Предотвращение переполнения буфера и потерь значимости
Переполнение буфера, и на штабеле и на «куче», является основным источником уязвимостей системы обеспечения безопасности в C, Objective C и коде C++. В этой главе рассматриваются методы кодирования, которые избегут переполнения буфера и недостаточно заполнят проблемы, инструменты списков Вы можете использовать для обнаружения переполнения буфера и обеспечиваете выборки, иллюстрирующие безопасный код.
Каждый раз Ваша программа требует ввода (ли от пользователя, от файла, по сети, или некоторыми другими средними значениями), существует потенциал для получения несоответствующих данных. Например, входные данные могли бы быть более длинными, чем, для чего Вы зарезервировали комнату в памяти.
Когда входные данные более длинны, чем поместится в зарезервированное пространство, если Вы не усечете его, то те данные перезапишут другие данные в памяти. Когда это происходит, это вызывают переполнением буфера. Если память перезаписанные содержавшие данные, важные для работы программы, это переполнение вызывает ошибку, которую, будучи неустойчивой, могло бы быть очень трудно найти. Если перезаписанные данные включают адрес другого кода, который будет выполняться, и пользователь сделал это сознательно, пользователь может указать на вредоносный код, что тогда выполнится Ваша программа.
Точно так же, когда входные данные или, кажется, короче, чем зарезервированное пространство (вследствие ошибочных предположений, неправильных значений длины или копирования необработанных данных как струна до), это вызывают недостаточным наполнением буфера. Это может вызвать любое число проблем от неправильного поведения до протекающих данных, которые в настоящее время находятся на штабеле или «куче».
Несмотря на то, что большая часть ввода проверки языков программирования против хранения для предотвращения переполнения буфера и потерь значимости, C, Objective C и C++ не делает. Поскольку много программ соединяются с библиотеками C, уязвимости в стандартных библиотеках могут вызвать уязвимости даже в программах, записанных на «безопасных» языках. Поэтому, даже если Вы уверены, что Ваш код свободен от проблем переполнения буфера, необходимо ограничить воздействие путем выполнения с наименьшим количеством возможных полномочий. Посмотрите Подъемные Полномочия Безопасно для получения дополнительной информации об этой теме.
Следует иметь в виду, что очевидные формы ввода, такие как строки, вводимые через диалоговые окна, не являются единственным потенциальным источником злонамеренного ввода. Например:
Переполнение буфера в системе справочной информации одной операционной системы могло быть вызвано злонамеренно подготовленными встроенными изображениями.
Обычно используемому медиапроигрывателю не удалось проверить определенный тип аудиофайлов, позволив атакующему выполнить произвольный код путем порождения переполнения буфера с тщательно обработанным аудиофайлом.
[1CVE-2006-1591 2CVE-2006-1370]
Существует две основных категории переполнения: переполнения стека и переполнение «кучи». Они описаны более подробно в следующих разделах.
Переполнения стека
В большинстве операционных систем каждое приложение имеет штабель (и многопоточные приложения имеют один штабель на поток). Этот штабель содержит хранение для локально ограниченных по объему данных.
Штабель разделен в вызванные стековые фреймы модулей. Каждый стековый фрейм содержит все данные, определенные для определенного вызова к определенной функции. Эти данные обычно включают параметры функции, полный набор локальных переменных в той функции и информацию о связи — т.е. адрес самого вызова функции, где выполнение продолжается, когда функция возвращается). В зависимости от флагов компилятора это может также содержать адрес вершины следующего стекового фрейма. Точное содержание и порядок данных по штабелю зависят от операционной системы и архитектуры ЦП.
Каждый раз, когда функция вызвана, новый стековый фрейм добавляется к вершине штабеля. Каждый раз, когда функция возвращается, верхний стековый фрейм удален. В любой данной точке в выполнении приложение может только непосредственно получить доступ к данным в самом верхнем стековом фрейме. (Указатели могут обойти это, но это обычно - плохая идея сделать так.) Этот проект делает рекурсию возможной, потому что каждый вложенный вызов к функции получает свою собственную копию локальных переменных и параметров.
Рисунок 2-1 иллюстрирует организацию штабеля. Обратите внимание на то, что это число схематично только; фактическое содержание и порядок данных ставят штабель, зависит от архитектуры используемого CPU. Посмотрите OS X Руководство по Вызову функции ABI для описаний функциональных соглашений о вызовах, используемых во всей архитектуре, поддерживаемой OS X.

В целом приложение должно проверить все входные данные, чтобы удостовериться, что это является надлежащим в предназначенной цели (например, удостоверяясь, что имя файла имеет юридическую длину и не содержит запрещенных символов). К сожалению, во многих случаях, программисты не беспокоятся, предполагая, что пользователь не сделает ничего неблагоразумного.
Когда приложение хранит те данные в буфер фиксированного размера, это становится серьезной проблемой. Если пользователь является злонамеренным (или открывает файл, содержащий данные, создаваемые кем-то, кто является злонамеренным), он или она мог бы предоставить данные, которые более длинны, чем размер буфера. Поскольку функция резервирует только ограниченную сумму пространства на штабеле для этих данных, данные перезаписывают другие данные по штабелю.
Как показано на рисунке 2-2, умный атакующий может использовать этот метод для перезаписи обратного адреса, используемого функцией, заменяя адресом его собственного кода. Затем когда функция C завершает выполнение, вместо того, чтобы возвратиться к функции B, это переходит к коду атакующего.
Поскольку приложение выполняет код атакующего, код атакующего наследовал полномочия пользователя. Если пользователь зарегистрирован как администратор (конфигурация по умолчанию в OS X), атакующий может взять на себя полное управление компьютера, считав данные из диска, послав электронные письма, и т.д. (В iOS приложения намного более ограничиваются в их полномочиях и вряд ли будут в состоянии взять на себя полное управление устройства.)
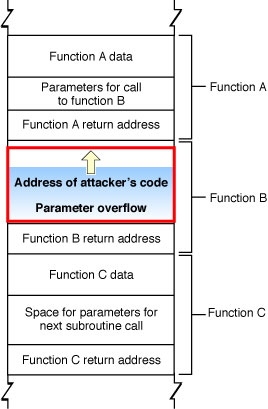
В дополнение к атакам на информацию о связи атакующий может также изменить работу программы путем изменения локальных данных и параметров функции на штабеле. Например, вместо того, чтобы соединиться с желаемым узлом, атакующий мог изменить структуру данных так, чтобы Ваше приложение соединилось с различным (злонамеренным) узлом.
Переполнение «кучи»
Как упомянуто ранее, «куча» используется для всей динамично выделенной памяти в Вашем приложении. Когда Вы используете malloc, C++ new оператор или эквивалентные функции, чтобы выделить блок памяти или инстанцировать объекта, память, поддерживающая те указатели, выделяются на «куче».
Поскольку «куча» используется, чтобы хранить данные, но не используется для хранения значения обратного адреса функций и методов, и потому что данные по изменениям «кучи» неочевидным способом как программа работают, менее очевидно, как атакующий может использовать переполнение буфера на «куче». В некоторой степени именно эта неочевидность делает переполнение «кучи» привлекательной целью — программисты, менее вероятно, будут волноваться о них и защищать от них, чем они для переполнений стека.
Рисунок 2-1 иллюстрирует переполнение «кучи», перезаписывающее указатель.
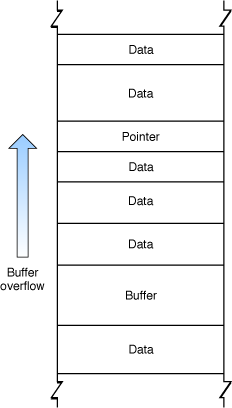
В целом использование переполнения буфера на «куче» более сложно, чем использование переполнения на штабеле. Однако много успешного использования включили переполнение «кучи». Существует два пути, которыми используется переполнение «кучи»: путем изменения данных и путем изменения объектов.
Атакующий может использовать переполнение буфера на «куче» путем перезаписи критических данных, или чтобы заставить программу разрушать или изменять значение, которое может быть использовано позже (перезаписывающий сохраненный идентификатор пользователя для получения дополнительного доступа, например). Изменение этих данных известно как атака неуправляющей информации. Большая часть данных по «куче» сгенерирована внутренне программой, а не скопирована с ввода данных пользователем; такие данные могут быть в относительно непротиворечивых расположениях в памяти, в зависимости от того, как и когда приложение выделяет его.
Атакующий может также использовать переполнение буфера на «куче» путем перезаписи указателей. На многих языках, таких как C++ и Objective C, объекты, выделенные на «куче», содержат таблицы указателей данных и функции. Путем использования переполнения буфера для изменения таких указателей атакующий может потенциально заменить различными данными или даже заменить методы экземпляра в объекте класса.
Использование переполнения буфера на «куче» могло бы быть сложной, тайной проблемой решить, но взломщики процветают на просто таких проблемах. Например:
Переполнение «кучи» в коде для декодирования растрового изображения позволило удаленным атакующим выполнять произвольный код.
Уязвимость переполнения «кучи» в сетевом сервере позволила атакующему выполнять произвольный код путем отправления HTTP запроса POST с отрицательным заголовком «Довольной Длины».
[1CVE-2006-0006 2CVE-2005-3655]
Строковая обработка
Строки являются стандартной формой ввода. Поскольку много обрабатывающих строку функций не имеют никаких встроенных проверок на длину строки, строки часто являются источником годного для использования переполнения буфера. Рисунок 2-4 иллюстрирует различные способы, которыми три строковых функции копии обрабатывают ту же строку сверхдлины.
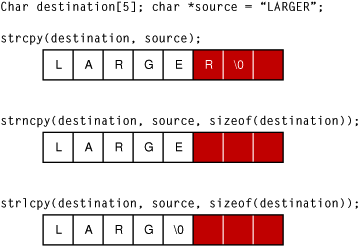
Как Вы видите, strcpy функционируйте просто пишет всю строку в память, перезаписывая то независимо от того, что прибыло после него.
strncpy функция усекает строку к корректной длине, но без завершающегося нулевого символа. Когда эта строка читается, тогда, все байты в памяти после нее, до следующего нулевого символа, могли бы быть считаны как часть строки. Несмотря на то, что эта функция может использоваться безопасно, это - частый источник ошибок программиста, и таким образом расценивается как умеренно небезопасное. Безопасно использовать strncpy, необходимо или явно обнулить последний байт буфера после вызова strncpy или предварительно обнулите буфер и затем передайте в максимальной длине, которая на один байт меньше, чем размер буфера.
Только strlcpy функция полностью безопасна, усекая строку к на один байт меньшему, чем размер буфера и добавляя завершающийся нулевой символ.
Таблица 2-1 суммирует общие обрабатывающие струну до подпрограммы для предотвращения и чтобы использовать вместо этого.
Не используйте эти функции | Используйте их вместо этого |
|---|---|
|
Можно также избежать строки, обрабатывающей переполнение буфера при помощи высокоуровневых интерфейсов.
Если Вы используете C++, C++ ANSI
stringкласс избегает переполнения буфера, хотя он не обрабатывает кодировки неASCII (такие как UTF-8).Если Вы пишете код в Objective C, используйте
NSStringкласс. Обратите внимание на то, чтоNSStringобъект должен быть преобразован в струну до, чтобы быть переданным подпрограмме C, такой как функция POSIX.Если Вы пишете код в C, можно использовать Базовое представление Основы строки, называемой CFString и функциями обработки строк в API CFString.
Базовая Основа CFString “бесплатная соединенный мостом” с его дубликатом Основы Какао, NSString. Это означает, что Базовый тип Основы является взаимозаменяемым в вызовах функции или вызовах метода с его эквивалентным объектом Основы. Поэтому в методе, где Вы видите NSString * параметр, можно передать в значении типа CFStringRef, и в функции, где Вы видите a CFStringRef параметр, можно передать в NSString экземпляр. Это также применяется к конкретным подклассам NSString.
См. Ссылку CFString, Ссылку Платформы Основы и Руководство по интеграции Какао углерода для большего количества подробных данных об использовании этих представлений строк и при преобразовании между объектами CFString и NSString объекты.
Вычисление буферных размеров
При работе с буферами фиксированной длины необходимо всегда использовать sizeof чтобы вычислить размер буфера, и затем удостовериться, Вы не помещаете больше данных в буфер, чем это может содержать. Даже если Вы первоначально присвоили статический размер буферу, или Вы, или кто-то еще поддерживающий Ваш код в будущем мог бы изменить размер буфера, но мог бы не изменить каждый случай, где буфер записан в.
Первый пример, Таблица 2-2, показывает, что два способа выделить символ буферизуют 1 024 байта в длине, проверяя длину входной строки, и копируя его в буфер.
Вместо этого: | Сделайте это: |
|---|---|
|
|
|
|
Эти два отрывка на левой стороне безопасны, пока никогда не изменяется исходное объявление размера буфера. Однако, если размер буфера будет изменен в более поздней версии программы, не изменяя тест, то переполнение буфера закончится.
Эти два отрывка на правой стороне показывают более безопасные версии этого кода. В первой версии размер буфера установлен с помощью константы, установленной в другом месте, и проверка использует ту же константу. Во второй версии буфер установлен в 1 024 байта, но проверка вычисляет фактический размер буфера. В любом из этих отрывков, изменяя первоначальный размер буфера не лишает законной силы проверку.
TTable 2-3, показывает функцию, добавляющую .ext снабдите суффиксом к имени файла.
Вместо этого: | Сделайте это: |
|---|---|
|
|
Обе версии используют максимальную длину пути для файла как размер буфера. Небезопасная версия в левом столбце предполагает, что имя файла не превышает этот предел и добавляет суффикс, не проверяя длину строки. Более безопасная версия в правом столбце использует strlcat функция, усекающая строку, если это превышает размер буфера.
Для дальнейшего обсуждения этой проблемы и списка большего количества функций, которые могут вызвать проблемы, посмотрите Уилера, Безопасное Программирование для Linux и Unix HOWTO (http://www .dwheeler.com/secure-programs/).
Предотвращение целочисленных переполнений и потерь значимости
Если размер буфера вычисляется с помощью данных, снабженных пользователем, существует потенциал для злонамеренного пользователя для введения номера, который является слишком большим для целочисленного типа данных, который может вызвать катастрофические отказы программы и другие проблемы.
В two's-дополнительной арифметике (используемый для арифметики целого числа со знаком самым современным CPUs), отрицательное число представлено путем инвертирования всех битов двоичного числа и добавления 1. A 1 в старшем значащем бите указывает отрицательное число. Таким образом, для 4-байтовых целых чисел со знаком, 0x7fffffff = 2147483647, но 0x80000000 = -2147483648
Поэтому
int 2147483647 + 1 = - 2147483648 |
Если злонамеренный пользователь указывает отрицательное число, где Ваша программа ожидает только числа без знака, Ваша программа могла бы интерпретировать ее как очень большое количество. В зависимости от какого то число используется для, Ваша программа могла бы попытаться выделить буфер того размера, заставив выделение памяти перестать работать или вызвав переполнение «кучи», если успешно выполняется выделение. В ранней версии популярного веб-браузера, например, храня объекты в массив JavaScript, выделенный с отрицательным размером, мог перезаписать память. [CVE-2004-0361]
В других случаях при использовании подписанных значений для вычисления буферных размеров и теста для проверки данные не являются слишком большими для буфера, достаточно большой блок данных, будет казаться, будет иметь отрицательный размер и поэтому пройдет тест размера при переполнении буфера.
В зависимости от того, как размер буфера вычисляется, указывая, что отрицательное число могло привести к буферу, слишком маленькому для его надлежащего использования. Например, если Ваша программа хочет минимальный размер буфера 1 024 байтов и добавляет, которому число, указанное пользователем, атакующий мог бы заставить Вас выделять буфер, меньшего размера, чем минимальный размер путем указания большого положительного числа, следующим образом:
1024 + 4294966784 = 512 |
0x400 + 0xFFFFFE00 = 0x200 |
Кроме того, отбрасываются любые биты, переполняющиеся мимо длины целочисленной переменной (или подписанный или без знака). Например, когда сохраненный в 32-разрядном целом числе, 2**32 == 0. Поскольку это не недопустимо для имения буфера с размером 0, и потому что malloc(0) возвращает указатель на маленький блок, Ваш код мог бы работать без ошибок, если атакующий указывает значение, заставляющее Ваше вычисление размера буфера быть некоторым кратным числом 2**32. Другими словами, для любых значений n и m где (n * m) mod 2**32 == 0, выделение буфера размера n*m результаты в допустимом указателе на буфер некоторых очень маленьких (и архитектурно-зависимый) размер. В этом случае переполнение буфера гарантируют.
Для предотвращения таких проблем, при выполнении буферной математики, необходимо всегда включать проверки диапазона, чтобы удостовериться, что никакое целочисленное переполнение не собирается произойти.
Частая ошибка при выполнении этих тестов состоит в том, чтобы проверить результат потенциально переполняющегося умножения или другой работы:
size_t bytes = n * m; |
if (bytes < n || bytes < m) { /* BAD BAD BAD */ |
... /* allocate “bytes” space */ |
} |
К сожалению, спецификация языка C позволяет компилятору оптимизировать такие тесты [CWE-733, CERT VU#162289]. Таким образом единственный корректный способ протестировать на целочисленное переполнение состоит в том, чтобы разделить максимальный допустимый результат на множитель и сравнение результата ко множимому или наоборот. Если бы результат меньше, чем множимое, продукт тех двух значений вызвал бы целочисленное переполнение.
Например:
if (n > 0 && m > 0 && SIZE_MAX/n >= m) { |
size_t bytes = n * m; |
... /* allocate “bytes” space */ |
} |
Обнаружение переполнения буфера
Для тестирования на переполнение буфера необходимо попытаться ввести больше данных, чем просят относительно того, везде, где программа принимает ввод. Кроме того, если Ваша программа принимает данные в стандартном формате, таком как графические или аудиоданные, необходимо попытаться передать его некорректные данные. Этот процесс известен как fuzzing.
Если будет переполнение буфера в Вашей программе, то она в конечном счете откажет. (К сожалению, это не могло бы отказать до некоторое время спустя, когда это пытается использовать перезаписанные данные.) Крешлог мог бы дать некоторые представления, что причиной катастрофического отказа было переполнение буфера. Например, при вводе строки, содержащей прописную букву несколько раз подряд Вы могли бы найти блок данных в крешлоге, повторяющем номер 41, код ASCII для (см. рисунок 2-2). Если программа пытается перейти к расположению, которое является фактически строкой ASCII, это - верный признак, что переполнение буфера было ответственно за катастрофический отказ.

Если существует какое-либо переполнение буфера в Вашей программе, необходимо всегда предполагать, что они являются годными для использования и фиксируют их. Намного более трудно доказать, что переполнение буфера не является годным для использования, чем просто исправить ошибку. Также обратите внимание на то, что, несмотря на то, что можно протестировать на переполнение буфера, Вы не можете протестировать на отсутствие переполнения буфера; необходимо, поэтому, тщательно проверить каждый ввод и каждое вычисление размера буфера в Вашем коде.
Для получения дополнительной информации о fuzzing посмотрите Fuzzing в Проверке Ввода и Межпроцессного взаимодействия.
Предотвращение недостаточных наполнений буфера
Существенно, когда две части Вашего кода не соглашаются о размере буфера или данных в том буфере, недостаточные наполнения буфера происходят. Например, переменная струны до фиксированной длины могла бы иметь пространство для 256 байтов, но могла бы содержать строку, которая только 12 байтов длиной.
Условия недостаточного наполнения буфера не всегда опасны; когда корректная работа зависит от обеих частей Вашего кода, обрабатывающего данные таким же образом, они становятся опасными. Это часто происходит при чтении буфера, чтобы скопировать его в другой блок памяти, отправить его через сетевое соединение, и т.д.
Существует два широких класса уязвимостей недостаточного наполнения буфера: короткие записи и короткие чтения.
Когда короткой записи к буферу не удается заполнить буфер полностью, происходит короткая уязвимость записи. Когда это происходит, некоторые данные, которые были ранее в буфере, все еще присутствуют после записи. Если приложение позже выполняет работу на всем буфере (запись его к диску или отправке его по сети, например), что существующие данные приходят для поездки. Данные могли быть случайными данными мусора, но если данные, оказывается, интересны, у Вас есть информационная утечка.
Далее, когда такая потеря значимости происходит, если значения в тех расположениях влияют на процесс выполнения программы, потеря значимости может потенциально вызвать неправильное поведение до, и включая разрешение Вам пропустить мимо аутентификации или авторизации продвигаются путем отъезда существующих данных авторизации по штабелю от предыдущего вызова другим пользователем, приложением или другим объектом.
Когда чтению от буфера не удается считать полное содержание буфера, происходит короткая уязвимость чтения. Если программа тогда принимает решения, на основе которых короткое чтение, может закончиться любое число ошибочных способов поведения. Это обычно происходит, когда функция струны до используется для чтения из буфера, фактически не содержащего допустимую струну до.
Струна до определяется как строка, содержащая ряд байтов, заканчивающийся нулевым разделителем. По определению это не может содержать нулевые байты до конца строки. В результате Струна до базировала функции, такой как strlen, strlcpy, и strdup, скопируйте строку пока первый нулевой разделитель и не не знайте о размере буфера первоисточника.
В отличие от этого, строки в других форматах (a CFStringRef объект, строка Паскаля или a CFDataRef блоб, например), имеют явную длину и может содержать нулевые байты в произвольных расположениях в данных. Если Вы преобразовываете такую строку в струну до и затем оцениваете ту струну до, Вы получаете неправильное поведение, потому что получающаяся струна до эффективно заканчивается в первом нулевом байте.
Если Вы соблюдаете следующие правила, необходимо быть в состоянии избежать большинства атак потери значимости:
Заполните нулями все буферы перед использованием. Буфер, содержащий только нули, не может содержать устаревшую уязвимую информацию.
Всегда проверяйте возвращаемые значения и сбой соответственно.
Если вызов к выделению или инициализации функционирует сбои (
AuthorizationCopyRights, например), не оценивайте получающиеся данные, поскольку это могло быть устаревшим.Используйте значение, возвращенное из
readсистемные вызовы и другие подобные вызовы для определения, сколько данных было фактически считано. Тогда также:Используйте тот результат определить, сколько данных присутствует вместо того, чтобы использовать предопределенную константу или
если функция не возвращала ожидаемый объем данных, перестали работать.
Выведите на экран ошибку и сбой если a
writeвызовите,printfвызовите, или другие выходные возвраты вызова, не пишущий все данные, особенно если Вы могли бы позже считать те данные назад.При работе со структур данных, содержащих информацию о длине, всегда проверяйте, что данные являются размером, который Вы ожидали.
Избегите преобразовывать неструны до (
CFStringRefобъекты,NSStringобъекты,CFDataRefобъекты, строки Паскаля, и т.д.) в струны до, если это возможно. Вместо этого работайте со строками в их исходном формате.Если это не возможно, всегда выполняйте длину, проверяет получающуюся струну до или проверку на нулевые байты в исходных данных.
Избегите смешивать буферные операции и строковые операции. Если это не возможно, всегда выполняйте длину, проверяет получающуюся струну до или проверку на нулевые байты в исходных данных.
Сохраните файлы способом, предотвращающим злонамеренное вмешательство или усечение. (См. Условия состязания и Защитите Операции Файла для получения дополнительной информации.)
Избегите целочисленных переполнений и потерь значимости. (См. Вычисление Буферных Размеров для подробных данных.)
Средства защиты, которые Могут Помочь
OS X и iOS обеспечивают две функции, которые могут сделать его тяжелее для использования переполнений стека и переполнения буфера: рандомизация расположения адресного пространства (ASLR) и неисполнимый штабель и «куча». Эти функции кратко объяснены в следующих разделах.
Рандомизация расположения адресного пространства
Последние версии OS X и iOS, если это возможно, выбирают различные расположения для Вашего штабеля, «кучи», библиотек, платформ и исполняемого кода каждый раз, когда Вы выполняете свое программное обеспечение. Это делает его намного тяжелее для успешного использования переполнения буфера, потому что больше не возможно знать, где буфер находится в памяти, и при этом не возможно знать, где расположены библиотеки и другой код.
Рандомизация расположения адресного пространства требует некоторой справки от компилятора — в частности, это требует позиционно-независимого кода.
Если Вы компилируете исполнимую программу, предназначающуюся для OS X v10.7 и позже (
-macosx_version_min) или IOS v4.3 и позже (-ios_version_min), необходимые флаги включены по умолчанию. Можно отключить эту опцию, при необходимости, с-no_pieфлаг, но для максимальной безопасности, Вы не должны делать так.Если Вы компилируете исполнимую программу, предназначающуюся для более раннего OS, необходимо явно включить позиционно-независимую исполнимую поддержку путем добавления
-pieфлаг.
Неисполнимый штабель и «куча»
Недавние процессоры поддерживают функцию, названную битом NX, позволяющим операционной системе отмечать определенные части памяти как неисполнимая программа. Если процессор пытается выполнить код в какой-либо странице памяти, отмеченной как неисполнимая программа, рассматриваемая программа отказывает.
OS X и iOS используют в своих интересах эту функцию путем маркировки штабеля и «кучи» как неисполнимая программа. Это делает атаки переполнения буфера тяжелее, потому что любая атака, помещающая исполняемый код в штабель или «кучу» и затем пытающаяся выполнить тот код, перестанет работать.
Большую часть времени это - поведение, которое Вы хотите. Однако в некоторых редких ситуациях (таких как запись своевременного компилятора), может быть необходимо изменить то поведение.
Существует два способа сделать исполнимая программа «кучи» и штабель:
Передайте
-allow_stack_executeотметьте к компилятору. Это делает штабель (не «куча») исполнимой программой.Используйте
mprotectсистемный вызов для маркировки определенных страниц памяти как исполнимую программу.
Подробные данные выходят за рамки этого документа. Для получения дополнительной информации см. страницу руководства для mprotect.
Отладка ошибок повреждения «кучи»
Чтобы помочь Вам отладить ошибки повреждения «кучи», можно использовать libgmalloc библиотека. Это обеспечивает дополнительное обнаружение переполнения с помощью защитных страниц и других методов. Для включения этой библиотеки введите следующую команду в Терминале:
export DYLD_INSERT_LIBRARIES=/usr/lib/libgmalloc.dylib |
Тогда выполните свое программное обеспечение от Терминала (или путем выполнения самой исполнимой программы или использования open команда). Для получения дополнительной информации см. страницу руководства для libgmalloc.