Spec-Zone .ru
спецификации, руководства, описания, API
|
|
Spec-Zone .ru
спецификации, руководства, описания, API
|
| Contents | Prev | Next | JDBCTM Guide: Getting Started |
See also the rejected "Holder" mechanism described in Appendix A.
// We're going to execute a SQL statement that will return a
// collection of rows, with column 1 as an int, column 2 as
// a String, and column 3 as an array of bytes.
java.sql.Statement stmt = conn.createStatement();
ResultSet r = stmt.executeQuery("SELECT a, b, c FROM Table1");
while (r.next()) {
// print the values for the current row.
int i = r.getInt("a");
String s = r.getString("b");
byte b[] = r.getBytes("c");
System.out.println("ROW = " + i + " " + s + " " + b[0]);
}
Reviewer input convinced us that we had to support both column indexes and column names. Some reviewers were extremely emphatic that they require highly efficient database access and therefore preferred column indexes, other reviewers insisted that they wanted the convenience of using column names. (Note that certain SQL queries can return tables without column names or with multiple identical column names. In these cases, programmers should use column numbers.)
For maximum portability, columns within a row should be read in left-to-right order, and each column should only be read once. This reflects implementation limitations in some underlying database protocols.
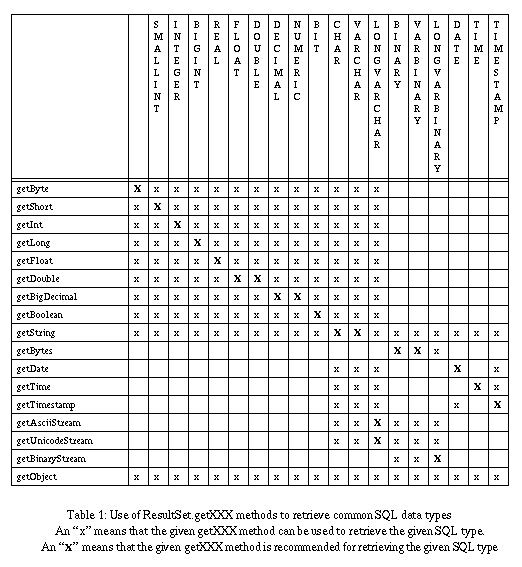
Table 1 on page 21 lists the supported conversions from SQL types to Java types via getXXX methods. For example, it is possible to attempt to read a SQL VARCHAR value as an integer using getInt, but it is not possible to read a SQL FLOAT as a java.sql.Date.
If you attempt an illegal conversion, or if a data conversion fails (for example if you did a getInt on a SQL VARCHAR value of "foo"), then a SQLException will be raised.
When you read a SQL "NULL" using one of the ResultSet.getXXX methods, you will receive:
To accommodate this, the ResultSet class can return java.io.Input streams from which data can be read in chunks. However each of these streams must be accessed immediately as they will be automatically closed on the next "get" call on the ResultSet. This behavior reflects underlying implementation constraints on large blob access.
Java streams return untyped bytes and can (for example) be used for both ASCII and Unicode. We define three separate methods for getting streams. GetBinaryStream returns a stream which simply provides the raw bytes from the database without any conversion. GetAsciiStream returns a stream which provides one byte ASCII characters. GetUnicodeStream returns a stream which provides 2 byte Unicode characters.
java.sql.Statement stmt = conn.createStatement();
ResultSet r = stmt.executeQuery("SELECT x FROM Table2");
// Now retrieve the column 1 results in 4 K chunks:
byte[] buff = new byte[4096];
while (r.next()) {
java.io.InputStream fin = r.getAsciiStream("x");
for (;;) {
int size = fin.read(buff);
if (size == -1) {
break;
}
// Send the newly filled buffer to some ASCII output stream:
output.write(buff, 0, size);
}
}
However under some circumstances an application may not know whether a given statement will return a ResultSet until the statement has executed. In addition, some stored procedures may return several different ResultSets and/or update counts.
To accommodate these needs we provide a mechanism so that an application can execute a statement and then process an arbitrary collection of ResultSets and update counts. This mechanism is based on a fully general "execute" method, supported by three other methods, getResultSet, getUpdateCount, and getMoreResults. These methods allow an application to explore the statement results one at a time and to determine if a given result was a ResultSet or an update count.
java.sql.PreparedStatement stmt = conn.prepareStatement(
"UPDATE table3 SET m = ? WHERE x = ?");
// We pass two parameters. One varies each time around the for loop,
// the other remains constant.
stmt.setString(1, "Hi");
for (int i = 0; i < 10; i++) {
stmt.setInt(2, i);
int rows = stmt.executeUpdate();
}
It is the programmer's responsibility to make sure that the java type of each argument maps to a SQL type that is compatible with the SQL data type expected by the database. For maximum portability programmers, should use Java types that correspond to the exact SQL types expected by the database.
If programmers require data type conversions for IN parameters, they may use the PreparedStatement.setObject method which converts a Java Object to a specified SQL type before sending the value to the database.
In addition, for those setXXX methods that take Java objects as arguments, if a Java null value is passed to a setXXX method, then a SQL NULL will be sent to the database.
To accommodate this, we allow programmers to supply Java IO streams as parameters. When the statement is executed the JDBC driver will make repeated calls on these IO streams to read their contents and transmit these as the actual parameter data.
Separate setXXX methods are provided for streams containing uninterpreted bytes, for streams containing ASCII characters, and for streams containing Unicode characters.
When setting a stream as an input parameter, the application programmer must specify the number of bytes to be read from the stream and sent to the database.
We dislike requiring that the data transfer size be specified in advance; however, this is necessary because some databases need to know the total transfer size in advance of any data being sent.
An example of using a stream to send the contents of a file as an IN parameter:
java.io.File file = new java.io.File("/tmp/foo");
int fileLength = file.length();
java.io.InputStream fin = new java.io.FileInputStream(file);
java.sql.PreparedStatement stmt = conn.prepareStatement(
"UPDATE Table5 SET stuff = ? WHERE index = 4");
stmt.setBinaryStream(1, fin, fileLength);
// When the statement executes, the "fin" object will get called
// repeatedly to deliver up its data.
stmt.executeUpdate();
To pass in any IN parameters you can use the setXXX methods defined in PreparedStatement as described in Section 7.2 above.
However, if your stored procedure returns OUT parameters, then for each OUT parameter you must use the CallableStatememt.registerOutParameter method to register the SQL type of the OUT parameter before you execute the statement. (See Appendix A.6.) Then after the statement has executed, you must use the corresponding CallableStatement.getXXX method to retrieve the parameter value.
java.sql.CallableStatement stmt = conn.prepareCall(
"{call getTestData(?, ?)}");
stmt.registerOutParameter(1,java.sql.Types.TINYINT);
stmt.registerOutParameter(2,java.sql.types.DECIMAL, 2);
stmt.executeUpdate();
byte x = stmt.getByte(1);
BigDecimal n = stmt.getBigDecimal(2,2);
When you read a SQL "NULL" value using one of the CallableStatement.getXXX methods, you will receive a value of null, zero, or false, following the same rules specified in section 7.1.2 for the ResultSet.getXXX methods.
Instead we recommend that programmers retrieve very large values through ResultSets.
If data truncation occurs during a read from a ResultSet then a DataTruncation object (a subtype of SQLWarning) will get added to the ResultSet's warning list and the method will return as much data as it was able to read. Similarly, if a data truncation occurs while an OUT parameter is being received from the database, then a DataTruncation object will get added to the CallableStatement's warning list and the method will return as much data as it was able to read.