Spec-Zone .ru
спецификации, руководства, описания, API
|
|
Spec-Zone .ru
спецификации, руководства, описания, API
|
Этот раздел обсуждает, как выполнить прокручивающийся перезапуск установки MySQL Cluster, так называемой, потому что он включает остановку и запуск (или перезапуск) каждый узел поочередно, так, чтобы сам кластер остался операционным. Это часто делается как часть прокручивающегося обновления или прокручивающий упадок, где высокая доступность кластера обязательна, и никакое время простоя кластера в целом не допустимо. Где мы обращаемся к обновлениям, информация, предоставленная здесь также обычно, применяется к упадкам также.
Есть много причин, почему прокручивающийся перезапуск мог бы быть требуемым. Они описываются в следующих немногих абзацах.
Изменение конфигурации. Производить изменение в конфигурации кластера, такой как добавление узла SQL к кластеру, или установки параметра конфигурации к новому значению.
Обновление программного обеспечения MySQL Cluster или упадок. Обновить кластер до более новой версии программного обеспечения MySQL Cluster (или понизить это к более старой версии). Это обычно упоминается как "прокручивающееся обновление" (или "прокручивающий упадок", возвращаясь к более старой версии MySQL Cluster).
Изменение на узле узла. Производить изменения в системе аппаратного обеспечения или операционной системе, на которой работают или больше процессов узла MySQL Cluster.
Системный сброс (сброс кластера). Сбрасывать кластер, потому что это достигло нежелательного состояния. В таких случаях это является часто требуемым, чтобы перезагрузить данные и метаданные одного или более узлов данных. Это может быть сделано любым из трех способов:
Запустите каждый процесс узла данных (ndbd или возможно ndbmtd) с --initial опция, которая вынуждает узел данных очистить свою файловую
систему и перезагрузить все данные MySQL Cluster и метаданные от других узлов данных.
Создайте резервное копирование, используя ndb_mgm клиент BACKUP
команда до выполнения перезапуска. После обновления восстановите узел или узлы, используя ndb_restore.
См. Раздел 17.5.3, "Онлайновое Резервное копирование MySQL Cluster", и Раздел 17.4.18, "ndb_restore — Восстановление MySQL Cluster Backup", для получения дополнительной информации.
Используйте mysqldump, чтобы создать резервное копирование до
обновления; позже, восстановите использование дампа LOAD DATA INFILE.
Восстановление ресурса. К свободной памяти, ранее выделенной
таблице последовательным INSERT и DELETE
операции, для повторного использования другими таблицами MySQL Cluster.
Процесс для того, чтобы выполнить прокручивающийся перезапуск может быть обобщен следующим образом:
Остановите все узлы управления кластером (ndb_mgmd процессы), реконфигурируйте их, затем перезапустите их. (См. Прокручивающиеся перезапуски с многократными серверами управления.)
Остановите, реконфигурируйте, затем перезапустите каждый узел данных кластера (ndbd процесс) поочередно.
Остановите, реконфигурируйте, затем перезапустите каждый узел SQL кластера (mysqld процесс) поочередно.
Специфические особенности для того, чтобы реализовать данное прокручивающееся обновление зависят от произведенных изменений. Более подробный вид процесса представляется здесь:
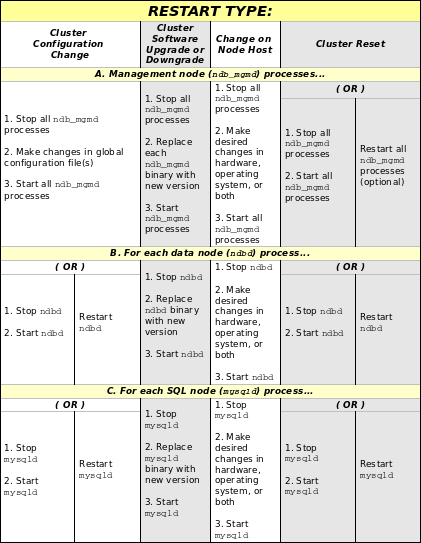
В предыдущей схеме, Остановке и Запускаются,
шаги указывают, что процесс должен быть остановлен, полностью используя команду оболочки (те, которые уничтожают
на большинстве систем Unix), или клиент управления STOP команда, затем запускался
снова с системной оболочки, вызывая ndbd или ndb_mgmd исполнимую программу как соответствующий. На
Windows можно также использовать систему NET START и NET
STOP команды или менеджер по службе Windows, чтобы запуститься и остановить узлы, которые были
установлены как службы Windows (см. Раздел
17.2.3.4, "Устанавливая MySQL Cluster Processes как Windows Services").
Перезапуск указывает, что процесс может быть перезапущен, используя ndb_mgm
клиент управления RESTART команда (см. Раздел
17.5.2, "Команды в MySQL Cluster Management Client").
MySQL Cluster поддерживает гибкий порядок на обновление узлов. Обновляя MySQL Cluster, можно обновить узлы API (включая узлы SQL) прежде, чем обновить узлы управления, узлы данных, или обоих. Другими словами Вам разрешают обновить API и узлы SQL в любом порядке. Это подвергается следующим условиям:
Эта функциональность предназначается для использования в качестве части онлайнового обновления только. Соединение двоичных файлов узла от различных выпусков MySQL Cluster ни не предназначается, ни поддерживается для непрерывного, долгосрочного использования в производственной установке.
Все узлы управления должны быть обновлены прежде, чем любые узлы данных обновляются. Это остается истиной независимо от порядка, в котором Вы обновляете API кластера и узлы SQL.
Функции, определенные для "новой" версии, не должны быть использованы, пока все узлы управления и узлы данных не были обновлены.
Это также применяется к любому изменению версии MySQL Server, которое может применяться, в дополнение к изменению версии механизма NDB, так что не забывайте принимать это во внимание, планируя обновление. (Это - истина для онлайновых обновлений MySQL Cluster вообще.)
См. также Ошибку #48528 и Ошибку #49163.
Прокрутка перезапусков с многократными серверами управления. Выполняя прокручивающийся перезапуск MySQL Cluster с многократными узлами управления, следует иметь в виду, что проверки ndb_mgmd, чтобы видеть, работает ли какой-либо другой узел управления, и, если так, пытаются использовать данные конфигурации того узла. Чтобы препятствовать этому происходить, и вынуждать ndb_mgmd перечитать свой конфигурационный файл, выполняют следующие шаги:
Остановите весь MySQL Cluster ndb_mgmd процессы.
Обновите все config.ini файлы.
Запустите единственный ndb_mgmd с --reload, --initial, или обе опции как требующийся.
Если Вы запустили первый ndb_mgmd с --initial опция, следует также запустить любого остающегося ndb_mgmd
использование процессов --initial.
Независимо от любых других опций, используемых, запуская первый ndb_mgmd, недопустимо запустить никого остающегося
ndb_mgmd процессы после первого использования --reload.
Завершите прокручивающиеся перезапуски узлов данных и узлов API как нормальные.
Выполняя прокручивающийся перезапуск, чтобы обновить конфигурацию кластера, можно использовать config_generation столбец ndbinfo.nodes таблица, чтобы отследить, из которых узлы данных были успешно
перезапущены с новой конфигурацией. См. Раздел 17.5.10.13,"
ndbinfo nodes Таблица".