Spec-Zone .ru
спецификации, руководства, описания, API
|
|
Spec-Zone .ru
спецификации, руководства, описания, API
|
Могут быть ситуации, где Вы имеете единственное ведущее устройство и хотите тиражировать различные базы данных в различные ведомые устройства. Например, можно хотеть распределить различные данные о сбыте различным отделам, чтобы помочь распространить загрузку во время анализа данных. Выборку этого расположения показывают в рисунке 16.2, "Используя Репликацию, чтобы Тиражировать Базы данных, чтобы Разделить Ведомые устройства Репликации".
Рисунок 16.2. Используя Репликацию, чтобы Тиражировать Базы данных, чтобы Разделить Ведомые устройства Репликации
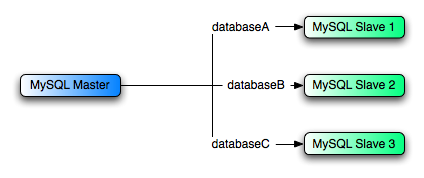
Можно достигнуть этого разделения, конфигурируя ведущее устройство и ведомые устройства как нормального, и затем
ограничивая двоичные операторы журнала, которые каждое ведомое устройство обрабатывает при использовании --replicate-wild-do-table
параметр конфигурации на каждом ведомом устройстве.
Недопустимо использовать --replicate-do-db с этой целью при использовании основанной на операторе
репликации, начиная с основанных на операторе причин репликации эта опция влияет, чтобы измениться согласно
базе данных, которая в настоящий момент выбирается. Это применяется к репликации смешанного формата также,
так как это позволяет некоторым обновлениям быть тиражированными, используя основанный на операторе формат.
Однако, должно быть безопасно использовать --replicate-do-db с этой целью, если Вы используете построчную репликацию
только, так как в этом случае в настоящий момент выбранная база данных не имеет никакого эффекта на работу
опции.
Например, чтобы поддерживать разделение как показано в рисунке
16.2, "Используя Репликацию, чтобы Тиражировать Базы данных, чтобы Разделить Ведомые устройства Репликации",
следует сконфигурировать каждое ведомое устройство репликации следующим образом перед выполнением START SLAVE:
Ведомое устройство репликации 1 должно использовать --replicate-wild-do-table=databaseA.%.
Ведомое устройство репликации 2 должно использовать --replicate-wild-do-table=databaseB.%.
Ведомое устройство репликации 3 должно использовать --replicate-wild-do-table=databaseC.%.
Каждое ведомое устройство в этой конфигурации получает весь двоичный журнал от ведущего устройства, но выполняет
только те события от двоичного журнала, которые применяются к базам данных и таблицам, включенным --replicate-wild-do-table
опция в действительности на том ведомом устройстве.
Если у Вас есть данные, которые должны синхронизироваться с ведомыми устройствами прежде, чем репликация запустится, у Вас есть много вариантов:
Синхронизируйте все данные с каждым ведомым устройством, и удалите базы данных, таблицы, или обоих, что Вы не хотите сохранять.
Используйте mysqldump, чтобы создать отдельный файл дампа для каждой базы данных и загрузить соответствующий файл дампа на каждом ведомом устройстве.
Используйте дамп файла необработанных данных и включайте только определенные файлы и базы данных, в которых Вы нуждаетесь для каждого ведомого устройства.
Это не работает с InnoDB
базы данных, если Вы не используете innodb_file_per_table.