
Они тип формата и комбинации типа данных также обеспечивают приемлемую производительность:
GL_BGRA,GL_UNSIGNED_SHORT_1_5_5_5_REVGL_YCBCR_422_APPLE,GL_UNSIGNED_SHORT_8_8_REV_APPLE
Комбинация GL_RGBA и GL_UNSIGNED_BYTE потребности быть swizzled многими картами, когда данные загружаются, таким образом, это не рекомендуется.
Используйте макросы OpenGL
OpenGL выполняет глобальный контекст и поиск средства рендеринга для каждой команды, которую это выполняет, чтобы гарантировать, что все команды OpenGL даются к корректному контексту рендеринга и средству рендеринга. Существует значительный служебный связанный с этими поисками; приложения, имеющие чрезвычайно высокие частоты вызова, могут найти, что издержки в известной мере влияют на производительность. OS X позволяет Вашему приложению использовать макросы, чтобы обеспечить локальную переменную контекста и кэшировать текущее средство рендеринга в той переменной. Когда Ваш код делает миллионы вызовов функции в секунду, Вы извлекаете больше пользы из использования макросов.
Прежде, чем реализовать этот метод, рассмотрите тщательно, можно ли перепроектировать приложение для выполнения меньшего количества вызовов функции. Часто изменение состояния OpenGL, продвижение или сование матриц, или даже представление одной вершины за один раз являются всеми примерами методов, которые должны быть заменены более эффективными операциями.
Можно использовать макро-заголовок CGL (CGL/CGLMacro.h) если Ваше приложение использует CGL из приложения Какао. Необходимо определить локальную переменную cgl_ctx быть равным текущему контексту. Перечисление 9-4 показывает то, что необходимо для установки макро-использования для API CGL. Во-первых, необходимо включать корректный макро-заголовок. Затем необходимо установить текущий контекст.
Перечисление 9-4 Используя макросы CGL
#include <CGL/CGLMacro.h> // include the header |
CGL_MACRO_DECLARE_VARIABLES // set the current context |
glBegin (GL_QUADS); // This code now uses the macro |
// draw here |
glEnd (); |