Spec-Zone .ru
спецификации, руководства, описания, API
|
|
Spec-Zone .ru
спецификации, руководства, описания, API
|
ГЛАВА 3
Эта глава определяет лексическую структуру Java.
Программы Java пишутся в Unicode (§3.1), но лексическим преобразованиям обеспечивают (§3.2) так, чтобы (§3.3) Escape Unicode мог использоваться, чтобы включать любой символ Unicode использование только символов ASCII. Разделители строки определяются (§3.4), чтобы поддерживать различные соглашения существующих хост-систем, поддерживая непротиворечивые номера строки.
Символы Unicode, следующие из лексических преобразований, уменьшаются до последовательности входных элементов (§3.5), которые являются пробелом (§3.6), комментарии (§3.7), и маркеры. Маркеры являются идентификаторами (§3.8), ключевые слова (§3.9), литералы (§3.10), разделители (§3.11), и операторы (§3.12) Java синтаксическая грамматика.
Версии Java до 1.1 используемых версий 1.1.5 Unicode (см. Стандарт Unicode: Глобальная Кодировка символов (§1.2) и обновления). См. §20.5 для обсуждения различий между версией 1.1.5 Unicode и версией 2.0 Unicode.http://www.unicode.organdftp://unicode.org
За исключением комментариев (§3.7), идентификаторы, и содержание символьных и строковых литералов (§3.10.4, §3.10.5), все входные элементы (§3.5) в программе Java формируются только из символов ASCII (или Escape Unicode (§3.3), которые приводят к символам ASCII). ASCII (ANSI X3.4) является Стандартный американский код обмена информацией. Первые 128 символов кодировки символов Unicode являются символами ASCII.
\uxxxx, где xxxx является шестнадцатеричным значением, представляет символ Unicode, кодирование которого является xxxx. Этот шаг преобразования позволяет любой программе Java быть выраженной, используя только символы ASCII.
a--b маркируются (§3.5) как a, --, b, который не является частью любой грамматически корректной программы Java, даже при том, что tokenization a, -, -, b могла быть часть грамматически корректной программы Java.\u сопровождаемый четырьмя шестнадцатеричными цифрами к символу Unicode с обозначенным шестнадцатеричным значением, и передающий все другие неизменные символы. Этот шаг преобразования приводит к последовательности входных символов Unicode: UnicodeInputCharacter:
UnicodeEscape
RawInputCharacter UnicodeEscape:
\UnicodeMarkerHexDigitHexDigitHexDigitHexDigit UnicodeMarker:
uUnicodeMarker
uRawInputCharacter:
any Unicode character HexDigit: one of
0 1 2 3 4 5 6 7 8 9 a b c d e f A B C D E F
\, u, и шестнадцатеричные цифры здесь являются всеми символами ASCII.
В дополнение к обработке, подразумеваемой грамматикой, для каждого необработанного входного символа, который является наклонной чертой влево \, входная обработка должна рассмотреть сколько другой \ символы рядом предшествуют этому, разделяя это от не -\ символ или запуск входного потока. Если это число даже, то \ имеет право начать escape Unicode; если число нечетно, то \ не имеет право начать escape Unicode. Например, необработанный ввод "\\u2297=\u2297" результаты в этих одиннадцати символах " \ \ u 2 2 9 7 = 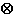
" (\u2297 кодирование Unicode символа""),.
Если имеющее право \ не сопровождается u, тогда это обрабатывается как RawInputCharacter и остается частью оставленного потока Unicode. Если имеющее право \ сопровождается u, или больше чем один u, и последнее u не сопровождается четырьмя шестнадцатеричными цифрами, затем ошибка времени компиляции происходит.
Символ, произведенный escape Unicode, не участвует в дальнейших Escape Unicode. Например, необработанный ввод \u005cu005a результаты в этих шести символах \ u 0 0 5 a, потому что 005c значение Unicode для \. Это не приводит к символу Z, который является символом Unicode 005a, потому что \ это следовало \u005c не интерпретируется как запуск дальнейшего escape Unicode.
Java определяет стандартный способ преобразовать программу Java Unicode в ASCII, который изменяет программу Java в форму, которая может быть обработана основанными на ASCII инструментами. Преобразование включает преобразование любых Escape Unicode в исходный текст программы к ASCII, добавляя дополнительное u- например, \uxxxx становится \uuxxxx-в-то-время-как одновременно преобразовывая символы неASCII в исходном тексте к a \uescape xxxx, содержащий сингл u. Эта преобразованная версия является одинаково приемлемой для компилятора Java и представляет ту же самую программу. Точный источник Unicode может позже быть восстановлен от этой формы ASCII, преобразовывая каждую escape-последовательность где кратное число u's присутствуют к последовательности символов Unicode с одним меньше u, одновременно преобразовывая каждую escape-последовательность с синглом u к соответствующему единственному символу Unicode.
Системы Java должны использовать \uнотация xxxx как выходной формат, чтобы вывести на экран символы Unicode, когда подходящий шрифт не доступен.
// форма комментария (§3.7). LineTerminator:Строки завершаются символами ASCII CR, или LF, или CR LF. Эти два символа CR, сразу сопровождаемый LF, считаются как один разделитель строки, не два. Результатом является последовательность разделителей строки и входных символов, которые являются терминальными символами для третьего шага в процессе tokenization.
the ASCII LF character, also known as "newline"
the ASCII CR character, also known as "return"
the ASCII CR character followed by the ASCII LF character InputCharacter:
UnicodeInputCharacter but not CR or LF
Этот процесс определяется следующим производством:
Input:Пробел (§3.6) и комментарии (§3.7) может служить, чтобы разделить маркеры, которые, если смежный, могли бы маркироваться другим способом. Например, символы ASCII
InputElementsoptSubopt InputElements:
InputElement
InputElementsInputElement InputElement:
WhiteSpace
Comment
Token Token:
Identifier
Keyword
Literal
Separator
Operator Sub:
the ASCII SUB character, also known as "control-Z"
- и = во вводе может сформировать маркер оператора -= (§3.12), только если нет никакого прошедшего пробела или комментария.
Как специальная концессия для совместимости с определенными операционными системами, ASCII символ SUB (\u001a, или управление-Z), игнорируется, если это - последний знак в оставленном входном потоке.
Рассмотрите два маркера x и y в получающемся входном потоке. Если x предшествует y, то мы говорим, что x налево от y и что y направо от x. Например, в этой простой части кода Java:
class Empty {
}
мы говорим что } маркер направо от { маркер, даже при том, что это появляется, в этом двумерном представлении на бумаге, вниз и налево от { маркер. Это соглашение об использовании левых и правых слов позволяет нам говорить, например, правого операнда бинарного оператора или левой стороны присвоения. WhiteSpace:
the ASCII SP character, also known as "space"
the ASCII HT character, also known as "horizontal tab"
the ASCII FF character, also known as "form feed"
LineTerminator
/* текст */ Традиционный комментарий: весь текст от символов ASCII /* к символам ASCII */ игнорируется (как в C и C++).
// текст однострочный комментарий: весь текст от символов ASCII // до конца строки игнорируется (как в C++).
/** документация */ Комментарий для документации: текст включается символами ASCII /** и */ может быть обработан отдельным инструментом, чтобы подготовить автоматически сгенерированную документацию следующего класса, интерфейса, конструктора, или элемента (метод или поле) объявление. См. §18 для полного описания того, как предоставленная документация обрабатывается.
Эти комментарии формально определяются следующим производством:
Comment:Это производство подразумевает все следующие свойства:
TraditionalComment
EndOfLineComment
DocumentationComment TraditionalComment:
/ *NotStarCommentTail EndOfLineComment:
/ /CharactersInLineoptLineTerminator DocumentationComment:
/ * *CommentTailStar CommentTail:
*CommentTailStar
NotStarCommentTail CommentTailStar:
/CommentTailStar
*
NotStarNotSlashCommentTail NotStar:
InputCharacter but not*LineTerminator NotStarNotSlash:
InputCharacter but not*or/LineTerminator CharactersInLine:
InputCharacter
CharactersInLineInputCharacter
/* и */ не имейте никакого особого значения в комментариях, которые начинаются //.
// не имеет никакого особого значения в комментариях, которые начинаются /* или /**. /* this comment /* // /** ends here: */
единственный полный комментарий. Лексическая грамматика подразумевает, что комментарии не происходят в пределах символьных литералов (§3.10.4) или строковые литералы (§3.10.5).
Отметьте это /**/ как полагают, комментарий для документации, в то время как /* */ (с пространством между звездочками), традиционный комментарий.
Identifier:Буквы и цифры могут быть оттянуты из всего набора символов Unicode, который поддерживает большинство сценариев записи в использовании в мире сегодня, включая большие наборы для китайского, японского, и корейского языка. Это позволяет программистам Java использовать идентификаторы в своих программах, которые пишутся на их родных языках.
IdentifierChars but not a Keyword or BooleanLiteral or NullLiteral IdentifierChars:
JavaLetter
IdentifierCharsJavaLetterOrDigit JavaLetter:
any Unicode character that is a Java letter (see below) JavaLetterOrDigit:
any Unicode character that is a Java letter-or-digit (see below)
Буква Java является символом для который метод Character.isJavaLetter (§20.5.17) возвраты true. Java "буква или цифра" является символом для который метод Character.isJavaLetterOrDigit (§20.5.18) возвраты true.
Буквы Java включают прописные и строчные латинские буквы ASCII A-Z (\u0041-\u005a), и a-z (\u0061-\u007a), и, по историческим причинам, подчеркивание ASCII (_, или \u005f) и знак доллара ($, или \u0024). $ символ должен использоваться только в механически сгенерированном коде Java или, редко, к доступу, существующему ранее имена на унаследованных системах.
Цифры Java включают цифры ASCII 0-9 (\u0030-\u0039).
Два идентификатора являются тем же самым, только если они идентичны, то есть, имейте тот же самый символ Unicode для каждой буквы или цифры.
Идентификаторы, у которых есть то же самое внешнее появление, могут все же отличаться. Например, идентификаторы, состоящие из ЛАТИНСКОЙ ПРОПИСНОЙ БУКВЫ A одних букв (A, \u0041), ЛАТИНСКАЯ СТРОЧНАЯ БУКВА (a, \u0061), ГРЕЧЕСКАЯ АЛЬФА ПРОПИСНОЙ БУКВЫ (A, \u0391), и КИРИЛЛИЧЕСКАЯ СТРОЧНАЯ БУКВА (a, \u0430) все отличаются.
Символы составного объекта Unicode отличаются от анализируемых символов. Например, ЛАТИНСКАЯ ПРОПИСНАЯ БУКВА ОСТРОЕ (Á, \u00c1) как могли полагать, был тем же самым как ЛАТИНСКОЙ ПРОПИСНОЙ БУКВОЙ A (A, \u0041) сразу сопровождаемый ОСТРЫМ БЕЗ ИНТЕРВАЛОВ (´, \u0301) сортируя, но они отличаются в идентификаторах Java. См. Стандарт Unicode, Объем 1, страницы 412ff для деталей о разложении, и см. страницы 626-627 той работы для деталей о сортировке.
String i3MAX_VALUE isLetterOrDigit
Keyword: one ofКлючевые слова
abstract default if private throw
boolean do implements protected throws
break double import public transient
byte else instanceof return try
case extends int short void
catch final interface static volatile
char finally long super while
class float native switch
const for new synchronized
continue goto package this
const и goto резервируются Java, даже при том, что они в настоящий момент не используются в Java. Это может позволить компилятору Java производить лучшие сообщения об ошибках, если эти ключевые слова C++ неправильно появляются в программах Java.
В то время как true и false могло бы казаться, был бы ключевыми словами, они - технически Булевы литералы (§3.10.3). Точно так же, в то время как null могло бы казаться, был бы ключевым словом, это - технически нулевой литерал (§3.10.7).
String введите (§4.3.3, §20.12), или нулевой тип (§4.1): Literal:
IntegerLiteral
FloatingPointLiteral
BooleanLiteral
CharacterLiteral
StringLiteral
NullLiteral
Целочисленный литерал может быть выражен в десятичном числе (базируйтесь 10), шестнадцатеричный (базируются 16), или восьмеричный (базируются 8):
IntegerLiteral:Целочисленный литерал имеет тип
DecimalIntegerLiteral
HexIntegerLiteral
OctalIntegerLiteral DecimalIntegerLiteral:
DecimalNumeralIntegerTypeSuffixopt HexIntegerLiteral:
HexNumeralIntegerTypeSuffixopt OctalIntegerLiteral:
OctalNumeralIntegerTypeSuffixopt IntegerTypeSuffix: one of
l L
long если это снабжается суффиксом букву ASCII L или l (эль); иначе это имеет тип int (§4.2.1). Суффикс L предпочитается, потому что буква l (эль) часто трудно отличить от цифры 1 (один).
Десятичная цифра является любой единственным символом ASCII 0, представление целочисленного нуля, или состоит из цифры ASCII от 1 к 9, дополнительно сопровождаемый одной или более цифрами ASCII от 0 к 9, представление положительного целого числа:
DecimalNumeral:Шестнадцатеричная цифра состоит из ведущих символов ASCII
0NonZeroDigit
Digitsopt Digits:
Digit
DigitsDigit Digit:
0NonZeroDigit NonZeroDigit: one of
1 2 3 4 5 6 7 8 9
0x или 0X сопровождаемый одним или более ASCII шестнадцатеричные цифры и может представить положительное, нуль, или отрицательное целое число. Шестнадцатеричные цифры со значениями 10 - 15 представляются буквами ASCII a через f или A через F, соответственно; каждая буква, используемая в качестве шестнадцатеричной цифры, может быть прописной или строчной.
HexNumeral:Следующее производство от §3.3 повторяется здесь для ясности:
0 xHexDigit
0 XHexDigit
HexNumeralHexDigit
HexDigit: one ofВосьмеричная цифра состоит из цифры ASCII
0 1 2 3 4 5 6 7 8 9 a b c d e f A B C D E F
0 сопровождаемый один или больше цифр ASCII 0 через 7 и может представить положительное, нуль, или отрицательное целое число.
OctalNumeral:Отметьте, что восьмеричные цифры, всегда состоят из двух или больше цифр;
0OctalDigit
OctalNumeralOctalDigit OctalDigit: one of
0 1 2 3 4 5 6 7
0 как всегда полагают, десятичная цифра - не, что она имеет значение очень практически для цифр 0, 00, и 0x0 все представляют точно то же самое целочисленное значение.
Самый большой десятичный литерал типа int 2147483648 (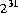 ). Все десятичные литералы от
). Все десятичные литералы от 0 к 2147483647 может появиться где угодно int литерал может появиться, но литерал 2147483648 может появиться только как операнд унарного оператора отрицания -.
Самые большие положительные шестнадцатеричные и восьмеричные литералы типа int 0x7fffffff и 017777777777, соответственно, который равный 2147483647 (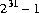 ). Самые отрицательные шестнадцатеричные и восьмеричные литералы типа
). Самые отрицательные шестнадцатеричные и восьмеричные литералы типа int 0x80000000 и 020000000000, соответственно, каждый из которых представляет десятичное значение -2147483648 (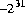 ). Шестнадцатеричные и восьмеричные литералы
). Шестнадцатеричные и восьмеричные литералы 0xffffffff и 037777777777, соответственно, представьте десятичное значение -1.
См. также Integer.MIN_VALUE (§20.7.1) и Integer.MAX_VALUE (§20.7.2).
Ошибка времени компиляции происходит если десятичный литерал типа int больше чем 2147483648 (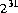 ), или если литерал
), или если литерал 2147483648 появляется где угодно кроме как операнд унарного - оператор, или если шестнадцатеричное или восьмеричное int литерал не помещается в 32 бита.
0 2 0372 0xDadaCafe 1996 0x00FF00FFСамый большой десятичный литерал типа
long 9223372036854775808L (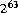 ). Все десятичные литералы от
). Все десятичные литералы от 0L к 9223372036854775807L может появиться где угодно a long литерал может появиться, но литерал 9223372036854775808L может появиться только как операнд унарного оператора отрицания -.
Самые большие положительные шестнадцатеричные и восьмеричные литералы типа long 0x7fffffffffffffffL и 0777777777777777777777L, соответственно, который равный 9223372036854775807L (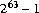 ). Литералы
). Литералы 0x8000000000000000L и 01000000000000000000000L являются самыми отрицательными long шестнадцатеричные и восьмеричные литералы, соответственно. У каждого есть десятичное значение -9223372036854775808L (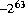 ). Шестнадцатеричные и восьмеричные литералы
). Шестнадцатеричные и восьмеричные литералы 0xffffffffffffffffL и 01777777777777777777777L, соответственно, представьте десятичное значение -1L.
См. также Long.MIN_VALUE (§20.8.1) и Long.MAX_VALUE (§20.8.2).
Ошибка времени компиляции происходит если десятичный литерал типа long больше чем 9223372036854775808L (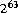 ), или если литерал
), или если литерал 9223372036854775808L появляется где угодно кроме как операнд унарного - оператор, или если шестнадцатеричное или восьмеричное long литерал не помещается в 64 бита.
0l 0777L 0x100000000L 2147483648L 0xC0B0L
У литерала с плавающей точкой есть следующие части: часть целого числа, десятичная точка (представленный символом точки ASCII), дробная часть, экспонента, и суффикс типа. Экспонента, если есть обозначается буквой ASCII e или E сопровождаемый дополнительно целым числом со знаком.
По крайней мере одна цифра, или в целом числе или в дробной части, и или десятичная точка, экспонента, или суффикс типа плавающий требуется. Все другие части являются дополнительными.
Литерал с плавающей точкой имеет тип float если это снабжается суффиксом букву ASCII F или f; иначе его тип double и это может дополнительно быть снабжено суффиксом букву ASCII D или d.
FloatingPointLiteral:Типы Java
Digits.DigitsoptExponentPartoptFloatTypeSuffixopt
.DigitsExponentPartoptFloatTypeSuffixopt
DigitsExponentPartFloatTypeSuffixopt
DigitsExponentPartoptFloatTypeSuffix ExponentPart:
ExponentIndicatorSignedInteger ExponentIndicator: one of
e ESignedInteger:
SignoptDigits Sign: one of
+ -FloatTypeSuffix: one of
f F d D
float и double IEEE 754 32-разрядная одинарная точность и 64-разрядный двоичный файл двойной точности значения с плавающей точкой, соответственно.
Детали надлежащего входного преобразования из строкового представления Unicode числа с плавающей точкой к внутреннему двоичному файлу IEEE 754 представление с плавающей точкой описываются для методов valueOf из класса Float (§20.9.17) и класс Double (§20.10.16) пакета java.lang.
Самое большое положительное конечное float литерал 3.40282347e+38f. Самый маленький положительный конечный ненулевой литерал типа float 1.40239846e-45f. Самое большое положительное конечное double литерал 1.79769313486231570e+308. Самый маленький положительный конечный ненулевой литерал типа double 4.94065645841246544e-324.
См. Float.MIN_VALUE (§20.9.1) и Float.MAX_VALUE (§20.9.2); см. также Double.MIN_VALUE (§20.10.1) и Double.MAX_VALUE (§20.10.2).
Ошибка времени компиляции происходит, если ненулевой литерал с плавающей точкой является слишком большим, так, чтобы на округленном преобразовании в его внутреннее представление это стало бесконечностью IEEE 754. Программа Java может представить бесконечности, не производя ошибку времени компиляции при использовании константных выражений такой как 1f/0f или -1d/0d или при использовании предопределенных констант POSITIVE_INFINITY и NEGATIVE_INFINITY из классов Float (§20.9) и Double (§20.10).
Ошибка времени компиляции происходит, если ненулевой литерал с плавающей точкой является слишком маленьким, так, чтобы на округленном преобразовании в его внутреннее представление это стало нулем. Ошибка времени компиляции не происходит, если у ненулевого литерала с плавающей точкой есть маленькое значение, которое, на округленном преобразовании в его внутреннее представление, становится ненулевым денормализованным числом.
Предопределенные константы, представляющие значения Не-числа, определяются в классах Float и Double как Float.NaN (§20.9.5) и Double.NaN (§20.10.5).
1e1f 2.f .3f 0f 3.14f 6.022137e+23fПримеры
double литералы:
1e1 2. .3 0.0 3.14 1e-9d 1e137Нет никакого условия для того, чтобы выразить литералы с плавающей точкой в кроме десятичного основания. Однако, метод
intBitsToFloat (§20.9.23) класса Float и метод longBitsToDouble (§20.10.22) класса Double обеспечьте способ выразить значения с плавающей точкой с точки зрения шестнадцатеричных или восьмеричных целочисленных литералов. Например, значение:
Double.longBitsToDouble(0x400921FB54442D18L)равно значению
Math.PI (§20.11.2). boolean у типа есть два значения, представленные литералами true и false, сформированный из букв ASCII. Булев литерал всегда имеет тип boolean.
BooleanLiteral: one of
true false
\u0027.) Символьный литерал всегда имеет тип char.
CharacterLiteral:Escape-последовательности описываются в §3.10.6.
'SingleCharacter'EscapeSequence
''SingleCharacter:
InputCharacter but not'or\
Как определено в §3.4, символы CR и LF никогда не является InputCharacter; они распознаются как образование LineTerminator.
Это - ошибка времени компиляции для символа после SingleCharacter или EscapeSequence, чтобы быть кроме a '.
Это - ошибка времени компиляции для разделителя строки, чтобы появиться после открытия ' и перед закрытием '.
Следующее является примерами char литералы:
'a' '%' '\t' '\\' '\'' '\u03a9' '\uFFFF' '\177' 'Поскольку Escape Unicode обрабатываются очень рано, это не корректно, чтобы записать' '
'\u000a' для символьного литерала, значение которого является переводом строки (LF); escape Unicode \u000a преобразовывается в фактический перевод строки в шаге 1 преобразования (§3.3), и перевод строки становится LineTerminator в шаге 2 (§3.4), и таким образом, символьный литерал не допустим в шаге 3. Вместо этого нужно использовать escape-последовательность '\n' (§3.10.6). Точно так же это не корректно, чтобы записать '\u000d' для символьного литерала, значение которого является возвратом каретки (CR). Вместо этого используйте '\r'.В C и C++, символьный литерал может содержать представления больше чем одного символа, но значение такого символьного литерала определяется с помощью реализации. В Java символьный литерал всегда представляет точно один символ.
Строковый литерал всегда имеет тип String (§4.3.3, §20.12). Строковый литерал всегда обращается к тому же самому экземпляру (§4.3.1) класса String.
StringLiteral:Escape-последовательности описываются в §3.10.6.
"StringCharactersopt"StringCharacters:
StringCharacter
StringCharactersStringCharacter StringCharacter:
InputCharacter but not"or\EscapeSequence
Как определено в §3.4, ни одном из символов CR и LF, как когда-либо полагают, является InputCharacter; каждый распознается как образование LineTerminator.
Это - ошибка времени компиляции для разделителя строки, чтобы появиться после открытия " и перед соответствием закрытия ". Долгий строковый литерал может всегда разбиваться в более короткие части и писаться как (возможно заключенный в скобки) выражение, используя оператор конкатенации строк + (§15.17.1).
Следующее является примерами строковых литералов:
"" // the empty string "\"" // a string containing " alone "This is a string" // a string containing 16 charactersПоскольку Escape Unicode обрабатываются очень рано, это не корректно, чтобы записать
"This is a " + // actually a string-valued constant expression, "two-line string" // formed from two string literals
"\u000a" для строкового литерала, содержащего единственный перевод строки (LF); escape Unicode \u000a преобразовывается в фактический перевод строки в шаге 1 преобразования (§3.3), и перевод строки становится LineTerminator в шаге 2 (§3.4), и таким образом, строковый литерал не допустим в шаге 3. Вместо этого нужно записать "\n" (§3.10.6). Точно так же это не корректно, чтобы записать "\u000d" для строкового литерала, содержащего единственный возврат каретки (CR). Вместо этого используйте "\r".
Каждый строковый литерал является ссылкой (§4.3) к экземпляру (§4.3.1, §12.5) класса String (§4.3.3, §20.12). String у объектов есть постоянная величина. Строковые литералы - или, более широко, строки, которые являются значениями константных выражений (§15.27) - "интернируются", чтобы совместно использовать уникальные экземпляры, используя метод String.intern (§20.12.47).
Таким образом, тестовая программа, состоящая из единицы компиляции (§7.3):
package testPackage;
class Test {
public static void main(String[] args) {
String hello = "Hello", lo = "lo";
System.out.print((hello == "Hello") + " ");
System.out.print((Other.hello == hello) + " ");
System.out.print((other.Other.hello == hello) + " ");
System.out.print((hello == ("Hel"+"lo")) + " ");
System.out.print((hello == ("Hel"+lo)) + " ");
System.out.println(hello == ("Hel"+lo).intern());
}
}
class Other { static String hello = "Hello"; }
и единица компиляции: производит вывод:
package other;
public class Other { static String hello = "Hello"; }
true true true true false trueЭтот пример иллюстрирует шесть тезисов:
String объект (§4.3.1).
String объект.
String объект.
EscapeSequence:Это - ошибка времени компиляции, если символ после наклонной черты влево в escape не является ASCII
\ b /* \u0008:backspaceBS*/horizontal tab
\ t /* \u0009:HT*/linefeed
\ n /* \u000a:LF*/form feed
\ f /* \u000c:FF*/carriage return
\ r /* \u000d:CR*/double quote
\ " /* \u0022:" */single quote
\ ' /* \u0027:' */backslash
\ \ /* \u005c:\ */OctalEscape
/* \u0000to\u00ff:from octal value*/OctalEscape:
\OctalDigit
\OctalDigitOctalDigit
\ZeroToThreeOctalDigitOctalDigit OctalDigit: one of
0 1 2 3 4 5 6 7ZeroToThree: one of
0 1 2 3
b, t, n, f, r, ", ', \, 0, 1, 2, 3, 4, 5, 6, или 7. escape Unicode \u обрабатывается ранее (§3.3). (Восьмеричные Escape обеспечиваются для совместимости с C, но могут выразить только значения Unicode \u0000 через \u00FF, таким образом, Escape Unicode обычно предпочитаются.)null, который формируется из символов ASCII. Нулевой литерал всегда имеет нулевой тип. NullLiteral:
null
Separator: one of
( ) { } [ ] ; , .
Operator: one of
= > < ! ~ ? :
== <= >= != && || ++ --
+ - * / & | ^ % << >> >>>
+= -= *= /= &= |= ^= %= <<= >>= >>>=
Содержание | Предыдущий | Следующий | Индекс
Спецификация языка Java (HTML, сгенерированный Блинчиком "сюзет" Pelouch 24 февраля 1998)
Авторское право © Sun Microsystems, Inc 1996 года. Все права защищены
Пожалуйста, отправьте любые комментарии или исправления к doug.kramer@sun.com