Spec-Zone .ru
спецификации, руководства, описания, API
|
|
Spec-Zone .ru
спецификации, руководства, описания, API
|
| Содержание | Предыдущий | Следующий | Индекс | Спецификация языка Java Третий Выпуск |
ГЛАВА 15
Большая часть работы в программе делается, оценивая выражения, или для их побочных эффектов, таких как присвоения на переменные, или для их значений, которые могут использоваться в качестве параметров или операндов в больших выражениях, или влиять на последовательность выполнения в операторах, или обоих.
Эта глава определяет значения выражений и правил для их оценки.
Выражение ничего не обозначает, если и только если это - вызов метода (§15.12), который вызывает метод, который не возвращает значение, то есть, объявленный метод void (§8.4). Такое выражение может использоваться только в качестве оператора выражения (§14.8), потому что любой контекст, в котором может появиться выражение, требует, чтобы выражение обозначило что-то. Оператор выражения, который является вызовом метода, может также вызвать метод, который приводит к результату; в этом случае значение, возвращенное методом, спокойно отбрасывается.
Преобразование набора значений (§5.1.13) применяется к результату каждого выражения, которое производит значение.
Каждое выражение происходит в также:
Если значение переменной типа float или double используется этим способом, тогда преобразование набора значений (§5.1.13) применяется к значению переменной.
Значение выражения является присвоением, совместимым (§5.2) с типом выражения, если загрязнение "кучи" (§4.12.2.1) не происходит. Аналогично значение, сохраненное в переменной, является всегда совместимым с типом переменной, если загрязнение "кучи" не происходит. Другими словами значение выражения, тип которого является T, является всегда подходящим для присвоения на переменную типа T.
Отметьте, что выражение, тип которого является типом класса F, который объявляется final как гарантируют, будет иметь значение, которое является или нулевой ссылкой или объектом, класс которого является F непосредственно, потому что final у типов нет никаких подклассов.
float или double, тогда есть вопрос относительно того, из чего оттягивается набор значений (§4.2.3) значение выражения. Этим управляют правила преобразования набора значений (§5.1.13); эти правила поочередно зависят от того, строго ли выражение FP.
Каждое константное выражение времени компиляции (§15.28) строго FP. Если выражение не является константным выражением времени компиляции, то рассмотрите все объявления класса, интерфейсные объявления, и объявления метода, которые содержат выражение. Если какое-либо такое объявление переносит strictfp модификатор, тогда выражение строго FP.
Если класс, интерфейс, или метод, X, объявляется strictfp, тогда X и любой класс, интерфейс, метод, конструктор, инициализатор экземпляра, статический инициализатор или переменный инициализатор в пределах X, как говорят, строг FP. Отметьте, что аннотация (§9.7) значение элемента (§9.6) всегда строга FP, потому что это всегда - время компиляции, постоянное (§15.28).
Из этого следует, что выражение не строго FP, если и только если это не константное выражение времени компиляции, и это не появляется в пределах никакого объявления, которое имеет strictfp модификатор.
В пределах строгого FP выражения все промежуточные значения должны быть элементами набора значений плавающего или двойного набора значений, подразумевая, что результаты всех строгих FP выражений должны быть предсказанными арифметикой IEEE 754 на операндах, представленных, используя единственные и двойные форматы. В пределах выражения, которое не строго FP, некоторый дрейф предоставляют для реализации использовать расширенный диапазон экспоненты, чтобы представить промежуточные результаты; результирующий эффект, примерно разговор, состоит в том, что вычисление могло бы произвести "корректный ответ" в ситуациях, где монопольное использование набора значений плавающего или удваивается, набор значений мог бы привести к переполнению или потере значимости.
null, не обязательно известен во время компиляции. Есть несколько мест в языке программирования Java, где фактический класс объекта, на который ссылаются, влияет на выполнение программы способом, который не может быть выведен из типа выражения. Они следующие:
o.m(...) выбирается основанный на методах, которые являются частью класса или интерфейса, который является типом o. Например методы, класс объекта, на который ссылается значение времени выполнения o участвует, потому что подкласс может переопределить определенный метод, уже объявленный в родительском классе так, чтобы этот метод переопределения был вызван. (Метод переопределения может или, возможно, не хочет далее вызывать переопределенный оригинал m метод.)
instanceof оператор (§15.20.2). Выражение, тип которого является ссылочным типом, может быть протестировано, используя instanceof узнать, является ли класс объекта, на который ссылается значение времени выполнения выражения, присвоением, совместимым (§5.2) с некоторым другим ссылочным типом.
[] быть обработанным как подтип T[] если S является подтипом T, но это требует проверки на этапе выполнения на присвоение на компонент массива, подобный проверке, выполняемой для броска.
catch пункт, только если класс брошенного объекта исключения instanceof тип формального параметра catch пункт. Кроме того, есть ситуации, где статически известный тип, возможно, не точен во время выполнения. Такие ситуации могут возникнуть в программе, которая дает начало предупреждениям непроверенным. Такие предупреждения даются в ответ на операции, которые, как могут статически гарантировать, не будут безопасны, и не могут сразу быть подвергнуты динамической проверке, потому что они включают non-reifiable (§4.7) типы. В результате динамические проверки позже в ходе выполнения программы могут обнаружить несогласованности и привести к ошибкам типа времени выполнения.
Ошибка типа времени выполнения может произойти только в этих ситуациях:
ClassCastException бросается.
ArrayStoreException бросается.
catch обработчик (§11.3); в этом случае поток управления, которое встретилось с исключением сначала, вызывает метод uncaughtException для его группы потока и затем завершается.
Если, однако, оценка выражения выдает исключение, то выражение, как говорят, завершается резко. У резкого завершения всегда есть связанная причина, которая всегда является a throw с данным значением.
Исключения на этапе выполнения бросаются предопределенными операторами следующим образом:
OutOfMemoryError если есть недостаточная доступная память.
NegativeArraySizeException если значение какого-либо выражения размерности является меньше чем нуль (§15.10).
NullPointerException если значение выражения ссылки на объект null.
NullPointerException если целевая ссылка null.
NullPointerException если значение ссылочного выражения массива null.
ArrayIndexOutOfBoundsException если значение индексного выражения массива отрицательно или больше чем или равно length из массива.
ClassCastException если бросок, как находят, непозволителен во время выполнения.
ArithmeticException если значение правого выражения операнда является нулем.
OutOfMemoryError в результате упаковки преобразования (§5.1.7).
ArrayStoreException когда значение, которое будет присвоено, не является совместимым с компонентным типом массива. Если исключение происходит, то оценка одного или более выражений может быть завершена прежде, чем все шаги их нормального режима оценки полны; такие выражения, как говорят, завершаются резко. Термины, "полные обычно" и "полный резко", также применяются к выполнению операторов (§14.1). Оператор может завершиться резко для множества причин, не только, потому что исключение выдается.
Если оценка выражения требует оценки подвыражения, резкое завершение подвыражения всегда вызывает непосредственное резкое завершение выражения непосредственно с той же самой причиной, и все последующие шаги в нормальном режиме оценки не выполняются.
Рекомендуется, чтобы код не положился кардинально на эту спецификацию. Код является обычно более четким, когда каждое выражение содержит самое большее один побочный эффект как его наиболее удаленная работа, и когда код не зависит от точно, какое исключение возникает как следствие слева направо оценка выражений.
Таким образом:
class Test {
public static void main(String[] args) {
int i = 2;
int j = (i=3) * i;
System.out.println(j);
}
}
Не разрешается для этого напечатать9
6 вместо 9.Если оператор является составным оператором присваивания (§15.26.2), то оценка левого операнда включает и запоминание переменной, которую левый операнд обозначает и выборка и сохранение что значение переменной для использования в подразумеваемой работе объединения. Так, например, тестовая программа:
class Test {
public static void main(String[] args) {
int a = 9;
a += (a = 3); // first example
System.out.println(a);
int b = 9;
b = b + (b = 3); // second example
System.out.println(b);
}
}
потому что эти два оператора присваивания и выбирают и помнят значение левого операнда, который является12 12
9, прежде, чем правый операнд дополнения оценивается, таким образом устанавливая переменную в 3. Не разрешается ни для одного примера привести к результату 6. Отметьте, что у обоих из этих примеров есть неуказанное поведение в C согласно стандарту ANSI/ISO.Если оценка левого операнда бинарного оператора завершается резко, никакая часть правого операнда, кажется, не была оценена.
Таким образом, тестовая программа:
class Test {
public static void main(String[] args) {
int j = 1;
try {
int i = forgetIt() / (j = 2);
} catch (Exception e) {
System.out.println(e);
System.out.println("Now j = " + j);
}
}
static int forgetIt() throws Exception {
throw new Exception("I'm outta here!");
}
}
Таким образом, левый операндjava.lang.Exception: I'm outta here! Now j = 1
forgetIt() из оператора / выдает исключение прежде, чем правый операнд будет оценен и его встроенное присвоение 2 к j происходит.&&, ||, и ? :), кажется, полностью оценивается прежде, чем любая часть самой работы выполняется.
Если бинарный оператор является целочисленным делением / (§15.17.2) или целочисленный остаток % (§15.17.3), тогда его выполнение может повысить ArithmeticException, но это исключение выдается только после того, как оба операнда бинарного оператора были оценены и только если эти оценки, завершаемые обычно.
Так, например, программа:
class Test {
public static void main(String[] args) {
int divisor = 0;
try {
int i = 1 / (divisor * loseBig());
} catch (Exception e) {
System.out.println(e);
}
}
static int loseBig() throws Exception {
throw new Exception("Shuffle off to Buffalo!");
}
}
и нет:java.lang.Exception: Shuffle off to Buffalo!
так как никакая часть операции деления, включая сигнализацию исключения дележа на нуль, может казаться, не происходит перед вызовомjava.lang.ArithmeticException: / by zero
loseBig завершается, даже при том, что реализация может быть в состоянии обнаружить или вывести, что операция деления, конечно, привела бы к исключению дележа на нуль.
В случае вычислений с плавающей точкой это правило применяет также для бесконечности и не-числа (НЭН) значения. Например, !(x<y) возможно, не переписывается как x>=y, потому что у этих выражений есть различные значения если также x или y НЭН, или оба - НЭН.
Определенно, вычисления с плавающей точкой, которые, кажется, математически ассоциативны, вряд ли будут в вычислительном отношении ассоциативны. Такие вычисления не должны быть наивно переупорядочены.
Например, это не корректно для компилятора Java, чтобы переписать 4.0*x*0.5 как 2.0*x; в то время как округление, оказывается, не проблема здесь, есть большие значения x для которого первое выражение производит бесконечность (из-за переполнения), но второе выражение приводит к конечному результату.
Так, например, тестовая программа:
strictfp class Test {
public static void main(String[] args) {
double d = 8e+307;
System.out.println(4.0 * d * 0.5);
System.out.println(2.0 * d);
}
}
потому что первые переполнения выражения и второе не делают.Infinity 1.6e+308
Напротив, целочисленное дополнение и умножение доказуемо ассоциативны в языке программирования Java.
Например a+b+c, где a, b, и c локальные переменные (это предположение упрощения избегает проблем, включающих многократные потоки и volatile переменные), будет всегда производить тот же самый ответ, оцененный ли как (a+b)+c или a+(b+c); если выражение b+c происходит поблизости в коде, умный компилятор может быть в состоянии использовать это общее подвыражение.
Таким образом:
class Test {
public static void main(String[] args) {
String s = "going, ";
print3(s, s, s = "gone");
}
static void print3(String a, String b, String c) {
System.out.println(a + b + c);
}
}
потому что присвоение строкиgoing, going, gone
"gone" к s происходит после первых двух параметров print3 были оценены.Если оценка выражения параметра завершается резко, никакая часть любого выражения параметра с его правой стороны от него, кажется, не была оценена.
Таким образом, пример:
class Test {
static int id;
public static void main(String[] args) {
try {
test(id = 1, oops(), id = 3);
} catch (Exception e) {
System.out.println(e + ", id=" + id);
}
}
static int oops() throws Exception {
throw new Exception("oops");
}
static int test(int a, int b, int c) {
return a + b + c;
}
}
потому что присвоениеjava.lang.Exception: oops, id=1
3 к id не выполняется.
Primary:
PrimaryNoNewArray
ArrayCreationExpression
PrimaryNoNewArray:
Literal
Type . class
void . class
this
ClassName.this
( Expression )
ClassInstanceCreationExpression
FieldAccess
MethodInvocation
ArrayAccess
Следующее производство от §3.10 повторяется здесь для удобства:
Literal:
IntegerLiteral
FloatingPointLiteral
BooleanLiteral
CharacterLiteral
StringLiteral
NullLiteral
L или l long; тип любого другого целочисленного литерала int.
F или f float и его значение должно быть элементом набора значений плавающего (§4.2.3). Тип любого другого литерала с плавающей точкой double и его значение должно быть элементом двойного набора значений.
boolean.
char.
String.
null нулевой тип; его значение является нулевой ссылкой. void, сопровождаемый `.' и маркер class. Тип литерала класса, C.Class, то, где C является именем класса, интерфейса или типа массива, Class<C>. Если p является именем типа примитива, позвольте B быть типом выражения типа p после упаковки преобразования (§5.1.7). Затем тип p.class Class<B>. Тип void.class Class<Void>.
Литерал класса оценивает к Class объект для именованного типа (или для пустоты) как определено загрузчиком класса определения класса текущего экземпляра.
Это - ошибка времени компиляции, если какое-либо следующее происходит:
this может использоваться только в теле метода экземпляра, инициализатора экземпляра или конструктора, или в инициализаторе переменной экземпляра класса. Если это появляется где-нибудь еще, ошибка времени компиляции происходит.
Когда использующийся в качестве основного выражения, ключевого слова this обозначает значение, которое является ссылкой на объект, для которого метод экземпляра был вызван (§15.12), или к создаваемому объекту. Тип this класс C в пределах который ключевое слово this происходит. Во время выполнения класс фактического упомянутого объекта может быть классом C или любым подклассом C.
В примере:
class IntVector {
int[] v;
boolean equals(IntVector other) {
if (this == other)
return true;
if (v.length != other.v.length)
return false;
for (int i = 0; i < v.length; i++)
if (v[i] != other.v[i])
return false;
return true;
}
}
IntVector реализует метод equals, который сравнивает два вектора. Если other вектор является тем же самым векторным объектом как тот для который equals метод был вызван, тогда проверка может пропустить длину и оценить сравнения. equals метод реализует, это проверяет сравнение ссылки на other объект к this.
Ключевое слово this также используется в специальном явном операторе вызова конструктора, который может появиться в начале тела конструктора (§8.8.7).
Позвольте C быть классом, обозначенным ClassName. Позвольте n быть целым числом так, что C, энное лексически класс включения класса, в котором квалифицированный появляется это выражение. Значение выражения формы ClassName.this энное лексически экземпляр включения this (§8.1.3). Тип выражения является C. Это - ошибка времени компиляции, если текущий класс не является внутренним классом класса C или C непосредственно.
Использование круглых скобок только производит порядок оценки с одним захватывающим исключением.
Обсуждение
Рассмотрите случай если самая маленькая отрицательная величина типа long. Это значение, 9223372036854775808L, позволяется только как операнд оператора унарный минус (§3.10.1). Поэтому, включение этого в круглых скобках, как в - (9223372036854775808L) вызывает ошибку времени компиляции.
В частности присутствие или отсутствие круглых скобок вокруг выражения не делают (за исключением случая, отмеченного выше), влияют всегда:
float или double.
ClassInstanceCreationExpression:
new TypeArgumentsopt ClassOrInterfaceType ( ArgumentListopt )
ClassBodyopt
Primary. new TypeArgumentsopt Identifier TypeArgumentsopt (
ArgumentListopt ) ClassBodyopt
ArgumentList:
Expression
ArgumentList , Expression
new. Неполное выражение создания экземпляра класса может использоваться, чтобы создать экземпляр класса, независимо от того, является ли класс верхним уровнем (§7.6), элемент (§8.5, §9.5), локальный (§14.3) или анонимный класс (§15.9.5).
Мы говорим, что класс инстанцируют, когда экземпляр класса создается выражением создания экземпляра класса. Инстанцирование класса включает определение, какой класс нужно инстанцировать, каковы экземпляры включения (если кто-либо) недавно создаваемого экземпляра, какой конструктор должен быть вызван, чтобы создать новый экземпляр и какие параметры нужно передать тому конструктору.
final класс. Если T обозначает интерфейс тогда анонимный прямой подкласс Object это реализует интерфейс, названный T, объявляется. В любом случае телом подкласса является ClassBody, данный в выражении создания экземпляра класса. Класс, который инстанцируют, является анонимным подклассом.
final внутренний класс (§8.1.3), который является элементом типа времени компиляции Основного устройства. Это - также ошибка времени компиляции, если T неоднозначен (§8.5) или если T обозначает перечислимый тип. Анонимный прямой подкласс класса, названного T, объявляется. Телом подкласса является ClassBody, данный в выражении создания экземпляра класса. Класс, который инстанцируют, является анонимным подклассом.
abstract, или ошибка времени компиляции происходит. В этом случае класс, который инстанцируют, является классом, обозначенным ClassOrInterfaceType.
abstract внутренний класс (§8.1.3) T, который является элементом типа времени компиляции Основного устройства. Это - также ошибка времени компиляции, если Идентификатор неоднозначен (§8.5), или если Идентификатор обозначает перечислимый тип (§8.9). Класс, который инстанцируют, является классом, обозначенным Идентификатором.
this (§8.1.3). this.
this. this.
Во-первых, если выражение создания экземпляра класса является квалифицированным выражением создания экземпляра класса, квалифицирующее основное выражение оценивается. Если выражение квалификации оценивает к null, a NullPointerException повышается, и выражение создания экземпляра класса завершается резко. Если выражение квалификации завершается резко, выражение создания экземпляра класса завершается резко по той же самой причине.
Затем, место выделяется для нового экземпляра класса. Если есть недостаточное пространство, чтобы выделить объект, оценка выражения создания экземпляра класса завершается резко, бросая OutOfMemoryError (§15.9.6).
Новый объект содержит новые экземпляры всех полей, объявленных в указанном типе класса и всех его суперклассов. Поскольку каждый новый полевой экземпляр создается, он инициализируется к его значению по умолчанию (§4.12.5).
Затем, фактические параметры конструктору оцениваются, слева направо. Если какая-либо из оценок параметра завершается резко, любые выражения параметра с его правой стороны от него не оцениваются, и выражение создания экземпляра класса завершается резко по той же самой причине.
Затем, выбранный конструктор указанного типа класса вызывается. Это приводит к вызову по крайней мере одного конструктора для каждого суперкласса типа класса. Этот процесс может быть направлен явными операторами вызова конструктора (§8.8) и описывается подробно в §12.5.
Значение выражения создания экземпляра класса является ссылкой на недавно создаваемый объект указанного класса. Каждый раз, когда выражение оценивается, новый объект создается.
Анонимный класс никогда не abstract (§8.1.1.1). Анонимный класс всегда является внутренним классом (§8.1.3); это никогда не static (§8.1.1, §8.5.2). Анонимный класс всегда неявно final (§8.1.1.2).
Тело конструктора состоит из явного вызова конструктора (§8.8.7.1) формы super(...), где фактическими параметрами являются формальные параметры конструктора, в порядке они были объявлены.
super(...), где o является первым формальным параметром конструктора, и фактическими параметрами являются последующие формальные параметры конструктора в порядке, которым они были объявлены. throws пункт анонимного конструктора должен перечислить все проверенные исключения, выданные явным оператором вызова конструктора суперкласса, содержавшим в пределах анонимного конструктора, и всех проверенных исключений, выданных любыми инициализаторами экземпляра или инициализаторами переменной экземпляра анонимного класса.Отметьте, что для подписи анонимного конструктора возможно обратиться к недоступному типу (например, если такой тип произошел в подписи конструктора суперкласса cs). Это, сам по себе, не вызывает ошибок или во время компиляции или во время выполнения.
OutOfMemoryError бросается. Эта проверка происходит прежде, чем любые выражения параметра оцениваются.Так, например, тестовая программа:
class List {
int value;
List next;
static List head = new List(0);
List(int n) { value = n; next = head; head = this; }
}
class Test {
public static void main(String[] args) {
int id = 0, oldid = 0;
try {
for (;;) {
++id;
new List(oldid = id);
}
} catch (Error e) {
System.out.println(e + ", " + (oldid==id));
}
}
}
потому что условие из памяти обнаруживается перед выражением параметраjava.lang.OutOfMemoryError: List, false
oldid = id оценивается.Сравните это с обработкой выражений создания массива (§15.10), для которого условие из памяти обнаруживается после оценки выражений размерности (§15.10.3).
ArrayCreationExpression:
new PrimitiveType DimExprs Dimsopt
new ClassOrInterfaceType DimExprs Dimsopt
new PrimitiveType Dims ArrayInitializer
new ClassOrInterfaceType Dims ArrayInitializer
DimExprs:
DimExpr
DimExprs DimExpr
DimExpr:
[ Expression ]
Dims:
[ ]
Dims [ ]
abstract тип класса (§8.1.1.1) или интерфейсный тип (§9). Обсуждение
Правила выше подразумевают, что элемент вводит выражение создания массива, не может быть параметризованный тип, кроме неограниченного подстановочного знака.
Тип выражения создания является типом массива, который может обозначенный копией выражения создания от который new ключевое слово и каждое выражение DimExpr и инициализатор массива были удалены.
Например, тип выражения создания:
:new double[3][3][]
Тип каждого выражения размерности в пределах DimExpr должен быть типом, который конвертируем (§5.1.8) к целочисленному типу, или ошибка времени компиляции происходит. Каждое выражение подвергается унарному числовому продвижению (§). Продвинутый тип должен бытьdouble[][][]
int, или ошибка времени компиляции происходит; это означает, определенно, что тип выражения размерности не должен быть long.Если инициализатор массива будет обеспечен, то недавно выделенный массив будет инициализирован со значениями, обеспеченными инициализатором массива как описано в §10.6.
Во-первых, выражения размерности оцениваются, слева направо. Если какое-либо из вычислений выражения завершается резко, выражения направо от этого не оцениваются.
Затем, значения выражений размерности проверяются. Если значение любого выражения DimExpr является меньше чем нуль, то NegativeArraySizeException бросается.
Затем, место выделяется для нового массива. Если есть недостаточное пространство, чтобы выделить массив, оценка выражения создания массива завершается резко, бросая OutOfMemoryError.
Затем, если единственный DimExpr появляется, одномерный массив создается из указанной длины, и каждый компонент массива инициализируется к его значению по умолчанию (§4.12.5).
Если выражение создания массива содержит выражения DimExpr N, то оно эффективно выполняет ряд вложенных циклов глубины N-1, чтобы создать подразумеваемые массивы массивов.
Например, объявление:
эквивалентно в поведении:float[][] matrix = new float[3][3];
float[][] matrix = new float[3][];
for (int d = 0; d < matrix.length; d++)
matrix[d] = new float[3];
эквивалентно:Age[][][][][] Aquarius = new Age[6][10][8][12][];
Age[][][][][] Aquarius = new Age[6][][][][];
for (int d1 = 0; d1 < Aquarius.length; d1++) {
Aquarius[d1] = new Age[10][][][];
for (int d2 = 0; d2 < Aquarius[d1].length; d2++) {
Aquarius[d1][d2] = new Age[8][][];
for (int d3 = 0; d3 < Aquarius[d1][d2].length; d3++) {
Aquarius[d1][d2][d3] = new Age[12][];
}
}
}
new выражение фактически создает один массив длины 6, 6 массивов длины 10, 6 x 10 = 60 массивов длины 8, и 6 x 10 x 8 = 480 массивов длины 12. Эти листы в качестве примера пятая размерность, которая была бы массивами, содержащими фактические элементы массива (ссылки на Age объекты), инициализированный только к нулевым ссылкам. Эти массивы могут быть переполнены в позже другим кодом, таковы как:
Age[] Hair = { new Age("quartz"), new Age("topaz") };
Aquarius[1][9][6][9] = Hair;
У многомерного массива не должно быть массивов той же самой длины на каждом уровне.
Таким образом треугольная матрица может быть создана:
float triang[][] = new float[100][];
for (int i = 0; i < triang.length; i++)
triang[i] = new float[i+1];
Таким образом:
class Test {
public static void main(String[] args) {
int i = 4;
int ia[][] = new int[i][i=3];
System.out.println(
"[" + ia.length + "," + ia[0].length + "]");
}
}
потому что первая размерность вычисляется как[4,3]
4 перед вторыми наборами выражения размерности i к 3.Если оценка выражения размерности завершится резко, то никакая часть любого выражения размерности с его правой стороны от него, будет казаться, не была оценена. Таким образом, пример:
class Test {
public static void main(String[] args) {
int[][] a = { { 00, 01 }, { 10, 11 } };
int i = 99;
try {
a[val()][i = 1]++;
} catch (Exception e) {
System.out.println(e + ", i=" + i);
}
}
static int val() throws Exception {
throw new Exception("unimplemented");
}
}
потому что встроенное присвоение, которое устанавливаетjava.lang.Exception: unimplemented, i=99
i к 1 никогда не выполняется.OutOfMemoryError бросается. Эта проверка происходит только после того, как оценка всех выражений размерности обычно завершалась. Так, например, тестовая программа:
class Test {
public static void main(String[] args) {
int len = 0, oldlen = 0;
Object[] a = new Object[0];
try {
for (;;) {
++len;
Object[] temp = new Object[oldlen = len];
temp[0] = a;
a = temp;
}
} catch (Error e) {
System.out.println(e + ", " + (oldlen==len));
}
}
}
потому что условие из памяти обнаруживается после выражения размерностиjava.lang.OutOfMemoryError, true
oldlen = len оценивается.Сравните это с выражениями создания экземпляра класса (§15.9), которые обнаруживают условие из памяти прежде, чем оценить выражения параметра (§15.9.6).
super. (Также возможно обратиться к полю текущего экземпляра или текущего класса при использовании простого имени; см. §6.5.6.)
FieldAccess:
Primary . Identifier
super . Identifier
ClassName .super . Identifier
static: final, тогда результатом является значение указанной переменной класса в классе, или взаимодействуйте через интерфейс, который является типом Основного выражения.
final, тогда результатом является переменная, а именно, указанная переменная класса в классе, который является типом Основного выражения. static: null, тогда a NullPointerException бросается.
final, тогда результатом является значение указанной переменной экземпляра в объекте, на который ссылается значение Основного устройства.
final, тогда результатом является переменная, а именно, указанная переменная экземпляра в объекте, на который ссылается значение Основного устройства. Таким образом, пример:
class S { int x = 0; }
class T extends S { int x = 1; }
class Test {
public static void main(String[] args) {
T t = new T();
System.out.println("t.x=" + t.x + when("t", t));
S s = new S();
System.out.println("s.x=" + s.x + when("s", s));
s = t;
System.out.println("s.x=" + s.x + when("s", s));
}
static String when(String name, Object t) {
return " when " + name + " holds a "
+ t.getClass() + " at run time.";
}
}
Последняя строка показывает, что, действительно, поле, к которому получают доступ, не зависит от класса времени выполнения объекта, на который ссылаются; даже еслиt.x=1 when t holds a class T at run time. s.x=0 when s holds a class S at run time. s.x=0 when s holds a class T at run time.
s содержит ссылку на объект класса T, выражение s.x обращается к x поле класса S, потому что тип выражения s S. Объекты класса T содержите два названные поля x, один для класса T и один для его суперкласса S.Эта нехватка динамического поиска для доступов к полю позволяет программам быть выполненными эффективно с прямыми реализациями. Питание позднего связывания и переопределения доступно, но только когда методы экземпляра используются. Полагайте, что тот же самый пример, используя методы экземпляра получает доступ к полям:
class S { int x = 0; int z() { return x; } }
class T extends S { int x = 1; int z() { return x; } }
class Test {
public static void main(String[] args) {
T t = new T();
System.out.println("t.z()=" + t.z() + when("t", t));
S s = new S();
System.out.println("s.z()=" + s.z() + when("s", s));
s = t;
System.out.println("s.z()=" + s.z() + when("s", s));
}
static String when(String name, Object t) {
return " when " + name + " holds a "
+ t.getClass() + " at run time.";
}
}
Последняя строка показывает, что, действительно, метод, к которому получают доступ, действительно зависит от класса времени выполнения объекта, на который ссылаются; когдаt.z()=1 when t holds a class T at run time. s.z()=0 when s holds a class S at run time. s.z()=1 when s holds a class T at run time.
s содержит ссылку на объект класса T, выражение s.z() обращается к z метод класса T, несмотря на то, что тип выражения s S. Метод z из класса T метод переопределений z из класса S.Следующий пример демонстрирует, что нулевая ссылка может использоваться, чтобы получить доступ к классу (static) переменная, не вызывая исключение:
class Test {
static String mountain = "Chocorua";
static Test favorite(){
System.out.print("Mount ");
return null;
}
public static void main(String[] args) {
System.out.println(favorite().mountain);
}
}
Mount Chocorua
Даже при том, что результат favorite() null, a NullPointerException не бросается. Это"Mount "печатается, демонстрирует, что Основное выражение действительно полностью оценивается во время выполнения, несмотря на то, что только его тип, не его значение, используется, чтобы определить который поле к доступу (потому что поле mountain static).
super допустимы только в методе экземпляра, инициализаторе экземпляра или конструкторе, или в инициализаторе переменной экземпляра класса; они - точно те же самые ситуации в который ключевое слово this может использоваться (§15.8.3). Включение форм super возможно, не используется нигде в классе Object, с тех пор Object не имеет никакого суперкласса; если super появляется в классе Object, тогда ошибка времени компиляции заканчивается.
Предположите что выражение доступа к полю super.имя появляется в пределах класса C, и непосредственный суперкласс C является классом S. Затем super.имя обрабатывается точно, как будто это было выражение ((S) это).name; таким образом это обращается к полю, названному именем текущего объекта, но с текущим объектом, просматриваемым как экземпляр суперкласса. Таким образом это может получить доступ к полю, названному именем, которое видимо в классе S, даже если то поле скрывается объявлением поля, названного именем в классе C.
Использование super демонстрируется следующим примером:
interface I { int x = 0; }
class T1 implements I { int x = 1; }
class T2 extends T1 { int x = 2; }
class T3 extends T2 {
int x = 3;
void test() {
System.out.println("x=\t\t"+x);
System.out.println("super.x=\t\t"+super.x);
System.out.println("((T2)this).x=\t"+((T2)this).x);
System.out.println("((T1)this).x=\t"+((T1)this).x);
System.out.println("((I)this).x=\t"+((I)this).x);
}
}
class Test {
public static void main(String[] args) {
new T3().test();
}
}
x= 3 super.x= 2 ((T2)this).x= 2 ((T1)this).x= 1 ((I)this).x= 0
В пределах класса T3, выражение super.x обрабатывается точно, как будто это было:
Предположите что выражение T доступа к полю.((T2)this).x
super.name появляется в пределах класса C, и непосредственный суперкласс класса, обозначенного T, является классом, полностью определенное имя которого является S. Затем T.super.name обрабатывается точно, как будто это было выражение ((S)T.this).имя.
Таким образом выражение T.super.name может получить доступ к полю, названному именем, которое видимо в классе, названном S, даже если то поле скрывается объявлением поля, названного именем в классе, названном T.
Это - ошибка времени компиляции, если текущий класс не является внутренним классом класса T или T непосредственно.
MethodInvocation:
MethodName ( ArgumentListopt )
Primary . NonWildTypeArgumentsopt Identifier ( ArgumentListopt )
super . NonWildTypeArgumentsopt Identifier ( ArgumentListopt )
ClassName . super . NonWildTypeArgumentsopt Identifier ( ArgumentListopt
)
TypeName . NonWildTypeArguments Identifier ( ArgumentListopt )
ArgumentList:
Expression
ArgumentList , Expression
Разрешение имени метода во время компиляции более усложняется чем разрешение имени поля из-за возможности перегрузки метода. Вызов метода во время выполнения также более усложняется чем доступ к полю из-за возможности переопределения метода экземпляра.
Определение метода, который будет вызван выражением вызова метода, включает несколько шагов. Следующие три раздела описывают время компиляции, обрабатывая вызова метода; определение типа выражения вызова метода описывается в §15.12.3.
. Идентификатор, тогда именем метода является Идентификатор, и класс поиска является тем, названным TypeName. Если TypeName является именем интерфейса, а не класса, то ошибка времени компиляции происходит, потому что эта форма может вызвать только static методы и интерфейсы имеют нет static методы.
. Идентификатор; тогда именем метода является Идентификатор и класс, или интерфейс, чтобы искать является объявленным типом T поля, названного FieldName, если T является классом или интерфейсным типом, или верхней границей T, если T является переменной типа. superИдентификатор.NonWildTypeArgumentsopt, тогда именем метода является Идентификатор, и класс, который будет искаться, является суперклассом класса, объявление которого содержит вызов метода. Позвольте T быть описанием типа, сразу включающим вызов метода. Это - ошибка времени компиляции, если какая-либо из следующих ситуаций происходит:
superИдентификатор.NonWildTypeArgumentsopt, тогда именем метода является Идентификатор, и класс, который будет искаться, является суперклассом класса C, обозначенного ClassName. Это - ошибка времени компиляции, если C не является лексически классом включения текущего класса. Это - ошибка времени компиляции, если C является классом Object. Позвольте T быть описанием типа, сразу включающим вызов метода. Это - ошибка времени компиляции, если какая-либо из следующих ситуаций происходит:
static методы и интерфейсы имеют нет static методы. Метод применим, если это или применимо, выделяя подтипы (§15.12.2.2), применимый преобразованием вызова метода (§15.12.2.3), или это - применимый переменный метод арности (§15.12.2.4).
Процесс определения применимости начинается, определяя потенциально применимые методы (§15.12.2.1). Остаток от процесса разделяется на три фазы.
Обсуждение
Цель подразделения на фазы состоит в том, чтобы гарантировать совместимость более старыми версиями языка программирования Java.
Первая фаза (§15.12.2.2) выполняет разрешение перегрузки, не разрешая упаковывающее или распаковывающее преобразование, или использование переменного вызова метода арности. Если никакой применимый метод не находится во время этой фазы, тогда обрабатывающей, продолжается к второй фазе.
Обсуждение
Это гарантирует, что любые вызовы, которые были допустимы в более старых версиях языка, не считают неоднозначными в результате введения переменных методов арности, неявной упаковки и/или распаковывания.
Вторая фаза (§15.12.2.3) выполняет разрешение перегрузки, позволяя упаковку и распаковывание, но все еще устраняет использование переменного вызова метода арности. Если никакой применимый метод не находится во время этой фазы, тогда обрабатывающей, продолжается к третьей фазе.
Обсуждение
Это гарантирует, что переменный метод арности никогда не вызывается, если применимый фиксированный метод арности существует.
Третья фаза (§15.12.2.4) позволяет перегружаться, чтобы быть объединенной с переменными методами арности, упаковывая и распаковывая.
Решение, является ли метод применимым желанием, в случае универсальных методов (§8.4.4), требует, чтобы были определены фактические параметры типа. Фактические параметры типа можно передать явно или неявно. Если их передают неявно, они должны быть выведены (§15.12.2.7) из типов выражений параметра.
Если несколько применимых методов были идентифицированы во время одной из трех фаз тестирования применимости, то самый определенный выбирается, как определено в разделе §15.12.2.5. См. следующие подразделы для деталей.
Обсуждение
Пункт выше подразумевает, что неуниверсальный метод может быть потенциально применимым к вызову, который предоставляет явные параметры типа. Действительно, это, может оказаться, применимо. В таком случае будут просто проигнорированы параметры типа.
Это правило происходит от проблем совместимости и принципов замещаемости. Так как интерфейсы или суперклассы могут быть generified независимо от своих подтипов, мы можем переопределить универсальный метод с неуниверсальным. Однако, переопределяющий (неуниверсальный) метод должен быть применимым к звонкам в универсальный метод, включая вызовы, которые явно передают параметры типа. Иначе подтип не был бы substitutable для своего супертипа generified.
Доступен ли задействованный метод при вызове метода, зависит от модификатора доступа (public, ни один, protected, или private) в объявлении элемента и на том, где вызов метода появляется.
Класс или интерфейс, определенный шагом 1 времени компиляции (§15.12.1), ищутся все задействованные методы, которые потенциально применимы к этому вызову метода; элементы, наследованные от суперклассов и суперинтерфейсов, включаются в этот поиск.
Кроме того, если вызов метода имеет, перед левой круглой скобкой, MethodName Идентификатора формы, то поисковый процесс также исследует все методы, которые являются (a), импортированный объявлениями единственного статического импорта (§7.5.3) и объявлениями "статический импорт по требованию" (§7.5.4) в пределах единицы компиляции (§7.3), в пределах которого вызов метода происходит, и (b), не затененный (§6.3.1) в месте, где вызов метода появляется.
Если поиск не приводит по крайней мере к одному методу, который потенциально применим, то ошибка времени компиляции происходит.
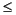 1 дюйм. Затем:
1 дюйм. Затем:
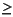 , быть формальными параметрами типа м., и позволить Кипе быть объявленным, связанным Rl, 1lp. Затем:
, быть формальными параметрами типа м., и позволить Кипе быть объявленным, связанным Rl, 1lp. Затем:  1 дюйм.
1 дюйм.
Затем позвольте Сайу = Fi [R1 = U1..., Армированный пластик =] 1 дюйм, будьте типами, выведенными для формальных параметров м.
1 дюйма, также: 1lp. 1 дюйм. Затем:
, быть формальными параметрами типа м., и позволить Кипе быть объявленным, связанным Rl, 1lp. Затем: 1 дюйм.
Затем позвольте Сайу = Fi [R1 = U1..., Армированный пластик =] 1 дюйм, будьте типами, выведенными для формальных параметров м.
1 дюйма тип ei, Ая, может быть преобразован преобразованием вызова метода (§5.3) Сайу.
1lp. 1ik. Затем:
1nk+1, быть типами формальных параметров м., где Fn = T [] для некоторого типа T, и позволяют R1... Армированный пластик p1, быть формальными параметрами типа м., и позволить Кипе быть объявленным, связанным Rl, 1lp. Затем: 1 дюйм и ограничения Aj <<T, njk.
Затем позвольте Сайу = Fi [R1 = U1..., Армированный пластик =] 1 дюйм, будьте типами, выведенными для формальных параметров м.
, быть типами формальных параметров м.
1 дюйма тип ei, Ая, может быть преобразован преобразованием вызова метода в Сайа.
, то для nik, тип ei, Ая, может быть преобразован преобразованием вызова метода в компонентный тип Sn.
1lp. Неофициальная интуиция - то, что один метод является более определенным чем другой, если какой-либо вызов, обработанный первым методом, мог бы быть передан другому без ошибки типа времени компиляции.
Один задействованный метод фиксированной арности, названный м., является более определенным чем другой задействованный метод того же самого имени и арности, если все следующие условия содержат:
, быть его формальными параметрами типа, позволял Кипе быть объявленным, связанным Rl, 1lp, позволять A1... Ap быть фактическими параметрами типа, выведенными (§15.12.2.7) для этого вызова при начальных ограничениях Ti <<Ui, 1 дюйм и позволить Сайу = Ui [R1 = A1..., Армированный пластик = Ap] 1 дюйм; иначе позвольте Сайу = Ui 1 дюйм.
1lp.
. Типы параметров первого задействованного метода являются T1..., Tn-1, Теннесси [], типы параметров другого метода являются U1..., Великобритания 1, Великобритания []. Если второй метод универсален, тогда позволяют R1... Армированный пластик p1, быть его формальными параметрами типа, позволял Кипе быть объявленным, связанным Rl, 1lp, позволять A1... Ap быть фактическими параметрами типа, выведенными (§15.12.2.7) для этого вызова при начальных ограничениях Ti <<Ui, 1ik-1, Ti <<Великобритания, семья и позволить Сайу = Ui [R1 = A1..., Армированный пластик = Ap] 1ik; иначе позвольте Сайу = Ui, 1ik. Затем: 1lp. . Типы параметров первого метода являются U1..., Великобритания 1, Великобритания [], типы параметров другого метода являются T1..., Tn-1, Теннесси []. Если второй метод универсален, тогда позволяют R1... Армированный пластик p1, быть его формальными параметрами типа, позволял Кипе быть объявленным, связанным Rl, 1lp, позволять A1... Ap быть фактическими параметрами типа, выведенными (§15.12.2.7) для этого вызова при начальных ограничениях Ui <<Ti, 1ik-1, Великобритания <<Ti, семья и позволить Сайу = Ti [R1 = A1..., Армированный пластик = Ap] 1 дюйм; иначе позвольте Сайу = Ti, 1 дюйм. Затем:
Метод m1 является строго более определенным чем другой метод m2, если и только если m1 является более определенным, чем m2 и m2 не являются более определенными чем m1.
Метод, как говорят, является максимально определенным для вызова метода, если это доступно и применимо и нет никакого другого метода, который применим и доступен, который является строго более определенным.
Если есть точно один максимально определенный метод, то тот метод является фактически самым определенным методом; это является обязательно более определенным чем любой другой доступный метод, который применим. Это тогда подвергается некоторым дальнейшим проверкам времени компиляции как описано в §15.12.3.
Возможно, что никакой метод не является самым определенным, потому что есть два или больше метода, которые являются максимально определенными. В этом случае:
abstract, это - самый определенный метод.
abstract, и у подписей всех максимально определенных методов есть то же самое стирание (§4.6), тогда самый определенный метод выбирается произвольно среди подмножества максимально определенных методов, у которых есть самый определенный тип возврата. Однако, самый определенный метод, как полагают, выдает проверенное исключение, если и только если то исключение или его стирание объявляются в throws пункты каждого из максимально определенных методов. void, тогда результат void.
1 дюйма, позвольте Fi быть формальными параметрами типа метода, позвольте Аю быть фактическими параметрами типа, выведенными для вызова метода, и позвольте R быть объявленным типом возврата вызываемого метода. Тип результата получается, применяя преобразование получения (§5.1.10) к R [F1: = A1..., Fn: =].
1 дюйма, позвольте Fi быть формальными параметрами типа метода, позвольте Аю быть фактическими параметрами типа, выведенными для вызова метода, и позвольте Эджу, 1jm быть типами исключения, объявленными в пункте бросков вызываемого метода. Пункт бросков состоит из типов Эджу [F1: = A1..., Fn: =].
Обсуждение
Процесс вывода типа по сути сложен. Поэтому, полезно дать неофициальный краткий обзор процесса прежде, чем копаться в подробной спецификации.
Вывод начинается с начального набора ограничений. Обычно, ограничения требуют, чтобы статически известные типы фактических параметров были приемлемые данный объявленные формальные типы параметра. Мы обсуждаем значение "приемлемых" ниже.
Учитывая эти начальные ограничения, можно получить ряд супертипа и/или ограничений равенства на формальные параметры типа метода или конструктора.
Затем, нужно попытаться найти решение, которое удовлетворяет ограничения на параметры типа. Как первое приближение, если параметр типа ограничивается ограничением равенства, то то ограничение дает свое решение. Примите во внимание, что ограничение может приравнять один параметр типа с другим, и только когда весь набор ограничений на все переменные типа разрешается, будет мы иметь решение.
Ограничение супертипа T:> X подразумевает, что решением является один из супертипов X. Учитывая несколько таких ограничения на T, мы можем пересечь наборы супертипов, подразумеваемых каждым из ограничений, так как параметр типа должен быть элементом всех их. Мы можем тогда выбрать наиболее определенный тип, который находится в пересечении.
Вычисления пересечения более усложняются, чем можно было бы сначала понять., Учитывая, что параметр типа ограничивается быть супертипом двух отличных вызовов универсального типа, сказать List<Object> и List<String>, наивная перекрестная работа могла бы уступить Object. Однако, более сложный анализ приводит к набору, содержащему List<?>. Точно так же, если параметр типа, T, ограничивается быть супертипом двух несвязанных интерфейсов I и J, мы могли бы вывести T должен быть Object, или мы могли бы получить более трудное, связанное I & J. Эти проблемы обсуждаются более подробно позже в этом разделе.
Мы будем использовать следующие письменные соглашения в этом разделе:
Обсуждение
В более простом мире ограничения могли иметь форму <: F - просто требующий, чтобы фактический параметр ввел быть подтипами формальных. Однако, действительность более включается. Как обсуждено ранее, тестирование применимости метода состоит из трех фаз; это требуется по причинам совместимости. Каждая фаза налагает немного отличающиеся ограничения. Если метод применим, выделяя подтипы (§15.12.2.2), ограничения действительно выделяют подтипы в ограничениях. Если метод применим преобразованием вызова метода (§15.12.2.3), ограничения подразумевают, что фактический тип конвертируем к формальному типу преобразованием вызова метода. Ситуация подобна для третьей фазы (§15.12.2.4), но точная форма ограничений отличаются из-за переменной арности.
Эти ограничения тогда уменьшаются до ряда более простых ограничений форм T:> X, T = X или T <: X, где T является параметром типа метода. Это сокращение достигается процедурой, данной ниже:
Обсуждение
Может случиться так, что начальные ограничения невыполнимы; мы говорим, что вывод сверхограничивается. В этом случае мы не обязательно получаем невыполнимые ограничения на параметры типа. Вместо этого мы можем вывести фактические параметры типа за вызов, но как только мы заменяем фактическими параметрами типа за формальные параметры типа, тест применимости может перестать работать, потому что фактические типы параметра не приемлемые данный formals, которым заменяют.
Альтернативная стратегия состояла бы в том, чтобы иметь сам вывод типа, перестали работать в таких случаях. Компиляторы могут хотеть делать так, если эффект эквивалентен определенному здесь.
Учитывая ограничение формы <<F, = F, или A>> F:
null, никакое ограничение не подразумевается на Tj.
Обсуждение
Это следует из ковариантного отношения подтипа среди типов массива. Ограничение <<F, в этом случае средства, что <<U []. A является поэтому обязательно типом V массива [], или переменная типа, верхняя граница которой является типом V массива [] - иначе, отношение <<U [] никогда не могло сохраняться. Из этого следует, что V [] <<U []. Так как выделение подтипов массива является ковариантным, оно должно иметь место что V <<U.
1kn, где U является выражением типа, которое включает Tj, то, если у A есть супертип Г формы <..., Xk-1, V, Xk+1...>, где V выражение типа, этот алгоритм применяется рекурсивно к ограничению V = U.
Обсуждение
Для простоты предположите, что Г берет единственный параметр типа. Если исследуемый вызов метода должен быть применимым, он должен иметь место, что A является подтипом некоторого вызова Г. Иначе, <<F никогда не был бы истиной.
Другими словами <<F, где F = Г <U>, подразумевает что <<Г <V> для приблизительно V. Теперь, так как U является выражением типа (и поэтому, U не является подстановочным параметром типа), это должно иметь место что U = V неразличием обычных параметризованных вызовов типа.
Формулировка выше просто обобщает это рассуждение к обобщениям с произвольным числом параметров типа.
Обсуждение
Снова, давайте сохраним вещи настолько простыми насколько возможно, и давайте рассмотрим только случай, где у Г есть единственный параметр типа.
<<F в этом случае означает <<Г <? расширяется U>. Как выше, это должно иметь место, что A является подтипом некоторого вызова Г. Однако, A может теперь быть подтипом или Г <V>, или Г <? расширяется V>, или Г <? супер V>. Мы исследуем эти случаи поочередно. Первое изменение описывается (обобщенный к многократным параметрам) подмаркером непосредственно выше. Мы поэтому имеем = Г <V> <<Г <? расширяется U>. Правила выделения подтипов для подстановочных знаков подразумевают что V <<U.
Обсуждение
Расширяя анализ выше, мы имеем = Г <? расширяет V> <<Г <? расширяется U>. Правила выделения подтипов для подстановочных знаков снова подразумевают что V <<U.
Обсуждение
Здесь, мы имеем = Г <? супер V> <<Г <? расширяется U>. Вообще, мы ничего не можем завершить в этом случае. Однако, это - не обязательно ошибка. Может случиться так, что U будет в конечном счете выведен, чтобы бытьObject, когда вызов может действительно быть допустимым. Поэтому, мы просто воздерживаемся от размещения любого ограничения на U.
Обсуждение
Как обычно мы рассматриваем только случай, где у Г есть единственный параметр типа.
<<F в этом случае означает <<Г <? супер U>. Как выше, это должно иметь место, что A является подтипом некоторого вызова Г. Май теперь быть подтипом или Г <V>, или Г <? расширяется V>, или Г <? супер V>. Мы исследуем эти случаи поочередно. Первое изменение описывается (обобщенный к многократным параметрам) подмаркером непосредственно выше. Мы поэтому имеем = Г <V> <<Г <? супер U>. Правила выделения подтипов для подстановочных знаков подразумевают это V>> U.
Обсуждение
Мы имеем = Г <? супер V> <<Г <? супер U>. Правила выделения подтипов для ниже ограниченных подстановочных знаков снова подразумевают это V>> U.
Обсуждение
Здесь, мы имеем = Г <? расширяет V> <<Г <? супер U>. Вообще, мы ничего не можем завершить в этом случае. Однако, это - не обязательно ошибка. Может случиться так, что U будет в конечном счете выведен к null введите, когда вызов может действительно быть допустимым. Поэтому, мы просто воздерживаемся от размещения любого ограничения на U.
Обсуждение
Такое ограничение никогда не является частью начальных ограничений. Однако, это может возникнуть, поскольку алгоритм рекурсивно вызывает. Мы видели, что это происходит выше, когда ограничение <<F связывает два параметризованных типа, как в Г <V> <<Г <U>.
Обсуждение
Ясно, если массив вводит U [], и V [] то же самое, их компонентные типы должны быть тем же самым.
1kn, где U является выражением типа, которое включает Tj, то, если A имеет Г формы <..., Xk-1, V, Xk+1...>, где V выражение типа, этот алгоритм применяется рекурсивно к ограничению V = U.
Обсуждение
Такие ситуации возникают, когда алгоритм рекурсивно вызывает, из-за контравариантных правил выделения подтипов, связанных с ниже ограниченными подстановочными знаками (таковые из Г формы <? супер X>).
Могло бы быть заманчиво рассмотреть A>> F как являющийся тем же самым как F <<A, но проблема вывода не симметрична. Мы должны помнить, какой участник отношения включает тип, который будет выведен.
Обсуждение
Мы не используем такие ограничения в основной части алгоритма вывода. Однако, они используются в разделе §15.12.2.8.
Обсуждение
Это следует из ковариантного отношения подтипа среди типов массива. Ограничение A>> F, в этом случае средства, что A>> U []. A является поэтому обязательно типом V массива [], или переменная типа, верхняя граница которой является типом V массива [] - иначе, отношение A>> U [] никогда не могло сохраняться. Из этого следует, что V []>> U []. Так как выделение подтипов массива является ковариантным, оно должно иметь место это V>> U.
Обсуждение
В этом случае (еще раз ограничивающий анализ унарным случаем), у нас есть ограничение A>> F = Г <U>. Необходимость быть супертипом универсального Г типа. Однако, так как A не является параметризованным типом, он не может зависеть от параметра типа U всегда. Это - супертип Г <X> для каждый X, который является допустимым параметром типа Г. Никакое значимое ограничение на U не может быть получено из A.
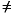 , то S1, которому позволяют..., Sn являются формальными параметрами типа Г, и позволяют H <U1..., Ul> являются уникальным вызовом H, который является супертипом Г <S1..., Sn>, и позвольте V = H <U1..., Ul> [Sk = U]. Затем, если V:> F этот алгоритм применяется рекурсивно к ограничению A>> V.
, то S1, которому позволяют..., Sn являются формальными параметрами типа Г, и позволяют H <U1..., Ul> являются уникальным вызовом H, который является супертипом Г <S1..., Sn>, и позвольте V = H <U1..., Ul> [Sk = U]. Затем, если V:> F этот алгоритм применяется рекурсивно к ограничению A>> V.
Обсуждение
Наша цель здесь состоит в том, чтобы упростить отношение между A и F. Мы стремимся рекурсивно вызывать алгоритм на более простой случай, где фактическим параметром типа, как известно, является вызов того же самого универсального описания типа как формальное.
Давайте рассматривать случай, где у и H и Г есть только единственный параметр типа. Так как у нас есть ограничение = H <X>>> F = Г <U>, где H отличен от Г, это должно иметь место, что H является некоторым надлежащим суперклассом или суперинтерфейсом Г. Должен быть (неподстановочный знак) вызовом H, который является супертипом F = Г <U>. Вызовите этот вызов V.
Если мы заменяем F V в ограничении, мы выполним цель связи двух вызовов того же самого обобщения (как это происходит, H).
Как мы вычисляем V? Объявление Г должно представить формальный параметр типа S, и должны быть немного (неподстановочный знак) вызов H, H <U1>, который является супертипом Г <S>. Заменение выражением U типа для S тогда приведет (неподстановочный знак) к вызову H, H <U1> [S = U], который является супертипом Г <U>. Например, в самом простом экземпляре, U1 мог бы быть S, когда у нас есть Г <S> <: H <S>, и Г <U> <: H <U> = H <S> [S = U] = V.
Это может иметь место, что H <U1> независим от S - то есть, S не происходит в U1 вообще. Однако, замена, описанная выше, все еще допустима - в этой ситуации, V = H <U1> [S = U] = H <U1>. Кроме того, при этом обстоятельстве, Г <T> <: H <U1> для любого T, и в определенном Г <U> <: H <U1> = V.
Независимо от того, зависит ли U1 от S, мы определили тип V, вызов H, который является супертипом Г <U>. Мы можем теперь вызвать алгоритм рекурсивно на ограничение H <X> = A>> V = H <U1> [S = U]. Мы тогда будем в состоянии связать параметры типа обоих вызовов H и извлечь соответствующие ограничения от них.
Обсуждение
Мы имеем = Г <W>>> F = Г <U> для некоторого выражения W типа. Так как W является выражением типа (и не подстановочный параметр типа), он должен иметь место что W = U неразличием параметризованных типов.
Обсуждение
Мы имеем = Г <? расширяется W>>> F = Г <U> для некоторого выражения W типа. Это должно иметь место, что W>> U, выделением подтипов управляет для подстановочных типов.
Мы имеем = Г <? супер W>>> F = Г <U> для некоторого выражения W типа. Это должно иметь место, что W <<U, выделением подтипов управляет для подстановочных типов.
Обсуждение
Еще раз ограничивая анализ унарным случаем, у нас есть ограничение A>> F = Г <? расширяется U>. Необходимость быть супертипом универсального Г типа. Однако, так как A не является параметризованным типом, он не может зависеть от U всегда. Это - супертип Г типа <? расширяется X> для каждый X так, что? расширяется X, допустимый параметр типа Г. Никакое значимое ограничение на U не может быть получено из A.
, то S1, которому позволяют..., Sn являются формальными параметрами типа Г, и позволяют H <U1..., Ul> являются уникальным вызовом H, который является супертипом Г <S1..., Sn>, и позвольте V = H <? расширяет U1...? расширяет Ul> [Sk = U]. Затем этот алгоритм применяется рекурсивно к ограничению A>> V.
Обсуждение
Наша цель здесь состоит в том, чтобы еще раз упростить отношение между A и F, и рекурсивно вызвать алгоритм на более простой случай, где фактическим параметром типа, как известно, является вызов того же самого универсального типа как формальное.
Примите и H и Г, имеют только единственный параметр типа. Так как у нас есть ограничение = H <X>>> F = Г <? расширяется U>, где H отличен от Г, он должен иметь место, что H является некоторым надлежащим суперклассом или суперинтерфейсом Г. Должен быть вызов
Как мы вычисляем H <Y>? Как прежде, отметьте, что объявление Г должно представить формальный параметр типа S, и должны быть немного (неподстановочный знак) вызов H, H <U1>, который является супертипом Г <S>. Однако, замена? расширяется U для S не обычно допустим. Чтобы видеть это, примите U1 = T [].
Вместо этого мы производим вызов H, H <? расширяет U1> [S = U]. В самом простом экземпляре U1 мог бы быть S, когда у нас есть Г <S> <: H <S>, и Г <? расширяется U> <: H <? расширяется U> = H <? расширяется S> [S = U] = V.
Обсуждение
Мы имеем = Г <? расширяется W>>> F = Г <? расширяется U> для некоторого выражения W типа. По правилам выделения подтипов для подстановочных знаков это должно иметь место это W>> U.
Обсуждение
Ограничивая анализ унарным случаем, у нас есть ограничение A>> F = Г <? супер U>. Необходимость быть супертипом универсального Г типа. Однако, так как A не является параметризованным типом, он не может зависеть от U всегда. Это - супертип Г типа <? супер X> для каждый X так, что? супер X допустимый параметр типа Г. Никакое значимое ограничение на U не может быть получено из A.
, то S1, которому позволяют..., Sn являются формальными параметрами типа Г, и позволяют H <U1..., Ul> являются уникальным вызовом H, который является супертипом Г <S1..., Sn>, и позвольте V = H <? супер U1...? Ul высшего качества> [Sk = U]. Затем этот алгоритм применяется рекурсивно к ограничению A>> V.
Обсуждение
Обработка здесь походит на случай где = Г <? расширяется U>. Здесь наш пример произвел бы вызов H <? супер U1> [S = U]
Обсуждение
Мы имеем = Г <? супер W>>> F = Г <? супер U> для некоторого выражения W типа. Это должно иметь место, что W <<U, выделением подтипов управляет для подстановочных типов.
Обсуждение
Это завершает процесс определения ограничений на формальные параметры типа метода.
Отметьте, что этот процесс не налагает ограничений на параметры типа, основанные на их объявленных границах. Как только фактические параметры типа выводятся, они будут протестированы против объявленных границ формальных параметров типа как часть тестирования применимости.
Отметьте также, что вывод типа не влияет на разумность всегда. Если выведенные типы будут бессмысленны, то вызов приведет к ошибке типа. Алгоритм вывода типа должен быть просмотрен как эвристика, разработанная к perfdorm хорошо практически. Если это не в состоянии вывести требуемый результат, явный тип paramneters может использоваться вместо этого.
Затем, для каждой переменной типа Tj, 1jn, подразумеваемые ограничения равенства разрешаются следующим образом:
Для каждого подразумеваемого ограничения равенства Tj = U или U = Tj:
. Затем все ограничения, включающие Tj, переписываются так, что, Tj заменяется Tk, и обработка продолжается со следующей переменной типа. Для типа U мы пишем ST (U) для набора супертипов U, и определяем стертый набор супертипа U,
ОЦЕНКА (U) = {V | W в ST (U) и V = |W |}
где |W | является стиранием (§4.6) W.
Обсуждение
Причина вычислений набора стертых супертипов состоит в том, чтобы иметь дело с ситуациями, где переменная типа ограничивается быть супертипом нескольких отличных вызовов универсального описания типа, Например, если T:> Список <Строка> и T:> Список <Объект>, просто пересекая ST наборов (Список <Строка>) = {Список <Строка>, Набор <Строка>, Объект} и ST (Список <Объект>) = {Список <Объект>), Набор <Объект>, Объект} привел бы к набору {Объект}, и мы потеряем след факта, что T, как может безопасно предполагаться, является Список.
Напротив, пересекая ОЦЕНКУ (Список <Строка>) = {Список, Набор, Объект} и ОЦЕНКУ (Список <Объект>) = {Список, Набор, Объект} урожаи {Список, Набор, Объект}, который мы в конечном счете позволим нам вывести T = Список <?> как описано ниже.
Стертый набор кандидата для параметра типа Tj, EC, является пересечением всей ОЦЕНКИ наборов (U) для каждого U в U1.. Великобритания. Минимальным стертым набором кандидата для Tj является
MEC = {V | V в EC, и для всего WV в EC, не то, что W <: V}
Обсуждение
Поскольку мы стремимся вывести более точные типы, мы хотим отфильтровать любых кандидатов, которые являются супертипами других кандидатов. Это - то, что выполняют вычисления MEC.
В нашем рабочем примере у нас было EC = {Список, Набор, Объект}, и теперь MEC = {Список}.
Следующий шаг должен будет восстановить фактические параметры типа за выведенные типы.
Для любого Г элемента MEC, который является универсальным описанием типа, определите соответствующие вызовы Г, Inv (G), чтобы быть:
Inv (G) = {V | 1ik, V в ST (Ui), V = Г <...>}
Обсуждение
В нашем рабочем примере единственный универсальный элемент MEC является Списком, и Inv (Список) = {Список <Строка>, Список <Объект>}. Мы теперь будем стремиться найти параметр типа за Список, который содержит (§4.5.1.1) и Строка и Объект.
Это делается посредством наименьшего количества содержащего вызов (lci) работа, определенная ниже. Первая строка определяет lci () на наборе, таком как Inv (Список), как работа в списке элементов набора. Следующая строка определяет работу в таких списках как попарное сокращение на элементах списка. Третья строка является определением lci () на парах параметризованных типов, который поочередно полагается на понятие наименьшего количества содержащего параметр типа (lcta).
lcta () определяется для всех шести возможных случаев. Затем CandidateInvocation (G) определяет самый определенный вызов универсального Г, который является, содержит все вызовы Г, которые, как известно, являются супертипами Tj. Это будет нашим вызовом кандидата Г в связанном, который мы выводим для Tj.
и позвольте CandidateInvocation (G) = lci (Inv (G)), где lci, наименьшее количество содержащее вызов определяется
lci (S) = lci (e1..., en), где ei в S, 1 дюйм
lci (e1..., en) = lci (lci (e1, e2), e3..., en)
lci (Г <X1..., Xn>, Г <Y1..., Yn>) = Г <lcta (X1, Y1)..., lcta (Xn, Yn)>
где lcta () является наименьшим количеством, содержащим функцию, определяемую параметра типа (принимающий U, и V выражения типа), как:
lcta (U, V) = U, если U = V? расширяет lub (U, V) иначе
lcta (U? расширяется V) =? расширяет lub (U, V)
lcta (U? супер V) =? супер glb (U, V)
lcta (? расширяет U? расширяется V) =? расширяет lub (U, V)
lcta (? расширяет U? супер V) = U, если U = V? иначе
lcta (? супер U? супер V) =? супер glb (U, V)
где glb () как определяется в (§5.1.10).
Обсуждение
Наконец, мы определяем направляющееся в Tj, основанный на на всех элементах минимального стертого набора кандидата его супертипов. Если какой-либо из этих элементов универсален, мы используем CandidateInvocation () функция, чтобы восстановить информацию о параметре типа.
Затем, определите Кандидата (W) = CandidateInvocation (W), если W универсален, W иначе.
Затем выведенный тип для Tj является
lub (U1... Великобритания) = Кандидат (W1) &... & Кандидат (Wr), где Wi, 1ir, являются элементами MEC.
Возможно, что процесс выше приводит к бесконечному типу. Это допустимо, и компиляторы Java должны распознать такие ситуации и представить их соответственно использование циклических структур данных.
Обсуждение
Возможность бесконечного типа происходит от рекурсивных вызовов до lub ().
Читатели, знакомые с рекурсивными типами, должны отметить, что бесконечный тип не является тем же самым как рекурсивным типом.
void; и
Любые остающиеся переменные типа, которые еще не были выведены, тогда выводятся, чтобы иметь тип Object
Object. В примере программы:
public class Doubler {
static int two() { return two(1); }
private static int two(int i) { return 2*i; }
}
class Test extends Doubler {
public static long two(long j) {return j+j; }
public static void main(String[] args) {
System.out.println(two(3));
System.out.println(Doubler.two(3)); // compile-time error
}
}
two(1) в пределах класса Doubler, есть два доступных названные метода two, но только второй применим, и так, чтобы был тот, вызванный во время выполнения. Для вызова метода two(3) в пределах класса Test, есть два применимых метода, но только тот в классе Test доступно, и так, чтобы был тот, который будет вызван во время выполнения (параметр 3 преобразовывается в тип long). Для вызова метода Doubler.two(3), класс Doubler, не класс Test, ищется названные методы two; единственный применимый метод не доступен, и таким образом, этот вызов метода вызывает ошибку времени компиляции.Другой пример:
class ColoredPoint {
int x, y;
byte color;
void setColor(byte color) { this.color = color; }
}
class Test {
public static void main(String[] args) {
ColoredPoint cp = new ColoredPoint();
byte color = 37;
cp.setColor(color);
cp.setColor(37); // compile-time error
}
}
setColor, потому что никакой применимый метод не может быть найден во время компиляции. Тип литерала 37 int, и int не может быть преобразован в byte преобразованием вызова метода. Преобразование присвоения, которое используется в инициализации переменной color, выполняет неявное преобразование константы от типа int к byte, который разрешается потому что значение 37 является достаточно маленьким, чтобы быть представленным в типе byte; но такое преобразование не позволяется для преобразования вызова метода.Если метод setColor как, однако, объявляли, взял int вместо a byte, тогда оба вызова метода были бы корректны; первый вызов был бы позволен, потому что преобразование вызова метода действительно разрешает расширяющееся преобразование из byte к int. Однако, бросок сужения тогда требовался бы в теле setColor:
void setColor(int color) { this.color = (byte)color; }
class Point { int x, y; }
class ColoredPoint extends Point { int color; }
class Test {
static void test(ColoredPoint p, Point q) {
System.out.println("(ColoredPoint, Point)");
}
static void test(Point p, ColoredPoint q) {
System.out.println("(Point, ColoredPoint)");
}
public static void main(String[] args) {
ColoredPoint cp = new ColoredPoint();
test(cp, cp); // compile-time error
}
}
Если третье определение test были добавлены:
static void test(ColoredPoint p, ColoredPoint q) {
System.out.println("(ColoredPoint, ColoredPoint)");
}
class Point { int x, y; }
class ColoredPoint extends Point { int color; }
class Test {
static int test(ColoredPoint p) {
return p.color;
}
static String test(Point p) {
return "Point";
}
public static void main(String[] args) {
ColoredPoint cp = new ColoredPoint();
String s = test(cp); // compile-time error
}
}
test тот, берущий параметр типа ColoredPoint. Поскольку тип результата метода int, ошибка времени компиляции происходит потому что int не может быть преобразован в a String преобразованием присвоения. Этот пример показывает, что типы результата методов не участвуют в разрешении перегруженных методов, так, чтобы второе test метод, который возвращает a String, не выбирается, даже при том, что у этого есть тип результата, который позволил бы примеру программы компилировать без ошибки.Так, например, рассмотрите две единицы компиляции, один для класса Point:
package points;
public class Point {
public int x, y;
public Point(int x, int y) { this.x = x; this.y = y; }
public String toString() { return toString(""); }
public String toString(String s) {
return "(" + x + "," + y + s + ")";
}
}
ColoredPoint:
package points;
public class ColoredPoint extends Point {
public static final int
RED = 0, GREEN = 1, BLUE = 2;
public static String[] COLORS =
{ "red", "green", "blue" };
public byte color;
public ColoredPoint(int x, int y, int color) {
super(x, y); this.color = (byte)color;
}
/** Copy all relevant fields of the argument into
this ColoredPoint object. */
public void adopt(Point p) { x = p.x; y = p.y; }
public String toString() {
String s = "," + COLORS[color];
return super.toString(s);
}
}
ColoredPoint:
import points.*;
class Test {
public static void main(String[] args) {
ColoredPoint cp =
new ColoredPoint(6, 6, ColoredPoint.RED);
ColoredPoint cp2 =
new ColoredPoint(3, 3, ColoredPoint.GREEN);
cp.adopt(cp2);
System.out.println("cp: " + cp);
}
}
cp: (3,3,red)
Прикладной программист, который кодировал класс Test ожидал видеть слово green, потому что фактический параметр, a ColoredPoint, имеет a color поле, и color казалось бы, был бы "соответствующим полем" (конечно, документация для пакета Points должно быть намного более точным!).
Заметьте, между прочим, что самый определенный метод (действительно, единственный применимый метод) для вызова метода adopt имеет подпись, которая указывает на метод одного параметра, и параметр имеет тип Point. Эта подпись становится частью двоичного представления класса Test произведенный компилятором и используется вызовом метода во время выполнения.
Предположите программиста, о котором сообщают эта ошибка программного обеспечения и специалист по обслуживанию points пакет решил, после должного обдумывания, исправить это, добавляя метод к классу ColoredPoint:
public void adopt(ColoredPoint p) {
adopt((Point)p); color = p.color;
}
Если прикладной программист тогда выполняет старый двоичный файл для Test с новым двоичным файлом для ColoredPoint, вывод все еще:
Test все еще имеет дескриптор "один параметр, тип которого Point; void"связанный с вызовом метода cp.adopt(cp2). Если исходный код для Test перекомпилирован, компилятор тогда обнаружит, что есть теперь два применимо adopt методы, и что подпись для более определенного является "одним параметром, тип которого ColoredPoint; void"; выполнение программы тогда произведет требуемый вывод:
cp: (3,3,green)
С предусмотрительностью о таких проблемах, специалисте по обслуживанию points пакет мог фиксировать ColoredPoint класс, чтобы работать и с недавно скомпилированным и со старым кодом, добавляя оборону кодирует к старому adopt метод ради старого кода, который все еще вызывает это на ColoredPoint параметры:
public void adopt(Point p) {
if (p instanceof ColoredPoint)
color = ((ColoredPoint)p).color;
x = p.x; y = p.y;
}
Идеально, исходный код должен быть перекомпилирован всякий раз, когда код, от которого он зависит, изменяется. Однако, в среде, где различные классы сохраняются различными организациями, это не всегда выполнимо. Безопасное программирование с внимательным отношением к проблемам развития класса может сделать обновленный код намного больше устойчивым. См. §13 для детального обсуждения совместимости на уровне двоичных кодов и введите развитие.
this (§15.8.3) не определяется.)
static. Если объявление времени компиляции для вызова метода для метода экземпляра, то ошибка времени компиляции происходит. (Причина состоит в том, что вызов метода этой формы не определяет ссылку на объект, который может служить this в пределах метода экземпляра.)
superИдентификатор.NonWildTypeArgumentsopt, тогда: abstract, ошибка времени компиляции происходит
superИдентификатор.NonWildTypeArgumentsopt, тогда: abstract, ошибка времени компиляции происходит
void, тогда вызов метода должен быть высокоуровневым выражением, то есть, Выражением в операторе выражения (§14.8) или в части ForInit или ForUpdate a for оператор (§14.14), или ошибка времени компиляции происходит. (Причина состоит в том, что такой вызов метода не производит значения и так должен использоваться только в ситуации, где значение не необходимо.)
void.
static модификатор, тогда режим вызова static.
private модификатор, тогда режим вызова nonvirtual.
super . Идентификатор или формы ClassName.super.Identifier тогда режим вызова super.
interface.
virtual. void, тогда тип выражения вызова метода является типом результата, определенным в объявлении времени компиляции.
static, тогда нет никакой целевой ссылки.
this. Это - ошибка времени компиляции если энное лексически экземпляр включения (§8.1.3) this не существует. . Идентификатор, тогда нет никакой целевой ссылки.
. Идентификатор, тогда есть два подслучая:
В любом случае, если оценка Основного выражения завершается резко, то никакая часть любого выражения параметра, кажется, не была оценена, и вызов метода завершается резко по той же самой причине.
super, включается, тогда целевая ссылка является значением this.
super, включается, тогда целевая ссылка является значением ClassName.this.
Если вызываемый метод является переменным методом арности (§8.4.1) м., у него обязательно есть n> 0 формальных параметров. У заключительного формального параметра м. обязательно есть тип T [] для некоторого T, и м. обязательно вызывается с k0 фактическими выражениями параметра.
Если м. вызывается с kn фактическими выражениями параметра, или, если м. вызывается с k=n фактическими выражениями параметра, и тип kth выражения параметра не является присвоением, совместимым с T [], то список параметров (e1..., en-1, en... ek) оценивается, как будто это было записано как (e1..., en-1, новый T [] {en..., ek}).
Выражения параметра (возможно переписанный как описано выше) теперь оцениваются, чтобы привести к значениям аргументов. Каждое значение аргумента соответствует точно одному из формальных параметров метода n.
Выражения параметра, если таковые вообще имеются, оцениваются в порядке, слева направо. Если оценка какого-либо выражения параметра завершается резко, то никакая часть любого выражения параметра с его правой стороны от него, кажется, не была оценена, и вызов метода завершается резко по той же самой причине. Результатом оценки jth выражения параметра является jth значение аргумента, для 1jn. Оценка тогда продолжается, используя значения аргументов, как описано ниже.
NoSuchMethodError (который является подклассом IncompatibleClassChangeError) происходит. Если режим вызова interface, тогда реализация должна также проверить, что целевой ссылочный тип все еще реализует указанный интерфейс. Если целевой ссылочный тип все еще не реализует интерфейс, то IncompatibleClassChangeError происходит.Реализация должна также обеспечить, во время редактирования, чтобы тип T и метод м. были доступны. Для типа T:
public, тогда T доступен.
public, тогда м. доступен. (Все элементы интерфейсов public (§9.2)).
protected, тогда м. доступен, если и только если или T находится в том же самом пакете как C, или C является T или подклассом T.
private, тогда м. доступен, если и только если C является T, или C включает T, или T включает C, или T и C оба включаются третьим классом. IllegalAccessError происходит (§12.3).
Если режим вызова static, никакая целевая ссылка не необходима, и переопределение не позволяется. Метод м. класса T является тем, который будет вызван.
Иначе, метод экземпляра должен быть вызван и есть целевая ссылка. Если целевая ссылка null, a NullPointerException бросается в эту точку. Иначе, целевая ссылка, как говорят, обращается к целевому объекту и будет использоваться в качестве значения ключевого слова this в вызванном методе. Другие четыре возможности для режима вызова тогда рассматривают.
Если режим вызова nonvirtual, переопределение не позволяется. Метод м. класса T является тем, который будет вызван.
Иначе, режим вызова interface, virtual, или super, и переопределение может произойти. Используется динамический поиск метода. Динамический процесс поиска запускается с класса S, определенного следующим образом:
interface или virtual, тогда S является первоначально фактическим классом R времени выполнения целевого объекта. Это - истина, даже если целевой объект является экземпляром массива. (Отметьте это режимом вызова interface, R обязательно реализует T; для режима вызова virtual, R является обязательно или T или подклассом T.),
super, тогда S является первоначально типом квалификации (§13.1) вызова метода. Позвольте X быть типом времени компиляции целевой ссылки вызова метода.
super или interface, тогда это - метод, который будет вызван, и процедура завершается.
virtual, и объявление в переопределениях S (§8.4.8.1) X.m, тогда метод, объявленный в S, является методом, который будет вызван, и процедура завершается. Вышеупомянутая процедура будет всегда находить, что неабстрактный, доступный метод вызывает, при условии, что все классы и интерфейсы в программе последовательно компилировались. Однако, если дело обстоит не так, то различные ошибки могут произойти. Спецификация поведения виртуальной машины Java при этих обстоятельствах дается Спецификацией виртуальной машины Java. Мы отмечаем, что динамический процесс поиска, в то время как описано здесь явно, будет часто реализовываться неявно, например поскольку побочный эффект конструкции и использование метода на класс диспетчеризируют таблицы, или конструкция других структур на класс, используемых для эффективного, диспетчеризирует.
Теперь новый фрейм активации создается, содержа целевую ссылку (если любой) и значения аргументов (если любой), так же как достаточно пространства для локальных переменных и стека для метода, который будет вызван и любая другая бухгалтерская информация, которая может быть запрошена реализацией (указатель вершины стека, счетчик программы, ссылка на предыдущий фрейм активации, и т.п.). Если нет достаточной памяти, доступной, чтобы создать такой фрейм активации, StackOverflowError бросается.
Недавно создаваемый фрейм активации становится текущим фреймом активации. Эффект этого состоит в том, чтобы присвоить значения аргументов соответствующим недавно создаваемым переменным параметра метода, и сделать целевую ссылку, доступную как this, если есть целевая ссылка. Прежде, чем каждое значение аргумента присваивается его соответствующей переменной параметра, оно подвергается преобразованию вызова метода (§5.3), который включает любое необходимое преобразование набора значений (§5.1.13).
Если стирание типа вызываемого метода отличается по его подписи от стирания типа объявления времени компиляции для вызова метода (§15.12.3), то, если какое-либо из значений аргументов является объектом, который не является экземпляром подкласса или подынтерфейсом стирания соответствующего формального параметра, вводят объявление времени компиляции для вызова метода, то a ClassCastException бросается.
Обсуждение
Как пример такой ситуации, рассмотрите объявления:
class C<T> { abstract T id(T x); }
class D extends C<String> { String id(String x) { return x; } }
Стирание фактического вызываемого методаC c = new D(); c.id(new Object()); // fails with a ClassCastException
C.id(). Прежний берет параметр типа String в то время как последние взятия параметр типа Object. Вызов перестал работать с a ClassCastException прежде, чем тело метода выполняется.Такие ситуации могут только возникнуть, если программа дает начало предупреждению непроверенному (§5.1.9).
Реализации могут осуществить их семантика, создавая мостовые методы. В вышеупомянутом примере следующий мостовой метод был бы создан в классе D:
Object id(Object x) { return id((String) x); }
c.id(new Object()) показанный выше, и это выполнит бросок и сбой, как требуется.
Если метод м. является a native метод, но необходимый собственный, зависящий от реализации двоичный код не был загружен или иначе не может быть динамически соединен, затем UnsatisfiedLinkError бросается.
Если метод м. не synchronized, управление передается телу метода м., который будет вызван.
Если метод м. synchronized, тогда объект должен быть заблокирован перед передачей управления. Никакие дальнейшие успехи не могут быть сделаны, пока текущий поток не может получить блокировку. Если есть целевая ссылка, то цель должна быть заблокирована; иначе Class объект для класса S, класса метода м., должен быть заблокирован. Управление тогда передается телу метода м., который будет вызван. Объект автоматически разблокирован, когда выполнение тела метода завершилось, или обычно или резко. Блокировка и разблокирование поведения состоят точно в том, как будто тело метода было встроено в a synchronized оператор (§14.19).
static, ссылка не исследуется, чтобы видеть, является ли это null:
class Test {
static void mountain() {
System.out.println("Monadnock");
}
static Test favorite(){
System.out.print("Mount ");
return null;
}
public static void main(String[] args) {
favorite().mountain();
}
}
ЗдесьMount Monadnock
favorite возвраты null, все же нет NullPointerException бросается.Так, например, в:
class Test {
public static void main(String[] args) {
String s = "one";
if (s.startsWith(s = "two"))
System.out.println("oops");
}
}
s прежде".startsWith"оценивается сначала, перед выражением параметра s="two". Поэтому, ссылка на строку "one" помнится как целевая ссылка прежде, чем локальная переменная s будет изменена, чтобы обратиться к строке "two". В результате startsWith метод вызывается для целевого объекта "one" с параметром "two", таким образом, результат вызова false, как строка "one" не запускается с "two". Из этого следует, что тестовая программа не печатает"oops".
class Point {
final int EDGE = 20;
int x, y;
void move(int dx, int dy) {
x += dx; y += dy;
if (Math.abs(x) >= EDGE || Math.abs(y) >= EDGE)
clear();
}
void clear() {
System.out.println("\tPoint clear");
x = 0; y = 0;
}
}
class ColoredPoint extends Point {
int color;
void clear() {
System.out.println("\tColoredPoint clear");
super.clear();
color = 0;
}
}
ColoredPoint расширяется clear абстракция определяется ее суперклассом Point. Это делает так, переопределяя clear метод с его собственным методом, который вызывает clear метод ее суперкласса, используя форму super.clear.Этот метод тогда вызывается всякий раз, когда целевой объект для вызова clear a ColoredPoint. Даже метод move в Point вызывает clear метод класса ColoredPoint когда класс this ColoredPoint, как показано выводом этой тестовой программы:
class Test {
public static void main(String[] args) {
Point p = new Point();
System.out.println("p.move(20,20):");
p.move(20, 20);
ColoredPoint cp = new ColoredPoint();
System.out.println("cp.move(20,20):");
cp.move(20, 20);
p = new ColoredPoint();
System.out.println("p.move(20,20), p colored:");
p.move(20, 20);
}
}
p.move(20,20):
Point clear
cp.move(20,20):
ColoredPoint clear
Point clear
p.move(20,20), p colored:
ColoredPoint clear
Point clear
Переопределение иногда вызывают "последней ограниченной самоссылкой"; в этом примере это означает что ссылка на clear в теле Point.move (который является действительно синтаксическим сокращением для this.clear) вызывает метод, выбранный "поздно" (во время выполнения, основанное на классе времени выполнения объекта, на который ссылаются this) а не метод, выбранный "рано" (во время компиляции, базируемый только на типе this). Это предоставляет программисту мощный способ расширить абстракции и является ключевой идеей в объектно-ориентированном программировании.
super получить доступ к элементам непосредственного суперкласса, обходя любое объявление переопределения в классе, который содержит вызов метода.Получая доступ к переменной экземпляра, super означает то же самое как бросок this (§15.11.2), но эта эквивалентность не сохраняется для вызова метода. Это демонстрируется примером:
class T1 {
String s() { return "1"; }
}
class T2 extends T1 {
String s() { return "2"; }
}
class T3 extends T2 {
String s() { return "3"; }
void test() {
System.out.println("s()=\t\t"+s());
System.out.println("super.s()=\t"+super.s());
System.out.print("((T2)this).s()=\t");
System.out.println(((T2)this).s());
System.out.print("((T1)this).s()=\t");
System.out.println(((T1)this).s());
}
}
class Test {
public static void main(String[] args) {
T3 t3 = new T3();
t3.test();
}
}
s()= 3 super.s()= 2 ((T2)this).s()= 3 ((T1)this).s()= 3
Броски к типам T1 и T2 не изменяйте метод, который вызывается, потому что метод экземпляра, который будет вызван, выбирается согласно классу времени выполнения объекта, отнесенного, чтобы быть this. Бросок не изменяет класс объекта; это только проверяет, что класс является совместимым с указанным типом.
ArrayAccess:
ExpressionName [ Expression ]
PrimaryNoNewArray [ Expression ]
Тип ссылочного выражения массива должен быть типом массива (вызовите это T [], массив, компоненты которого имеют тип T) или ошибка времени компиляции заканчивается. Затем тип выражения доступа массива является результатом применения преобразования получения (§5.1.10) к T.
Индексное выражение подвергается унарному числовому продвижению (§); продвинутый тип должен быть int.
Результатом ссылки массива является переменная типа T, а именно, переменная в пределах массива, выбранного значением индексного выражения. Эту получающуюся переменную, которая является компонентом массива, никогда не рассматривают final, даже если ссылка массива была получена из a final переменная.
null, тогда a NullPointerException бросается.
ArrayIndexOutOfBoundsException бросается.
final, даже если ссылочное выражение массива является a final переменная.) a[(a=b)[3]], выражение a полностью оценивается перед выражением (a=b)[3]; это означает что исходное значение a выбирается и помнится в то время как выражение (a=b)[3] оценивается. Этот массив, на который ссылается исходное значение a тогда преобразовывается в нижний индекс значением, которое является элементом 3 из другого массива (возможно тот же самый массив), которым сослались b и теперь также ссылаются a.Таким образом, пример:
class Test {
public static void main(String[] args) {
int[] a = { 11, 12, 13, 14 };
int[] b = { 0, 1, 2, 3 };
System.out.println(a[(a=b)[3]]);
}
}
потому что значение чудовищного выражения эквивалентно14
a[b[3]] или a[3] или 14.Если оценка выражения налево от скобок завершится резко, то никакая часть выражения в пределах скобок, будет казаться, не была оценена. Таким образом, пример:
class Test {
public static void main(String[] args) {
int index = 1;
try {
skedaddle()[index=2]++;
} catch (Exception e) {
System.out.println(e + ", index=" + index);
}
}
static int[] skedaddle() throws Exception {
throw new Exception("Ciao");
}
}
потому что встроенное присвоениеjava.lang.Exception: Ciao, index=1
2 к index никогда не происходит.Если ссылочное выражение массива производит null вместо ссылки на массив, тогда a NullPointerException бросается во время выполнения, но только после того, как все части выражения доступа массива были оценены и только если эти оценки, завершаемые обычно. Таким образом, пример:
class Test {
public static void main(String[] args) {
int index = 1;
try {
nada()[index=2]++;
} catch (Exception e) {
System.out.println(e + ", index=" + index);
}
}
static int[] nada() { return null; }
}
потому что встроенное присвоениеjava.lang.NullPointerException, index=2
2 к index происходит перед проверкой на нулевого указателя. Как связанный пример, программа:
class Test {
public static void main(String[] args) {
int[] a = null;
try {
int i = a[vamoose()];
System.out.println(i);
} catch (Exception e) {
System.out.println(e);
}
}
static int vamoose() throws Exception {
throw new Exception("Twenty-three skidoo!");
}
}
java.lang.Exception: Twenty-three skidoo!
A NullPointerException никогда не происходит, потому что индексное выражение должно быть полностью оценено прежде, чем любая часть работы индексации происходит, и это включает проверку относительно того, является ли значение левого операнда null.
++ и -- операторы. Кроме того, как обсуждено в §15.8, имена, как полагают, не являются основными выражениями, но обрабатываются отдельно в грамматике, чтобы избежать определенных неоднозначностей. Они становятся взаимозаменяемыми только здесь на уровне приоритета постфиксных выражений.
PostfixExpression:
Primary
ExpressionName
PostIncrementExpression
PostDecrementExpression
PostIncrementExpression:
PostfixExpression ++
++ оператор является постфиксным инкрементным выражением. Результатом постфиксного выражения должна быть переменная типа, который конвертируем (§5.1.8) к числовому типу, или ошибка времени компиляции происходит. Тип постфиксного инкрементного выражения является типом переменной. Результатом постфиксного инкрементного выражения не является переменная, а значение.
Во время выполнения, если оценка выражения операнда завершается резко, то постфиксное инкрементное выражение завершается резко по той же самой причине и никакому приращению, происходит. Иначе, значение 1 добавляется к значению переменной, и сумма сохранена назад в переменную. Перед дополнением двоичное числовое продвижение (§5.6.2) выполняется на значении 1 и значение переменной. В случае необходимости сумма сужается сужающимся примитивным преобразованием (§5.1.3) и/или подвергается упаковке преобразования (§5.1.7) к типу переменной прежде, чем это будет сохранено. Значение постфиксного инкрементного выражения является значением переменной прежде, чем новое значение будет сохранено.
Отметьте, что двоичное числовое упомянутое выше продвижение может включать преобразование распаковывания (§5.1.8) и преобразование набора значений (§5.1.13). В случае необходимости преобразование набора значений применяется к сумме до того, что это было сохраненным в переменной.
Переменная, которая объявляется final не может быть постепенно увеличен (если это не определенно неприсвоенное пустая заключительная переменная (§16) (§4.12.4)), потому что, когда доступ такого final переменная используется в качестве выражения, результатом является значение, не переменная. Таким образом это не может использоваться в качестве операнда постфиксного инкрементного оператора.
PostDecrementExpression:
PostfixExpression --
-- оператор является постфиксным декрементным выражением. Результатом постфиксного выражения должна быть переменная типа, который конвертируем (§5.1.8) к числовому типу, или ошибка времени компиляции происходит. Тип постфиксного декрементного выражения является типом переменной. Результатом постфиксного декрементного выражения не является переменная, а значение.
Во время выполнения, если оценка выражения операнда завершается резко, то постфиксное декрементное выражение завершается резко по той же самой причине и никакому decrementation, происходит. Иначе, значение 1 вычитается из значения переменной, и различие сохранено назад в переменную. Перед вычитанием двоичное числовое продвижение (§5.6.2) выполняется на значении 1 и значение переменной. В случае необходимости различие сужается сужающимся примитивным преобразованием (§5.1.3) и/или подвергается упаковке преобразования (§5.1.7) к типу переменной прежде, чем это будет сохранено. Значение постфиксного декрементного выражения является значением переменной прежде, чем новое значение будет сохранено.
Отметьте, что двоичное числовое упомянутое выше продвижение может включать преобразование распаковывания (§5.1.8) и преобразование набора значений (§5.1.13). В случае необходимости преобразование набора значений применяется к различию до того, что это было сохраненным в переменной.
Переменная, которая объявляется final не может быть постепенно уменьшен (если это не определенно неприсвоенное пустая заключительная переменная (§16) (§4.12.4)), потому что, когда доступ такого final переменная используется в качестве выражения, результатом является значение, не переменная. Таким образом это не может использоваться в качестве операнда постфиксного декрементного оператора.
+, -, ++, --, ~, !, и операторы броска. Выражения с группой унарных операторов справа налево, так, чтобы -~x означает то же самое как -(~x).
UnaryExpression:
PreIncrementExpression
PreDecrementExpression
+ UnaryExpression
- UnaryExpression
UnaryExpressionNotPlusMinus
PreIncrementExpression:
++ UnaryExpression
PreDecrementExpression:
-- UnaryExpression
UnaryExpressionNotPlusMinus:
PostfixExpression
~ UnaryExpression
! UnaryExpression
CastExpression
CastExpression:
( PrimitiveType ) UnaryExpression
( ReferenceType ) UnaryExpressionNotPlusMinus
++ оператор является префиксным инкрементным выражением. Результатом унарного выражения должна быть переменная типа, который конвертируем (§5.1.8) к числовому типу, или ошибка времени компиляции происходит. Тип префиксного инкрементного выражения является типом переменной. Результатом префиксного инкрементного выражения не является переменная, а значение.
Во время выполнения, если оценка выражения операнда завершается резко, то префиксное инкрементное выражение завершается резко по той же самой причине и никакому приращению, происходит. Иначе, значение 1 добавляется к значению переменной, и сумма сохранена назад в переменную. Перед дополнением двоичное числовое продвижение (§5.6.2) выполняется на значении 1 и значение переменной. В случае необходимости сумма сужается сужающимся примитивным преобразованием (§5.1.3) и/или подвергается упаковке преобразования (§5.1.7) к типу переменной прежде, чем это будет сохранено. Значение префиксного инкрементного выражения является значением переменной после того, как новое значение сохранено.
Отметьте, что двоичное числовое упомянутое выше продвижение может включать преобразование распаковывания (§5.1.8) и преобразование набора значений (§5.1.13). В случае необходимости преобразование набора значений применяется к сумме до того, что это было сохраненным в переменной.
Переменная, которая объявляется final не может быть постепенно увеличен (если это не определенно неприсвоенное пустая заключительная переменная (§16) (§4.12.4)), потому что, когда доступ такого final переменная используется в качестве выражения, результатом является значение, не переменная. Таким образом это не может использоваться в качестве операнда префиксного инкрементного оператора.
-- оператор является префиксным декрементным выражением. Результатом унарного выражения должна быть переменная типа, который конвертируем (§5.1.8) к числовому типу, или ошибка времени компиляции происходит. Тип префиксного декрементного выражения является типом переменной. Результатом префиксного декрементного выражения не является переменная, а значение.
Во время выполнения, если оценка выражения операнда завершается резко, то префиксное декрементное выражение завершается резко по той же самой причине и никакому decrementation, происходит. Иначе, значение 1 вычитается из значения переменной, и различие сохранено назад в переменную. Перед вычитанием двоичное числовое продвижение (§5.6.2) выполняется на значении 1 и значение переменной. В случае необходимости различие сужается сужающимся примитивным преобразованием (§5.1.3) и/или подвергается упаковке преобразования (§5.1.7) к типу переменной прежде, чем это будет сохранено. Значение префиксного декрементного выражения является значением переменной после того, как новое значение сохранено.
Отметьте, что двоичное числовое упомянутое выше продвижение может включать преобразование распаковывания (§5.1.8) и преобразование набора значений (§5.1.13). В случае необходимости преобразование формата применяется к различию до того, что это было сохраненным в переменной.
Переменная, которая объявляется final не может быть постепенно уменьшен (если это не определенно неприсвоенное пустая заключительная переменная (§16) (§4.12.4)), потому что, когда доступ такого final переменная используется в качестве выражения, результатом является значение, не переменная. Таким образом это не может использоваться в качестве операнда префиксного декрементного оператора.
+ оператор должен быть типом, который конвертируем (§5.1.8) к примитивному числовому типу, или ошибка времени компиляции происходит. Унарное числовое продвижение (§) выполняется на операнде. Тип унарного плюс выражение является продвинутым типом операнда. Результатом унарного плюс выражение не является переменная, а значение, даже если результатом выражения операнда является переменная.Во время выполнения значение унарного плюс выражение является продвинутым значением операнда.
- оператор должен быть типом, который конвертируем (§5.1.8) к примитивному числовому типу, или ошибка времени компиляции происходит. Унарное числовое продвижение (§) выполняется на операнде. Тип унарного минус выражение является продвинутым типом операнда.Отметьте, что унарное числовое продвижение выполняет преобразование набора значений (§5.1.13). Безотносительно набора значений, из которого оттягивается продвинутое значение операнда, унарная работа отрицания выполняется, и результат оттягивается из того же самого набора значений. Тот результат тогда подвергается дальнейшему преобразованию набора значений.
Во время выполнения значение унарного минус выражение является арифметическим отрицанием продвинутого значения операнда.
Для целочисленных значений отрицание является тем же самым как вычитанием от нуля. Использование языка программирования Java two's-дополнительное представление для целых чисел, и диапазон two's-дополнительных значений не симметрично, таким образом, отрицание максимального отрицания int или long результаты в том же самом максимальном отрицательном числе. Переполнение происходит в этом случае, но никакое исключение не выдается. Для всех целочисленных значений x, -x равняется (~x)+1.
Для значений с плавающей точкой отрицание не является тем же самым как вычитанием от нуля, потому что если x +0.0, тогда 0.0-x +0.0, но -x -0.0. Унарный минус просто инвертирует знак числа с плавающей точкой. Особые случаи интереса:
~ оператор должен быть типом, который конвертируем (§5.1.8) к примитивному целочисленному типу, или ошибка времени компиляции происходит. Унарное числовое продвижение (§) выполняется на операнде. Тип унарного поразрядного дополнительного выражения является продвинутым типом операнда.
Во время выполнения значение унарного поразрядного дополнительного выражения является поразрядным дополнением продвинутого значения операнда; отметьте что во всех случаях, ~x равняется (-x)-1.
! оператор должен быть boolean или Boolean, или ошибка времени компиляции происходит. Тип унарного логического дополнительного выражения boolean.
Во время выполнения операнд подвергается распаковыванию преобразования (§5.1.8) в случае необходимости; значение унарного логического дополнительного выражения true если (возможно преобразованный) значение операнда false и false если (возможно преобразованный) значение операнда true.
boolean; или проверки, во время выполнения, что ссылочное значение обращается к объекту, класс которого является совместимым с указанным ссылочным типом.
CastExpression:
( PrimitiveType Dimsopt ) UnaryExpression
( ReferenceType ) UnaryExpressionNotPlusMinus
См. §15.15 для обсуждения различия между UnaryExpression и UnaryExpressionNotPlusMinus.
Тип выражения броска является результатом применения преобразования получения (§5.1.10) к типу, имя которого появляется в пределах круглых скобок. (Круглые скобки и тип, который они содержат, иногда вызывают оператором броска.) Результатом выражения броска не является переменная, а значение, даже если результатом выражения операнда является переменная.
Оператор броска не имеет никакого эффекта на выбор набора значений (§4.2.3) для значения типа float или введите double. Следовательно, бросок, чтобы ввести float в пределах выражения, которое не строго FP (§15.4), не обязательно заставляет его значение быть преобразованным в элемент набора значений плавающего, и бросок, чтобы ввести double в пределах выражения, которое не строго FP, не обязательно заставляет его значение быть преобразованным в элемент двойного набора значений.
Это - ошибка времени компиляции, если тип времени компиляции операнда никогда не может бросаться к типу, определенному оператором броска согласно правилам кастинга преобразования (§5.5). Иначе, во время выполнения, значение операнда преобразовывается (в случае необходимости), бросая преобразование в тип, определенный оператором броска.
Некоторые броски приводят к ошибке во время компиляции. Некоторые броски, как могут доказывать, во время компиляции, всегда корректны во время выполнения. Например, это всегда корректно, чтобы преобразовать значение типа класса к типу его суперкласса; во время выполнения такой бросок не должен потребовать никакого специального действия. Наконец, некоторые броски, как могут доказывать, не являются или всегда корректными или всегда неправильными во время компиляции. Во время выполнения такие броски требуют теста. Видьте детали §5.5.
AClassCastException бросается, если бросок, как находят, во время выполнения непозволителен.*, /, и % вызываются мультипликативными операторами. Они имеют тот же самый приоритет и синтаксически левоассоциативны (они группируются слева направо).
MultiplicativeExpression:
UnaryExpression
MultiplicativeExpression * UnaryExpression
MultiplicativeExpression / UnaryExpression
MultiplicativeExpression % UnaryExpression
int или long, тогда целочисленная арифметика выполняется; если этот продвинутый тип float или double, тогда арифметика с плавающей точкой выполняется.Отметьте, что двоичное числовое продвижение выполняет преобразование распаковывания (§5.1.8) и преобразование набора значений (§5.1.13).
* оператор выполняет умножение, производя продукт его операндов. Умножение является коммутативной работой, если у выражений операнда нет никаких побочных эффектов. В то время как целочисленное умножение ассоциативно, когда операнды являются всем тем же самым типом, умножение с плавающей точкой не ассоциативно.Если целочисленное умножение переполняется, то результатом являются биты младшего разряда математического продукта как представлено в некотором достаточно большом two's-дополнительном формате. В результате, если переполнение происходит, то знак результата, возможно, не то же самое как знак математического продукта двух значений операнда.
Результатом умножения с плавающей точкой управляют правила арифметики IEEE 754:
float, тогда набор значений плавающий должен быть выбран.
double, тогда двойной набор значений должен быть выбран. float, тогда или набор значений плавающий или набор значений "расширенная экспонента плавающая" могут быть выбраны в прихоти реализации.
double, тогда или двойной набор значений или набор значений "двойная расширенная экспонента" могут быть выбраны в прихоти реализации. Затем, значение должно быть выбрано из выбранного набора значений, чтобы представить продукт. Если величина продукта является слишком большой, чтобы представить, мы говорим переполнения работы; результатом является тогда бесконечность соответствующего знака. Иначе, продукт округляется к самому близкому значению в выбранном наборе значений, используя режим раунда-к-самому-близкому IEEE 754. Язык программирования Java требует поддержки постепенной потери значимости как определено IEEE 754 (§4.2.4).
* никогда не бросает исключение на этапе выполнения./ оператор выполняет подразделение, производя частное его операндов. Левый операнд является дивидендом, и правый операнд является делителем.
Целочисленное деление округляется к 0. Таким образом, частное, произведенное для операндов n и d, которые являются целыми числами после двоичного числового продвижения (§5.6.2), является целочисленным значением q, чья величина как можно больше, удовлетворяя |d · q || n |; кроме того q положителен, когда у |n || d | и n и d есть тот же самый знак, но q отрицателен, когда у |n || d | и n и d есть противоположные знаки. Есть один особый случай, который не удовлетворяет это правило: если дивиденд является отрицательным целым числом самой большой величины для ее типа, и делитель -1, тогда целочисленное переполнение происходит, и результат равен дивиденду. Несмотря на переполнение, никакое исключение не выдается в этом случае. С другой стороны, если значение делителя в целочисленном делении 0, тогда ArithmeticException бросается.
Результат подразделения с плавающей точкой определяется спецификацией арифметики IEEE:
float, тогда набор значений плавающий должен быть выбран.
double, тогда двойной набор значений должен быть выбран. float, тогда или набор значений плавающий или набор значений "расширенная экспонента плавающая" могут быть выбраны в прихоти реализации.
double, тогда или двойной набор значений или набор значений "двойная расширенная экспонента" могут быть выбраны в прихоти реализации. Затем, значение должно быть выбрано из выбранного набора значений, чтобы представить частное. Если величина частного является слишком большой, чтобы представить, мы говорим переполнения работы; результатом является тогда бесконечность соответствующего знака. Иначе, частное округляется к самому близкому значению в выбранном наборе значений, используя режим раунда-к-самому-близкому IEEE 754. Язык программирования Java требует поддержки постепенной потери значимости как определено IEEE 754 (§4.2.4).
/ никогда не бросает исключение на этапе выполнения% оператор, как говорят, приводит к остатку от его операндов от подразумеваемого подразделения; левый операнд является дивидендом, и правый операнд является делителем.В C и C++, оператор остатка принимает только интегральные операнды, но в языке программирования Java, это также принимает операнды с плавающей точкой.
Работа остатка для операндов, которые являются целыми числами после двоичного числового продвижения (§5.6.2), производит значение результата так, что(a/b)*b+(a%b) равно a. Эти идентификационные данные содержат даже в особом случае, что дивиденд является отрицательным целым числом самой большой величины для ее типа, и делитель -1 (остаток 0). Это следует из этого правила, что результат работы остатка может быть отрицательным, только если дивиденд отрицателен, и может быть положительным, только если дивиденд положителен; кроме того величина результата всегда является меньше чем величина делителя. Если значение делителя для целочисленного оператора остатка 0, тогда ArithmeticException бросается. Примеры:
Результат работы остатка с плавающей точкой как вычислено5%3 produces 2 (note that 5/3 produces 1) 5%(-3) produces 2 (note that 5/(-3) produces -1) (-5)%3 produces -2 (note that (-5)/3 produces -1) (-5)%(-3) produces -2 (note that (-5)/(-3) produces 1)
% оператор не является тем же самым как произведенным работой остатка, определенной IEEE 754. Работа остатка IEEE 754 вычисляет остаток от округляющегося подразделения, не подразделения усечения, и таким образом, его поведение не походит на это обычного целочисленного оператора остатка. Вместо этого язык программирования Java определяет % на операциях с плавающей точкой, чтобы вести себя способом, аналогичным тому из целочисленного оператора остатка; это может быть по сравнению с библиотечной функцией C fmod. Работа остатка IEEE 754 может быть вычислена библиотечной подпрограммой Math.IEEEremainder.Результат работы остатка с плавающей точкой определяется правилами арифметики IEEE:
% никогда не бросает исключение на этапе выполнения, даже если правый операнд является нулем. Переполнение, потеря значимости, или потеря точности не могут произойти.Примеры:
5.0%3.0 produces 2.0 5.0%(-3.0) produces 2.0 (-5.0)%3.0 produces -2.0 (-5.0)%(-3.0) produces -2.0
+ и - вызываются аддитивными операторами. Они имеют тот же самый приоритет и синтаксически левоассоциативны (они группируются слева направо).
AdditiveExpression:
MultiplicativeExpression
AdditiveExpression + MultiplicativeExpression
AdditiveExpression - MultiplicativeExpression
String, тогда работа является конкатенацией строк.
Иначе, тип каждого из операндов + оператор должен быть типом, который конвертируем (§5.1.8) к примитивному числовому типу, или ошибка времени компиляции происходит.
В каждом случае, типе каждого из операндов двоичного файла - оператор должен быть типом, который конвертируем (§5.1.8) к примитивному числовому типу, или ошибка времени компиляции происходит.
String, тогда преобразование строк выполняется на другом операнде, чтобы произвести строку во время выполнения. Результатом является ссылка на a String объект (недавно создаваемый, если выражение не является константным выражением времени компиляции (§15.28)), который является связью двух строк операнда. Символы левого операнда предшествуют символам правого операнда в недавно создаваемой строке. Если операнд типа String null, тогда строка"null"используется вместо того операнда.String преобразованием строк.Значение x типа примитива T сначала преобразовывается в ссылочное значение как будто, давая это как параметр соответствующему выражению создания экземпляра класса:
boolean, тогда используйте new Boolean(x).
char, тогда используйте new Character(x).
byte, short, или int, тогда используйте new Integer(x).
long, тогда используйте new Long(x).
float, тогда используйте new Float(x).
double, тогда используйте new Double(x). String преобразованием строк.
Теперь только ссылочные значения нужно рассмотреть. Если ссылка null, это преобразовывается в строку"null"(четыре символа ASCII n, u, l, l). Иначе, преобразование выполняется как будто вызовом toString метод объекта, на который ссылаются, без параметров; но если результат вызова toString метод null, тогда строка"null"используется вместо этого.
toString метод определяется исконным классом Object; много классов переопределяют это, особенно Boolean, Character, Integer, Long, Float, Double, и String.
String объект. Чтобы увеличить производительность повторной конкатенации строк, компилятор Java может использовать StringBuffer класс или подобный метод, чтобы сократить количество промежуточного звена String объекты, которые создаются оценкой выражения.Для типов примитивов реализация может также оптимизировать далеко создание объекта обертки, преобразовывая непосредственно от типа примитива до строки.
приводит к результату:"The square root of 2 is " + Math.sqrt(2)
"The square root of 2 is 1.4142135623730952"
+ оператор синтаксически левоассоциативен, независимо от того решается ли это позже анализом типа представить конкатенацию строк или дополнение. В некоторых случаях забота обязана получать требуемый результат. Например, выражение:
всегда расценивается как значение:a + b + c
Поэтому результат выражения:(a + b) + c
:1 + 2 + " fiddlers"
но результат:"3 fiddlers"
:"fiddlers " + 1 + 2
"fiddlers 12"
В этом шутливом небольшом примере:
class Bottles {
static void printSong(Object stuff, int n) {
String plural = (n == 1) ? "" : "s";
loop: while (true) {
System.out.println(n + " bottle" + plural
+ " of " + stuff + " on the wall,");
System.out.println(n + " bottle" + plural
+ " of " + stuff + ";");
System.out.println("You take one down "
+ "and pass it around:");
--n;
plural = (n == 1) ? "" : "s";
if (n == 0)
break loop;
System.out.println(n + " bottle" + plural
+ " of " + stuff + " on the wall!");
System.out.println();
}
System.out.println("No bottles of " +
stuff + " on the wall!");
}
}
метод printSong напечатает версию детской песни. Популярные значения для материала включают "pop" и "beer"; самое популярное значение для n 100. Вот вывод, который следует Bottles.printSong("slime", 3):
3 bottles of slime on the wall, 3 bottles of slime; You take one down and pass it around: 2 bottles of slime on the wall! 2 bottles of slime on the wall, 2 bottles of slime; You take one down and pass it around: 1 bottle of slime on the wall! 1 bottle of slime on the wall, 1 bottle of slime; You take one down and pass it around: No bottles of slime on the wall!
В коде отметьте осторожную условную генерацию исключительного"bottle"когда соответствующий, а не множественное число"bottles"; отметьте также, как оператор конкатенации строк использовался, чтобы повредить длинную постоянную строку:
"You take one down and pass it around:"
в две части, чтобы избежать неудобно длинной линии в исходном коде.
+ оператор выполняет дополнение когда применено к два операнда числового типа, производя сумму операндов. Двоичный файл - оператор выполняет вычитание, производя различие двух числовых операндов.
Двоичное числовое продвижение выполняется на операндах (§5.6.2). Тип аддитивного выражения на числовых операндах является продвинутым типом своих операндов. Если этот продвинутый тип int или long, тогда целочисленная арифметика выполняется; если этот продвинутый тип float или double, тогда арифметика с плавающей точкой выполняется.
Отметьте, что двоичное числовое продвижение выполняет преобразование набора значений (§5.1.13) и преобразование распаковывания (§5.1.8).
Дополнение является коммутативной работой, если у выражений операнда нет никаких побочных эффектов. Целочисленное дополнение ассоциативно, когда операнды являются всем тем же самым типом, но дополнение с плавающей точкой не ассоциативно.
Если целочисленное дополнение переполняется, то результатом являются биты младшего разряда математической суммы как представлено в некотором достаточно большом two's-дополнительном формате. Если переполнение происходит, то знак результата не является тем же самым как знаком математической суммы двух значений операнда.
Результат дополнения с плавающей точкой определяется, используя следующие правила арифметики IEEE:
float, тогда набор значений плавающий должен быть выбран.
double, тогда двойной набор значений должен быть выбран. float, тогда или набор значений плавающий или набор значений "расширенная экспонента плавающая" могут быть выбраны в прихоти реализации.
double, тогда или двойной набор значений или набор значений "двойная расширенная экспонента" могут быть выбраны в прихоти реализации. Затем, значение должно быть выбрано из выбранного набора значений, чтобы представить сумму. Если величина суммы является слишком большой, чтобы представить, мы говорим переполнения работы; результатом является тогда бесконечность соответствующего знака. Иначе, сумма округляется к самому близкому значению в выбранном наборе значений, используя режим раунда-к-самому-близкому IEEE 754. Язык программирования Java требует поддержки постепенной потери значимости как определено IEEE 754 (§4.2.4).
- оператор выполняет вычитание когда применено к два операнда числового типа, производящего различие его операндов; левый операнд является уменьшаемым, и правый операнд является вычитаемым. И для целочисленного и для вычитания с плавающей точкой, это всегда имеет место это a-b приводит к тому же самому результату как a+(-b).
Отметьте, что для целочисленных значений вычитание от нуля является тем же самым как отрицанием. Однако, для операндов с плавающей точкой, вычитание от нуля не является тем же самым как отрицанием, потому что если x +0.0, тогда 0.0-x +0.0, но -x -0.0.
Несмотря на то, что переполнение, потеря значимости, или потеря информации могут произойти, оценка числового аддитивного оператора никогда не бросает исключение на этапе выполнения.
<<, сдвиг вправо со знаком >>, и сдвиг вправо без знака >>>; они синтаксически левоассоциативны (они группируются слева направо). Левый операнд оператора сдвига является значением, которое будет смещено; правый операнд определяет расстояние сдвига.
ShiftExpression:
AdditiveExpression
ShiftExpression << AdditiveExpression
ShiftExpression >> AdditiveExpression
ShiftExpression >>> AdditiveExpression
Если продвинутый тип левого операнда int, только пять битов самых низкоуровневых правого операнда используются в качестве расстояния сдвига. Это - как будто правый операнд был подвергнут поразрядной логической операции И & (§15.22.1) со значением маски 0x1f. Расстояние сдвига, фактически используемое, находится поэтому всегда в диапазоне от 0 до 31, включительно.
Если продвинутый тип левого операнда long, тогда только шесть битов самых низкоуровневых правого операнда используются в качестве расстояния сдвига. Это - как будто правый операнд был подвергнут поразрядной логической операции И & (§15.22.1) со значением маски 0x3f. Расстояние сдвига, фактически используемое, находится поэтому всегда в диапазоне от 0 до 63, включительно.
Во время выполнения операции сдвига выполняются на дополнительном целочисленном представлении two значения левого операнда.
Значение n<<s n лево-смещенный s позиции двоичного разряда; это эквивалентно (даже если переполнение происходит) к умножению два к питанию s.
Значение n>>s n смещенный на право s позиции двоичного разряда с расширением знака. Получающееся значение является n/s. Для неотрицательных значений n, это эквивалентно усечению целочисленного деления, как вычислено оператором целочисленного деления /, два к питанию s.
Значение n>>>s n смещенный на право s позиции двоичного разряда с дополнением нулями. Если n положительно, тогда результатом является то же самое как тот из n>>s; если n отрицательно, результат равен тому из выражения (n>>s)+(2<<~s) если тип левого операнда int, и к результату выражения (n>>s)+(2L<<~s) если тип левого операнда long. Добавленный термин (2<<~s) или (2L<<~s) уравновешивает распространенный знаковый бит. (Отметьте что из-за неявного маскирования правого операнда оператора сдвига, ~s поскольку расстояние сдвига эквивалентно 31-s смещаясь int значение и к 63-s смещаясь a long значение.)
a<b<c синтаксические анализы как (a<b)<c, который всегда является ошибкой времени компиляции, потому что тип a<bвсегда boolean и < не оператор на boolean значения.
RelationalExpression:
ShiftExpression
RelationalExpression < ShiftExpression
RelationalExpression > ShiftExpression
RelationalExpression <= ShiftExpression
RelationalExpression >= ShiftExpression
RelationalExpression instanceof ReferenceType
boolean.int или long, тогда сравнение целого числа со знаком выполняется; если этот продвинутый тип float или double, тогда сравнение с плавающей точкой выполняется.Отметьте, что двоичное числовое продвижение выполняет преобразование набора значений (§5.1.13) и преобразование распаковывания (§5.1.8). Сравнение выполняется точно на значениях с плавающей точкой, независимо от того из каких наборов значений их значения представления были оттянуты.
Результат сравнения с плавающей точкой, как определено спецификацией стандарта IEEE 754:
false.
-0.0<0.0 false, например, но -0.0<=0.0 true. (Отметьте, однако, что методы Math.min и Math.max обработайте отрицательный нуль, как являющийся строго меньшим чем положительный нуль.)
< оператор true если значение левого операнда является меньше чем значение правого операнда, и иначе false.
<= оператор true если значение левого операнда меньше чем или равно значению правого операнда, и иначе false.
> оператор true если значение левого операнда больше чем значение правого операнда, и иначе false.
>= оператор true если значение левого операнда больше чем или равно значению правого операнда, и иначе false. instanceof оператор должен быть ссылочным типом или нулевым типом; иначе, ошибка времени компиляции происходит. ReferenceType упоминал после instanceof оператор должен обозначить ссылочный тип; иначе, ошибка времени компиляции происходит. Это - ошибка времени компиляции если ReferenceType, упомянутый после instanceof оператор не обозначает тип reifiable (§4.7).
Во время выполнения, результат instanceof оператор true если значение RelationalExpression не null и ссылка могла быть брошена (§15.16) к ReferenceType, не повышая a ClassCastException. Иначе результат false.
Если бы бросок RelationalExpression к ReferenceType был бы отклонен как ошибка времени компиляции, то instanceof реляционное выражение аналогично производит ошибку времени компиляции. В такой ситуации, результате instanceof выражение никогда не могло быть true.
Рассмотрите пример программы:
class Point { int x, y; }
class Element { int atomicNumber; }
class Test {
public static void main(String[] args) {
Point p = new Point();
Element e = new Element();
if (e instanceof Point) { // compile-time error
System.out.println("I get your point!");
p = (Point)e; // compile-time error
}
}
}
(Point)e является неправильным потому что никакой экземпляр Element или любой из его возможных подклассов (ни один не показывают здесь) мог возможно быть экземпляром любого подкласса Point. instanceof выражение является неправильным по точно той же самой причине. Если, с другой стороны, класс Point был подкласс Element (по общему признанию странное понятие в этом примере):
class Point extends Element { int x, y; }
instanceof выражение тогда было бы разумно и допустимо. Бросок (Point)e никогда не повышал бы исключение, потому что оно не будет выполняться если значение e не мог правильно быть брошен, чтобы ввести Point.
a==b==c синтаксические анализы как (a==b)==c. Тип результата a==bвсегда boolean, и c должен поэтому иметь тип boolean или ошибка времени компиляции происходит. Таким образом, a==b==c не тестирует, чтобы видеть ли a, b, и c все равны.
EqualityExpression:
RelationalExpression
EqualityExpression == RelationalExpression
EqualityExpression != RelationalExpression
a<b==c<d true всякий раз, когда a<b и c<d имейте то же самое значение истинности.
Операторы равенства могут использоваться, чтобы сравнить два операнда, которые конвертируемы (§5.1.8) к числовому типу, или два операнда типа boolean или Boolean, или два операнда, которые являются каждым из ссылочного типа или нулевого типа. Все другие случаи приводят к ошибке времени компиляции. Тип выражения равенства всегда boolean.
Во всех случаях, a!=b приводит к тому же самому результату как !(a==b). Операторы равенства являются коммутативными, если у выражений операнда нет никаких побочных эффектов.
int или long, тогда целочисленный тест равенства выполняется; если продвинутый тип float или double, тогда тест равенства с плавающей точкой выполняется.Отметьте, что двоичное числовое продвижение выполняет преобразование набора значений (§5.1.13) и преобразование распаковывания (§5.1.8). Сравнение выполняется точно на значениях с плавающей точкой, независимо от того из каких наборов значений их значения представления были оттянуты.
Тестирование равенства с плавающей точкой выполняется в соответствии с правилами стандарта IEEE 754:
== false но результат != true. Действительно, тест x!=x истина если и только если значение x НЭН. (Методы Float.isNaN и Double.isNaN май также использоваться, чтобы протестировать, является ли значением НЭН.)
-0.0==0.0 true, например.
== оператор true если значение левого операнда равно значению правого операнда; иначе, результат false.
!= оператор true если значение левого операнда не равно значению правого операнда; иначе, результат false. boolean, или если один операнд имеет тип boolean и другой имеет тип Boolean, тогда работа является булевым равенством. Булевы операторы равенства ассоциативны.
Если один из операндов имеет тип Boolean это подвергается распаковыванию преобразования (§5.1.8).
Результат == true если операнды (после того, как кто-либо требуемое преобразование распаковывания) являются обоими true или оба false; иначе, результат false.
Результат != false если операнды - оба true или оба false; иначе, результат true. Таким образом != ведет себя то же самое как ^ (§15.22.2), когда применялся к булевым операндам.
Ошибка времени компиляции происходит, если невозможно преобразовать тип любого операнда к типу другого преобразованием кастинга (§5.5). Значения времени выполнения этих двух операндов обязательно были бы неравны.
Во время выполнения, результат == true если значения операнда - оба null или оба обращаются к тому же самому объекту или массиву; иначе, результат false.
Результат != false если значения операнда - оба null или оба обращаются к тому же самому объекту или массиву; иначе, результат true.
В то время как == может использоваться, чтобы сравнить ссылки типа String, такой тест равенства определяет, обращаются ли эти два операнда к тому же самому String объект. Результат false если операнды отличны String объекты, даже если они содержат ту же самую последовательность символов. Содержание двух строк s и t может быть протестирован на равенство вызовом метода s.equals(t). См. также §3.10.5.
&, монопольная операция ИЛИ ^, и содержащая операция ИЛИ |. У этих операторов есть различный приоритет, с & наличие наивысшего приоритета и | самый низкий приоритет. Каждый из этих операторов синтаксически левоассоциативен (каждый группируется слева направо). Каждый оператор является коммутативным, если у выражений операнда нет никаких побочных эффектов. Каждый оператор ассоциативен.
AndExpression:
EqualityExpression
AndExpression & EqualityExpression
ExclusiveOrExpression:
AndExpression
ExclusiveOrExpression ^ AndExpression
InclusiveOrExpression:
ExclusiveOrExpression
InclusiveOrExpression | ExclusiveOrExpression
boolean. Все другие случаи приводят к ошибке времени компиляции.&, ^, или | имеют тип, который конвертируем (§5.1.8) к примитивному целочисленному типу, двоичное числовое продвижение сначала выполняется на операндах (§5.6.2). Тип выражения логического оператора является продвинутым типом операндов.
Для &, значение результата является поразрядным И значений операнда.
Для ^, значение результата является битовым исключающим "ИЛИ" значений операнда.
Для |, значение результата является поразрядным содержащим ИЛИ значений операнда.
Например, результат выражения 0xff00 & 0xf0f0 0xf000. Результат 0xff00 ^ 0xf0f0 0x0ff0Результат.The 0xff00 | 0xf0f0 0xfff0.
&, ^, или | оператор имеет тип boolean или Boolean, тогда тип выражения логического оператора boolean. Во всех случаях операнды подвергаются распаковыванию преобразования (§5.1.8) по мере необходимости.
Для &, значение результата true если оба значения операнда true; иначе, результат false.
Для ^, значение результата true если значения операнда отличаются; иначе, результат false.
Для |, значение результата false если оба значения операнда false; иначе, результат true.
&& оператор походит & (§15.22.2), но оценивает его правый операнд, только если значение его левого операнда true. Это синтаксически левоассоциативно (это группируется слева направо). Это полностью ассоциативно относительно обоих побочных эффектов и значения результата; то есть, для любых выражений a, b, и c, оценки выражения ((a)&&(b))&&(c) приводит к тому же самому результату, с теми же самыми побочными эффектами, происходящими в том же самом порядке, как оценка выражения (a)&&((b)&&(c)).
ConditionalAndExpression:
InclusiveOrExpression
ConditionalAndExpression && InclusiveOrExpression
&& должен иметь тип boolean или Boolean, или ошибка времени компиляции происходит. Тип условного выражения - и выражение всегда boolean.
Во время выполнения левое выражение операнда оценивается сначала; если у результата есть тип Boolean, это подвергается распаковыванию преобразования (§5.1.8); если получающееся значение false, значение условного выражения - и выражение false и правое выражение операнда не оценивается. Если значение левого операнда true, тогда правое выражение оценивается; если у результата есть тип Boolean, это подвергается распаковыванию преобразования (§5.1.8); получающееся значение становится значением условного выражения - и выражение. Таким образом, && вычисляет тот же самый результат как & на boolean операнды. Это отличается только по этому, правое выражение операнда оценивается условно, а не всегда.
|| оператор походит | (§15.22.2), но оценивает его правый операнд, только если значение его левого операнда false. Это синтаксически левоассоциативно (это группируется слева направо). Это полностью ассоциативно относительно обоих побочных эффектов и значения результата; то есть, для любых выражений a, b, и c, оценки выражения ((a)||(b))||(c) приводит к тому же самому результату, с теми же самыми побочными эффектами, происходящими в том же самом порядке, как оценка выражения (a)||((b)||(c)).
ConditionalOrExpression:
ConditionalAndExpression
ConditionalOrExpression || ConditionalAndExpression
|| должен иметь тип boolean или Boolean, или ошибка времени компиляции происходит. Тип условного выражения - или выражение всегда boolean.
Во время выполнения левое выражение операнда оценивается сначала; если у результата есть тип Boolean, это подвергается распаковыванию преобразования (§5.1.8); если получающееся значение true, значение условного выражения - или выражение true и правое выражение операнда не оценивается. Если значение левого операнда false, тогда правое выражение оценивается; если у результата есть тип Boolean, это подвергается распаковыванию преобразования (§5.1.8); получающееся значение становится значением условного выражения - или выражение.
Таким образом, || вычисляет тот же самый результат как | на boolean или Boolean операнды. Это отличается только по этому, правое выражение операнда оценивается условно, а не всегда.
? : использует булево значение одного выражения, чтобы решить, какое из двух других выражений должно быть оценено.
Условный оператор синтаксически правоассоциативен (это группируется справа налево), так, чтобы a?b:c?d:e?f:g означает то же самое как a?b:(c?d:(e?f:g)).
ConditionalExpression:
ConditionalOrExpression
ConditionalOrExpression ? Expression : ConditionalExpression
? появляется между первыми и вторыми выражениями, и : появляется между вторыми и третьими выражениями.
Первое выражение должно иметь тип boolean или Boolean, или ошибка времени компиляции происходит.
Отметьте, что это - ошибка времени компиляции или для второго или для третьего выражения операнда, чтобы быть вызовом a void метод. Фактически, не разрешается для условного выражения появиться в любом контексте где вызов a void метод мог появиться (§14.8).
Тип условного выражения определяется следующим образом:
boolean и тип другого имеет тип Boolean, тогда тип условного выражения boolean.
byte или Byte и другой имеет тип short или Short, тогда тип условного выражения short.
byte, short, или char, и другой операнд является константным выражением типа int чье значение является представимым в типе T, тогда тип условного выражения является T.
Byte и другой операнд является константным выражением типа int чье значение является представимым в типе byte, тогда тип условного выражения byte.
Short и другой операнд является константным выражением типа int чье значение является представимым в типе short, тогда тип условного выражения short.
Character и другой операнд является константным выражением типа int чье значение является представимым в типе char, тогда тип условного выражения char.
boolean значение тогда используется, чтобы выбрать или второе или третье выражение операнда:
true, тогда второе выражение операнда выбирается.
false, тогда третье выражение операнда выбирается. a=b=c средства a=(b=c), который присваивает значение c к b и затем присваивает значение b к a.
AssignmentExpression:
ConditionalExpression
Assignment
Assignment:
LeftHandSide AssignmentOperator AssignmentExpression
LeftHandSide:
ExpressionName
FieldAccess
ArrayAccess
AssignmentOperator: one of
= *= /= %= += -= <<= >>= >>>= &= ^= |=
Во время выполнения результатом выражения присвоения является значение переменной после того, как присвоение произошло. Результатом выражения присвоения не является самостоятельно переменная.
Переменная, которая объявляется final не может быть присвоен (если это не определенно неприсвоенное пустая заключительная переменная (§16) (§4.12.4)), потому что, когда доступ такого final переменная используется в качестве выражения, результатом является значение, не переменная, и таким образом, это не может использоваться в качестве первого операнда оператора присваивания.
Во время выполнения выражение оценивается одним из трех способов:
static и результат оценки e выше null, тогда a NullPointerException бросается.
null, тогда никакое присвоение не происходит и a NullPointerException бросается.
ArrayIndexOutOfBoundsException бросается.
Компилятор может быть в состоянии доказать во время компиляции, что компонент массива будет иметь TC типа точно (например, TC мог бы быть final). Но если компилятор не может доказать во время компиляции, что компонент массива будет иметь TC типа точно, затем проверка должна быть выполнена во время выполнения, чтобы гарантировать, что RC класса является присвоением, совместимым (§5.2) с фактическим SC типа компонента массива. Эта проверка подобна броску сужения (§5.5, §15.16), за исключением того, что, если проверка перестала работать, ArrayStoreException бросается, а не a ClassCastException. Поэтому:
ArrayStoreException бросается. Иначе, значение правого операнда преобразовывается в тип левой переменной, подвергается преобразованию набора значений (§5.1.13) к соответствующему стандартному набору значений (не набор значений расширенной экспоненты), и результат преобразования сохранен в переменную. Правила для присвоения на компонент массива иллюстрируются следующим примером программы:
class ArrayReferenceThrow extends RuntimeException { }
class IndexThrow extends RuntimeException { }
class RightHandSideThrow extends RuntimeException { }
class IllustrateSimpleArrayAssignment {
static Object[] objects = { new Object(), new Object() };
static Thread[] threads = { new Thread(), new Thread() };
static Object[] arrayThrow() {
throw new ArrayReferenceThrow();
}
static int indexThrow() { throw new IndexThrow(); }
static Thread rightThrow() {
throw new RightHandSideThrow();
}
static String name(Object q) {
String sq = q.getClass().getName();
int k = sq.lastIndexOf('.');
return (k < 0) ? sq : sq.substring(k+1);
}
static void testFour(Object[] x, int j, Object y) {
String sx = x == null ? "null" : name(x[0]) + "s";
String sy = name(y);
System.out.println();
try {
System.out.print(sx + "[throw]=throw => ");
x[indexThrow()] = rightThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print(sx + "[throw]=" + sy + " => ");
x[indexThrow()] = y;
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print(sx + "[" + j + "]=throw => ");
x[j] = rightThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print(sx + "[" + j + "]=" + sy + " => ");
x[j] = y;
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
}
public static void main(String[] args) {
try {
System.out.print("throw[throw]=throw => ");
arrayThrow()[indexThrow()] = rightThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print("throw[throw]=Thread => ");
arrayThrow()[indexThrow()] = new Thread();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print("throw[1]=throw => ");
arrayThrow()[1] = rightThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print("throw[1]=Thread => ");
arrayThrow()[1] = new Thread();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
testFour(null, 1, new StringBuffer());
testFour(null, 1, new StringBuffer());
testFour(null, 9, new Thread());
testFour(null, 9, new Thread());
testFour(objects, 1, new StringBuffer());
testFour(objects, 1, new Thread());
testFour(objects, 9, new StringBuffer());
testFour(objects, 9, new Thread());
testFour(threads, 1, new StringBuffer());
testFour(threads, 1, new Thread());
testFour(threads, 9, new StringBuffer());
testFour(threads, 9, new Thread());
}
}
Самый интересный случай партии является одной тринадцатой от конца:throw[throw]=throw => ArrayReferenceThrow throw[throw]=Thread => ArrayReferenceThrow throw[1]=throw => ArrayReferenceThrow throw[1]=Thread => ArrayReferenceThrow null[throw]=throw => IndexThrow null[throw]=StringBuffer => IndexThrow null[1]=throw => RightHandSideThrow null[1]=StringBuffer => NullPointerException null[throw]=throw => IndexThrow null[throw]=StringBuffer => IndexThrow null[1]=throw => RightHandSideThrow null[1]=StringBuffer => NullPointerException null[throw]=throw => IndexThrow null[throw]=Thread => IndexThrow null[9]=throw => RightHandSideThrow null[9]=Thread => NullPointerException null[throw]=throw => IndexThrow null[throw]=Thread => IndexThrow null[9]=throw => RightHandSideThrow null[9]=Thread => NullPointerException Objects[throw]=throw => IndexThrow Objects[throw]=StringBuffer => IndexThrow Objects[1]=throw => RightHandSideThrow Objects[1]=StringBuffer => Okay! Objects[throw]=throw => IndexThrow Objects[throw]=Thread => IndexThrow Objects[1]=throw => RightHandSideThrow Objects[1]=Thread => Okay! Objects[throw]=throw => IndexThrow Objects[throw]=StringBuffer => IndexThrow Objects[9]=throw => RightHandSideThrow Objects[9]=StringBuffer => ArrayIndexOutOfBoundsException Objects[throw]=throw => IndexThrow Objects[throw]=Thread => IndexThrow Objects[9]=throw => RightHandSideThrow Objects[9]=Thread => ArrayIndexOutOfBoundsException Threads[throw]=throw => IndexThrow Threads[throw]=StringBuffer => IndexThrow Threads[1]=throw => RightHandSideThrow Threads[1]=StringBuffer => ArrayStoreException Threads[throw]=throw => IndexThrow Threads[throw]=Thread => IndexThrow Threads[1]=throw => RightHandSideThrow Threads[1]=Thread => Okay! Threads[throw]=throw => IndexThrow Threads[throw]=StringBuffer => IndexThrow Threads[9]=throw => RightHandSideThrow Threads[9]=StringBuffer => ArrayIndexOutOfBoundsException Threads[throw]=throw => IndexThrow Threads[throw]=Thread => IndexThrow Threads[9]=throw => RightHandSideThrow Threads[9]=Thread => ArrayIndexOutOfBoundsException
который указывает что попытка сохранить ссылку на aThreads[1]=StringBuffer => ArrayStoreException
StringBuffer в массив, компоненты которого имеют тип Thread броски ArrayStoreException. Код корректен типом во время компиляции: у присвоения есть левая сторона типа Object[] и правая сторона типа Object. Во время выполнения, первый фактический параметр методу testFour ссылка на экземпляр "массива Thread"и третьим фактическим параметром является ссылка на экземпляр класса StringBuffer.= (T)((E1) op (E2)), где T является типом E1, за исключением того, что E1 оценивается только однажды. Например, следующий код корректен:
и результаты вshort x = 3; x += 4.6;
x наличие значения 7 потому что это эквивалентно:
Во время выполнения выражение оценивается одним из двух способов. Если левое выражение операнда не является выражением доступа массива, то четыре шага требуются:short x = 3; x = (short)(x + 4.6);
null, тогда никакое присвоение не происходит и a NullPointerException бросается.
ArrayIndexOutOfBoundsException бросается.
String. Поскольку класс String a final класс, S должен также быть String. Поэтому проверка на этапе выполнения, которая иногда требуется для простого оператора присваивания, никогда не требуется для составного оператора присваивания. +=). Если эта работа завершается резко, то выражение присвоения завершается резко по той же самой причине, и никакое присвоение не происходит. String результат бинарной операции сохранен в компонент массива.Правила для составного присвоения на компонент массива иллюстрируются следующим примером программы:
class ArrayReferenceThrow extends RuntimeException { }
class IndexThrow extends RuntimeException { }
class RightHandSideThrow extends RuntimeException { }
class IllustrateCompoundArrayAssignment {
static String[] strings = { "Simon", "Garfunkel" };
static double[] doubles = { Math.E, Math.PI };
static String[] stringsThrow() {
throw new ArrayReferenceThrow();
}
static double[] doublesThrow() {
throw new ArrayReferenceThrow();
}
static int indexThrow() { throw new IndexThrow(); }
static String stringThrow() {
throw new RightHandSideThrow();
}
static double doubleThrow() {
throw new RightHandSideThrow();
}
static String name(Object q) {
String sq = q.getClass().getName();
int k = sq.lastIndexOf('.');
return (k < 0) ? sq : sq.substring(k+1);
}
static void testEight(String[] x, double[] z, int j) {
String sx = (x == null) ? "null" : "Strings";
String sz = (z == null) ? "null" : "doubles";
System.out.println();
try {
System.out.print(sx + "[throw]+=throw => ");
x[indexThrow()] += stringThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print(sz + "[throw]+=throw => ");
z[indexThrow()] += doubleThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print(sx + "[throw]+=\"heh\" => ");
x[indexThrow()] += "heh";
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print(sz + "[throw]+=12345 => ");
z[indexThrow()] += 12345;
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print(sx + "[" + j + "]+=throw => ");
x[j] += stringThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print(sz + "[" + j + "]+=throw => ");
z[j] += doubleThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print(sx + "[" + j + "]+=\"heh\" => ");
x[j] += "heh";
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print(sz + "[" + j + "]+=12345 => ");
z[j] += 12345;
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
}
public static void main(String[] args) {
try {
System.out.print("throw[throw]+=throw => ");
stringsThrow()[indexThrow()] += stringThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print("throw[throw]+=throw => ");
doublesThrow()[indexThrow()] += doubleThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print("throw[throw]+=\"heh\" => ");
stringsThrow()[indexThrow()] += "heh";
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print("throw[throw]+=12345 => ");
doublesThrow()[indexThrow()] += 12345;
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print("throw[1]+=throw => ");
stringsThrow()[1] += stringThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print("throw[1]+=throw => ");
doublesThrow()[1] += doubleThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print("throw[1]+=\"heh\" => ");
stringsThrow()[1] += "heh";
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print("throw[1]+=12345 => ");
doublesThrow()[1] += 12345;
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
testEight(null, null, 1);
testEight(null, null, 9);
testEight(strings, doubles, 1);
testEight(strings, doubles, 9);
}
}
Самые интересные случаи партии являются десятыми и одиннадцатыми от конца:throw[throw]+=throw => ArrayReferenceThrow throw[throw]+=throw => ArrayReferenceThrow throw[throw]+="heh" => ArrayReferenceThrow throw[throw]+=12345 => ArrayReferenceThrow throw[1]+=throw => ArrayReferenceThrow throw[1]+=throw => ArrayReferenceThrow throw[1]+="heh" => ArrayReferenceThrow throw[1]+=12345 => ArrayReferenceThrow null[throw]+=throw => IndexThrow null[throw]+=throw => IndexThrow null[throw]+="heh" => IndexThrow null[throw]+=12345 => IndexThrow null[1]+=throw => NullPointerException null[1]+=throw => NullPointerException null[1]+="heh" => NullPointerException null[1]+=12345 => NullPointerException null[throw]+=throw => IndexThrow null[throw]+=throw => IndexThrow null[throw]+="heh" => IndexThrow null[throw]+=12345 => IndexThrow null[9]+=throw => NullPointerException null[9]+=throw => NullPointerException null[9]+="heh" => NullPointerException null[9]+=12345 => NullPointerException Strings[throw]+=throw => IndexThrow doubles[throw]+=throw => IndexThrow Strings[throw]+="heh" => IndexThrow doubles[throw]+=12345 => IndexThrow Strings[1]+=throw => RightHandSideThrow doubles[1]+=throw => RightHandSideThrow Strings[1]+="heh" => Okay! doubles[1]+=12345 => Okay! Strings[throw]+=throw => IndexThrow doubles[throw]+=throw => IndexThrow Strings[throw]+="heh" => IndexThrow doubles[throw]+=12345 => IndexThrow Strings[9]+=throw => ArrayIndexOutOfBoundsException doubles[9]+=throw => ArrayIndexOutOfBoundsException Strings[9]+="heh" => ArrayIndexOutOfBoundsException doubles[9]+=12345 => ArrayIndexOutOfBoundsException
Они - случаи, где правая сторона, которая выдает исключение фактически, добирается, чтобы выдать исключение; кроме того они - единственное такие случаи в партии. Это демонстрирует, что оценка правого операнда действительно происходит после проверок на нулевое ссылочное значение массива и за пределы индексное значение.Strings[1]+=throw => RightHandSideThrow doubles[1]+=throw => RightHandSideThrow
Следующая программа иллюстрирует факт, что значение левой стороны составного присвоения сохраняется прежде, чем правая сторона оценивается:
class Test {
public static void main(String[] args) {
int k = 1;
int[] a = { 1 };
k += (k = 4) * (k + 2);
a[0] += (a[0] = 4) * (a[0] + 2);
System.out.println("k==" + k + " and a[0]==" + a[0]);
}
}
Значениеk==25 and a[0]==25
1 из k сохраняется составным оператором присваивания += перед его правым операндом (k = 4) * (k + 2) оценивается. Оценка этого правого операнда тогда присваивается 4 к k, вычисляет значение 6 для k + 2, и затем умножается 4 6 добраться 24. Это добавляется к сохраненному значению 1 добраться 25, который тогда сохранен в k += оператор. Идентичный анализ применяется к случаю, который использует a[0]. Короче говоря, операторы
ведите себя точно тем же самым способом как операторы:k += (k = 4) * (k + 2); a[0] += (a[0] = 4) * (a[0] + 2);
k = k + (k = 4) * (k + 2); a[0] = a[0] + (a[0] = 4) * (a[0] + 2);
Expression:
AssignmentExpression
В отличие от C и C++, у языка программирования Java нет никакого оператора запятой.
ConstantExpression:
Expression
Константное выражение времени компиляции является выражением, обозначающим значение типа примитива или a String это не завершается резко и составляется, используя только следующее:
String (§3.10.5)
String
+, -, ~, и ! (но нет ++ или --)
*, /, и %
+ и -
<<, >>, и >>>
<, <=, >, и >= (но нет instanceof)
== и !=
&, ^, и |
&& и условное выражение - или оператор ||
? :
. Идентификатор, которые обращаются к постоянным переменным (§4.12.4). case метки в switch у операторов (§14.11) и есть специальное значение для преобразования присвоения (§5.2). Константы времени компиляции типа String всегда "интернируются", чтобы совместно использовать уникальные экземпляры, используя метод String.intern.Константное выражение времени компиляции всегда обрабатывается как строгое FP (§15.4), даже если бы происходит в контексте, где неконстантное выражение, как полагали бы, не было бы строго FP.
Примеры константных выражений:
true (short)(1*2*3*4*5*6) Integer.MAX_VALUE / 2 2.0 * Math.PI "The integer " + Long.MAX_VALUE + " is mighty big."
| Содержание | Предыдущий | Следующий | Индекс | Спецификация языка Java Третий Выпуск |
Авторское право © 1996-2005 Sun Microsystems, Inc. Все права защищены
Пожалуйста, отправьте любые комментарии или исправления через нашу