Spec-Zone .ru
спецификации, руководства, описания, API
|
|
Spec-Zone .ru
спецификации, руководства, описания, API
|
Этот раздел обсуждает способ, которым MySQL Cluster делит и копирует данные для хранения.
Много понятий, центральных к пониманию этой темы, обсуждаются в следующих немногих абзацах.
(Данные) Узел. Процесс ndbd, который хранит копию — то есть, копия раздела (см. ниже), присвоенный группе узла, которой узел является элементом.
Каждый узел данных должен быть расположен на отдельном компьютере. В то время как также возможно разместить многократные процессы ndbd на единственном компьютере, такая конфигурация не поддерживается.
Срокам "узел" и "узел данных" свойственно использоваться взаимозаменяемо, обращаясь к процессу ndbd; где упомянуто, узлы управления (ndb_mgmd процессы) и узлы SQL (mysqld процессы) определяются как таковые в этом обсуждении.
Node Group. Группа узла состоит из одного или более узлов, и хранит разделы, или наборы копий (см. следующий элемент).
Число групп узла в MySQL Cluster не непосредственно конфигурируемо; это - функция числа узлов данных и числа
копий (NoOfReplicas параметр конфигурации), как показано здесь:
[number_of_node_groups] =number_of_data_nodes/NoOfReplicas
Таким образом у MySQL Cluster с 4 узлами данных есть 4 группы узла если NoOfReplicas устанавливается в 1 в config.ini файл,
2 группы узла, если NoOfReplicas
устанавливается в 2, и 1 группа узла если NoOfReplicas устанавливается в 4. Копии обсуждаются позже в этом разделе; для
получения дополнительной информации о NoOfReplicas, см. Раздел
17.3.2.6, "Узлы данных Кластера MySQL Defining".
У всех групп узла в MySQL Cluster должно быть то же самое число узлов данных.
Можно добавить новые группы узла (и таким образом новые узлы данных) онлайн к рабочему MySQL Cluster; см. Раздел 17.5.13, "Узлы данных Кластера MySQL Adding Онлайн", для получения дополнительной информации.
Раздел. Это - часть данных, хранивших кластером. Есть так много разделов кластера как узлы, участвующие в кластере. Каждый узел ответственен за хранение по крайней мере одной копии любых разделов присвоенной этому (то есть, по крайней мере одна копия) доступный кластеру.
Копия принадлежит полностью единственному узлу; узел может (и обычно делает), хранят несколько копий.
NDB и определяемое
пользователем разделение. В то время как MySQL Cluster обычно разделы NDB таблицы автоматически, возможно использовать определяемое пользователем
разделение с NDB таблицы. Это подвергается следующим ограничениям:
Только KEY и LINEAR KEY
схемы выделения разделов могут использоваться с NDB таблицы.
При использовании ndbd, максимального количества разделов, которые могут
быть определены явно для любого NDB таблица 8 * [. (Число групп узла в MySQL Cluster определяется как обсуждено
ранее в этом разделе.) number
of node groups]
При использовании ndbmtd на этот максимум также влияет число локальных
потоков обработчика запроса, которое определяется значением MaxNoOfExecutionThreads параметр конфигурации. В таких случаях,
maxmimum числе разделов, которые могут быть определены явно для NDB таблица равна 4 *
MaxNoOfExecutionThreads * [. number of node
groups]
См. Раздел 17.4.3, "ndbmtd — (Многопоточный) MySQL Cluster Data Node Daemon", для получения дополнительной информации.
Для получения дополнительной информации касаясь MySQL Cluster и определяемого пользователем разделения, см. Раздел 17.1.6, "Известные Ограничения MySQL Cluster", и Раздел 18.6.2, "Деля Ограничения, Касающиеся Механизмов Хранения".
Копия. Это - копия раздела кластера. Каждый узел в группе узла хранит копию. Также иногда известный как копия раздела. Число копий равно числу узлов на группу узла.
Следующая схема иллюстрирует MySQL Cluster с четырьмя узлами данных, расположенными в двух группах узла двух узлов каждый; узлы 1 и 2 принадлежат группе узла 0, и узлы 3 и 4 принадлежат группе узла 1. Отметьте, что только данные (ndbd) узлы показывают здесь; хотя рабочий кластер требует, чтобы процесс ndb_mgm для управления кластером и по крайней мере одного узла SQL получил доступ к данным, хранившим кластером, они были опущены в числе для ясности.
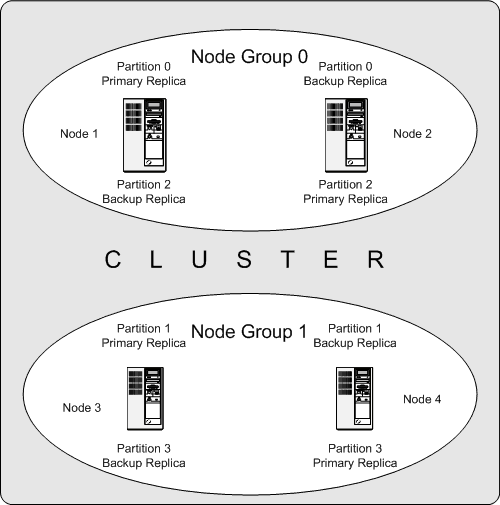
Данные, хранившие кластером, делятся на четыре раздела, пронумерованные 0, 1, 2, и 3. Каждый раздел сохранен — в многократных копиях — на той же самой группе узла. Разделы сохранены на альтернативных группах узла следующим образом:
Раздел 0 сохранен на группе узла 0; основная копия (основная копия) сохранена на узле 1, и резервная копия (резервная копия раздела) сохранена на узле 2.
Раздел 1 сохранен на другой группе узла (группа узла 1); основная копия этого раздела находится на узле 3, и его резервная копия находится на узле 4.
Раздел 2 сохранен на группе узла 0. Однако, размещение его двух копий инвертируется от того из Раздела 0; для Раздела 2, основная копия сохранена на узле 2, и резервное копирование на узле 1.
Раздел 3 сохранен на группе узла 1, и размещение ее двух копий инвертируется от таковых из раздела 1. Таким образом, его основная копия располагается на узле 4 с резервным копированием на узле 3.
То, что это означает относительно продолжительной работы MySQL Cluster, является этим: пока у каждой группы узла, участвующей в кластере, есть по крайней мере одна работа узла, кластер имеет полную копию всех данных и остается жизнеспособным. Это иллюстрируется в следующей схеме.
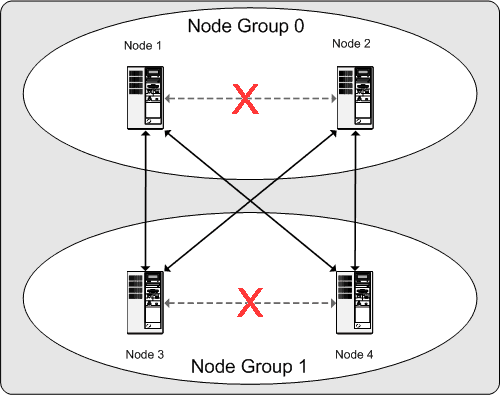
В этом примере, где кластер состоит из двух групп узла двух узлов каждый, любая комбинация по крайней мере одного узла в группе узла, 0 и по крайней мере один узел в группе узла 1 достаточен, чтобы поддержать кластер (обозначенный стрелками в схеме). Однако, если оба узла от любого группового сбоя узла, оставление двумя узлами не достаточно (показанный стрелками, размеченными с X); в любом случае кластер потерял весь раздел и так больше не может обеспечить доступ к полному набору всех данных кластера.