Spec-Zone .ru
спецификации, руководства, описания, API
|
|
Spec-Zone .ru
спецификации, руководства, описания, API
|
Нет в настоящий момент никакого официального решения для того, чтобы обеспечить failover между ведущим устройством и ведомыми устройствами в случае отказа. С в настоящий момент доступными функциями необходимо бы установить ведущее устройство и ведомое устройство (или несколько ведомых устройств), и записать сценарий, который контролирует ведущее устройство, чтобы проверить, произошло ли это. Затем дайте команду своим приложениям и ведомым устройствам изменять ведущее устройство в случае отказа.
Помните, что можно сказать ведомому устройству изменять свое ведущее устройство в любое время, используя CHANGE MASTER TO оператор. Ведомое устройство не будет проверять, являются ли
базы данных на ведущем устройстве совместимыми с ведомым устройством, оно только начнет читать и выполнять
события от указанных двоичных координат журнала на новом ведущем устройстве. В failover ситуации все серверы в
группе обычно выполняют те же самые события от того же самого двоичного файла журнала, так изменение источника
событий не должно влиять на структуру базы данных или целостность, если Вы осторожны.
Выполните свои ведомые устройства с --log-bin опция и без --log-slave-updates. Таким образом ведомое устройство готово стать ведущим
устройством, как только Вы выходите STOP
SLAVE; RESET MASTER, и CHANGE MASTER TO оператор на других ведомых устройствах. Например,
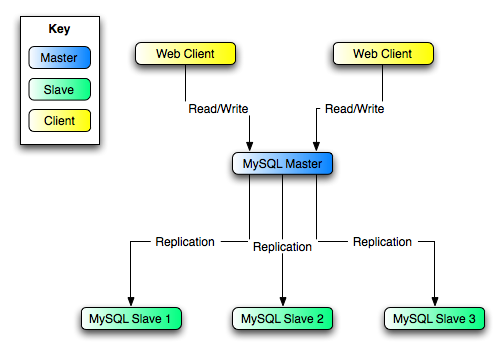
предположите, что Вам показали структуру в рисунке
16.4, "Избыточность Используя Репликацию, Начальная Структура".
В этой схеме, MySQL Master содержит основную базу данных, MySQL
Slave узлы являются ведомыми устройствами репликации, и Web Client машины
выпускают чтения базы данных и записи. Веб-клиенты, которые выпускают только чтения (и обычно соединялся бы с
ведомыми устройствами) не показывают, поскольку они не должны переключиться на новый сервер в случае отказа. Для
более подробного примера структуры репликации масштаба чтения-записи см. Раздел
16.3.3, "Используя Репликацию для Масштаба".
Каждый MySQL Slave (Slave 1, Slave 2, и Slave 3) ведомое устройство, работающее с --log-bin и без --log-slave-updates. Поскольку обновления, полученные ведомым устройством от
ведущего устройства, не зарегистрированы двоичный журнал если --log-slave-updates определяется, двоичный файл входят в систему, каждое
ведомое устройство пусто первоначально. Если по некоторым причинам MySQL Master
становится недоступным, можно выбрать одно из ведомых устройств, чтобы стать новым ведущим устройством.
Например, если Вы выбираете Slave 1, все Web Clients
должен быть перенаправлен к Slave 1, который зарегистрирует обновления к его
двоичному журналу. Slave 2 и Slave 3 должен тогда
тиражироваться от Slave 1.
Причина выполнения ведомого устройства без --log-slave-updates должен препятствовать тому, чтобы ведомые устройства получили
обновления дважды в случае, если Вы заставляете одно из ведомых устройств становиться новым ведущим устройством.
Предположите это Slave 1 имеет --log-slave-updates включенный. Затем это запишет обновления, из которых это
получает Master к его собственному двоичному журналу. Когда Slave
2 изменения от Master к Slave 1 как его
ведущее устройство, это может получить обновления из Slave 1 то, что это уже
получило из Master
Удостоверьтесь, что все ведомые устройства обработали любые операторы в своем релейном журнале. На каждом
ведомом устройстве, проблеме STOP SLAVE IO_THREAD, тогда проверьте вывод SHOW PROCESSLIST пока Вы не видите Has read all relay
log. Когда это - истина для всех ведомых устройств, они могут быть реконфигурированы к новой
установке. На ведомом устройстве Slave 1 будучи продвинутым, чтобы стать ведущим
устройством, проблемой STOP SLAVE и RESET MASTER.
На других ведомых устройствах Slave 2 и Slave 3,
использовать STOP SLAVE и CHANGE MASTER TO
MASTER_HOST='Slave1' (где 'Slave1' представляет реальное имя хоста Slave 1). Использовать CHANGE MASTER TO, добавьте всю информацию о том, как соединиться с Slave 1 от Slave 2 или Slave
3 (user, password,
port). В CHANGE MASTER TO, нет никакой потребности определить имя Slave 1 двоичный файл журнала или позиция журнала, чтобы читать из: Мы знаем, что
это - первый двоичный файл журнала и позиция 4, которые являются значениями по умолчанию для CHANGE MASTER TO. Наконец, использовать START SLAVE на Slave 2 и Slave
3.
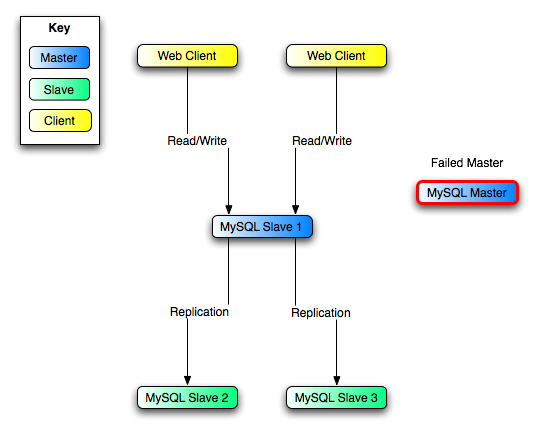
Как только новая репликация на месте, Вы должны будете тогда сообщить каждому Web
Client направить его операторы к Slave 1. От той точки на, все операторы
обновлений, отправленные Web Client к Slave 1 пишутся
двоичному журналу Slave 1, который тогда содержит каждый оператор обновления,
отправленный Slave 1 с тех пор Master умерший.
Получающуюся структуру сервера показывают в рисунке 16.5, "Избыточность Используя Репликацию, После Основного Отказа".
Когда Master произошел снова, следует выпустить на этом то же самое CHANGE MASTER TO как выпущенное на Slave 2 и Slave 3, так, чтобы Master становится ведомым
устройством S1 и подбирает каждого Web Client записи,
которые это пропустило, в то время как это снижалось.
Сделать Master ведущее устройство снова (например, потому что это - самая мощная
машина), использует предыдущую процедуру как будто Slave 1 было недоступно и Master должно было быть новое ведущее устройство. Во время этой процедуры не
забывайте работать RESET MASTER на
Master перед созданием Slave 1, Slave
2, и Slave 3 ведомые устройства Master.
Иначе, они могут поднять старый Web Client записи те, до точки, в который Master стал недоступным.
Отметьте, что нет никакой синхронизации между различными ведомыми устройствами ведущего устройства. Некоторые ведомые устройства могли бы быть перед другими. Это означает, что понятие, обрисованное в общих чертах в предыдущем примере, не могло бы работать. Практически, однако, релейные журналы различных ведомых устройств наиболее вероятно не будут далеки позади ведущего устройства, таким образом, это работало бы, так или иначе (но нет никакой гарантии).
Хороший способ держать Ваши приложения в курсе относительно расположения ведущего устройства при наличии
динамической записи DNS для ведущего устройства. С bind можно использовать nsupdate динамически обновить Ваш DNS.