Параллелизм и OpenGL
Параллелизм является понятием многократных вещей, происходящих одновременно. В контексте компьютеров параллелизм обычно относится к выполняющимся задачам больше чем на одном процессоре одновременно. Путем выполнения работы параллельно, задачи, завершенные раньше, и приложения, становятся более быстро реагирующими пользователю. Хорошие новости - то, что хорошо разработанные приложения OpenGL уже показывают определенную форму параллелизма — параллелизм между обработкой приложения на CPU и обработкой OpenGL на GPU. Многие методы, представленные в Стратегиях Проектирования приложений OpenGL, нацелены в частности на создавание приложений OpenGL, показывающих большой параллелизм CPU-GPU. Однако современные компьютеры не только содержат мощный GPU, но также и содержат многократный CPUs. Иногда тот CPUs имеет многократные ядра, каждый способный к выполнению вычислений независимо от других. Критически важно, что приложения разработаны для использования в своих интересах параллелизма, если это возможно. Разработка параллельного приложения означает анализировать работу, которую Ваше приложение выполняет в подзадачи и идентификацию, которой задачи могут безопасно управлять параллельно и какие задачи должны быть выполнены последовательно — т.е. какие задачи зависят или от ресурсов, используемых другими задачами или от результатов, возвращенных из тех задач.
Каждый процесс в OS X составлен из одного или более потоков. Поток является потоком выполнения, выполняющего код для процесса. Многожильные системы предлагают истинный параллелизм, позволяя многократным потокам выполниться одновременно. Apple предлагает и традиционные потоки и функцию под названием Grand Central Dispatch (GCD). Центральная Отгрузка позволяет Вам анализировать свое приложение в меньшие задачи, не требуя, чтобы приложение управляло потоками. GCD выделяет потоки на основе числа ядер, доступных в системе, и автоматически планирует задачи к тем потокам.
В более высоком уровне, предложениях Какао NSOperation и NSOperationQueue обеспечить абстракцию Objective C для создания и планирования единиц работы. На OS X v10.6, очереди работы используют GCD для диспетчеризации работы; на OS X v10.5, очереди работы создают потоки для выполнения задач приложения.
Эта глава не пытается, описывают эти технологии подробно. Перед рассмотрением, как добавить параллелизм к приложению OpenGL, Вы должны первое readConcurrency Руководство по программированию. Если Вы планируете управление потоками вручную, необходимо также считать Руководство по программированию Поточной обработки. Независимо от которого метода Вы используете, существуют дополнительные ограничения при вызове OpenGL в многопоточных системах. Эта глава помогает Вам понять, когда многопоточность улучшает Вашу производительность приложения OpenGL, ограничения места OpenGL на многопоточных приложениях и общих стратегиях проектирования, Вы могли бы использовать для реализации параллелизма в приложении OpenGL. Некоторые из этих методов проектирования могут получить Вас улучшение всего нескольких строк кода.
Идентификация, может ли приложение OpenGL получить преимущества от параллелизма
Создавание многопоточного приложения требует значительного усилия в проекте, реализации и тестировании Вашего приложения. Потоки также добавляют сложность и наверху к приложению. Например, Ваше приложение, возможно, должно скопировать данные так, чтобы это могло быть вручено рабочему потоку, или многократные потоки, возможно, должны синхронизировать доступ к тем же ресурсам. Прежде чем Вы попытаетесь реализовать параллелизм в приложении OpenGL, необходимо оптимизировать код OpenGL в однопоточной среде с помощью методов, описанных в Стратегиях Проектирования приложений OpenGL. Внимание на достижение большого параллелизма CPU-GPU сначала и затем оценивает, может ли параллельное программирование обеспечить дополнительный выигрыш в производительности.
Хороший кандидат имеет или или обе из следующих характеристик:
Приложение выполняет много задач на CPU, который независим от рендеринга OpenGL. Игры, например, моделируют игровой мир, вычисляют искусственный интеллект от управляемых компьютером противников и звук игры. Можно использовать параллелизм в этом сценарии, потому что многие из этих задач не зависят от кода для прорисовки OpenGL.
Профилирование Вашего приложения показало, что Ваш код рендеринга OpenGL проводит много времени в CPU. В этом сценарии GPU неактивен, потому что Ваше приложение неспособно к питанию, это управляет достаточно быстро. Если Ваш ограниченный CPU код был уже оптимизирован, можно быть в состоянии улучшить его производительность далее путем разделения работы на задачи, выполняющиеся одновременно.
Если Ваше приложение блокируется, ожидая GPU и не имеет никакой работы, оно может выполнить параллельно с ее командами рисования OpenGL, то это не хороший кандидат на параллелизм. Если CPU и GPU оба неактивны, то Ваши потребности OpenGL, вероятно, достаточно просты, что никакая дальнейшая настройка не полезна.
Для получения дополнительной информации о том, как определить, где Ваше приложение проводит свое время, посмотрите Настройку Вашего Приложения OpenGL.
OpenGL ограничивает каждый контекст единственным потоком
Каждый поток в процессе OS X имеет единственный текущий контекст рендеринга OpenGL. Каждый раз, когда Ваше приложение вызывает функцию OpenGL, OpenGL неявно ищет контекст, связанный с текущим потоком, и изменяет состояние или объекты, связанные с тем контекстом.
OpenGL не повторно используем. При изменении того же контекста от многократных потоков одновременно результаты непредсказуемы. Ваше приложение могло бы отказать, или оно могло бы представить неправильно. Если по некоторым причинам Вы решаете установить больше чем один поток для предназначения для того же контекста, то необходимо синхронизировать потоки путем размещения взаимного исключения вокруг всех вызовов OpenGL к контексту, такой как gl* и CGL*. Команды OpenGL, блокирующие — такой как fence команды — не синхронизируют потоки.
GCD и NSOperationQueue объекты могут оба выполнить Ваши задачи на потоке их выбора. Они могут создать поток в частности для той задачи, или они могут снова использовать существующий поток. Но в любом случае, Вы не можете гарантировать, какой поток выполняет задачу. Для приложения OpenGL, означающего:
Каждая задача должна установить контекст прежде, чем выполнить любые команды OpenGL.
Ваше приложение должно гарантировать, что двум задачам, получающим доступ к тому же контексту, не позволяют выполниться одновременно.
Стратегии реализации параллелизма в приложениях OpenGL
Параллельное приложение OpenGL хочет фокусироваться на параллелизме CPU так, чтобы OpenGL мог обеспечить больше работы для GPU. Вот несколько рекомендуемых стратегий реализации параллелизма в приложении OpenGL:
Анализируйте свое приложение в OpenGL и задачи не-OpenGL, которые могут выполниться одновременно. Ваш код рендеринга OpenGL выполняется как единственная задача, таким образом, он все еще выполняется в единственном потоке. Эта стратегия работает лучше всего, когда Ваше приложение имеет другие задачи, требующие значительной обработки CPU.
Если профилирование производительности показывает, что Ваше приложение проводит много процессорного времени в OpenGL, можно переместить часть той обработки к другому потоку путем включения многопоточности в механизме OpenGL. Преимущество этого метода является своей простотой; включение многопоточного механизма OpenGL проводит всего несколько строк кода. Посмотрите Многопоточный OpenGL.
Если Ваше приложение тратит много данных подготовки процессорного времени для отправки к openGL, можно разделить работу между задачами, подготавливающими данные рендеринга и задачи, представляющие команды рендеринга OpenGL. Посмотрите Выполняют Вычисления OpenGL в Задаче Работника
Если Ваше приложение имеет многократные сцены, оно может представить одновременно или работать, оно может выполнить в многократных контекстах, оно может создать многократные задачи с контекстом OpenGL на задачу. Если контексты могут совместно использовать те же ресурсы, можно использовать совместное использование контекста, когда контексты создаются для совместного использования объектов OpenGL или поверхностей: дисплейные списки, текстуры, вершина и программы фрагмента, объекты массива вершины, и т.д. Посмотрите Использование Многократные Контексты OpenGL
Многопоточный OpenGL
Каждый раз, когда Ваше приложение вызывает OpenGL, средство рендеринга обрабатывает параметры для помещения их в формат, который понимают аппаратные средства. Время, требуемое обработать эти команды, варьируется в зависимости от того, являются ли вводы уже в благоприятном для аппаратных средств формате, но всегда существуют немного наверху в подготовке команд для аппаратных средств.
Если Ваше приложение проводит много времени, выполняя вычисления в OpenGL, и Вы уже предприняли шаги для выбора идеальных форматов данных, приложение могло бы получить дополнительную выгоду путем включения многопоточности в механизме OpenGL. Многопоточный механизм OpenGL автоматически создает рабочий поток и передает некоторые его вычисления к тому потоку. В многожильной системе это позволяет внутренним вычислениям OpenGL, выполняемым на CPU действовать параллельно с Вашим приложением, улучшая производительность. Синхронизирующиеся функции продолжают блокировать вызывающий поток.
Перечисление 14-1 показывает код, требуемый включить многопоточный механизм OpenGL.
Перечисление 14-1 , Разрешающее многопоточный механизм OpenGL
CGLError err = 0; |
CGLContextObj ctx = CGLGetCurrentContext(); |
// Enable the multithreading |
err = CGLEnable( ctx, kCGLCEMPEngine); |
if (err != kCGLNoError ) |
{ |
// Multithreaded execution may not be available |
// Insert your code to take appropriate action |
} |
Включение многопоточности прибывает в стоимость — OpenGL должен скопировать параметры для передачи их к рабочему потоку. Из-за этих издержек необходимо всегда тестировать приложение с, и без многопоточности включил, чтобы определить, обеспечивает ли это улучшение исполнения всех условий.
Выполните вычисления OpenGL в задаче работника
Некоторые приложения выполняют много вычислений на их данных перед передачей тех данных к средству рендеринга OpenGL. Например, приложение могло бы создать новую геометрию или анимировать существующую геометрию. Где возможно, такие вычисления должны быть выполнены в OpenGL. Например, вершинные шейдеры и расширение обратной связи преобразования могли бы позволить Вам выполнять эти вычисления полностью в OpenGL. Это использует в своих интересах больший параллелизм, доступный в GPU, и сокращает издержки копирования результатов между Вашим приложением и OpenGL.
Подход описал в альтернативах рисунка 9-3 между обновлением объектов OpenGL и выполнением команд рендеринга, использующих те объекты. OpenGL представляет на GPU параллельно с обновлениями Вашего приложения, работающими на CPU. Если вычисления, выполняемые на CPU, занимают больше времени обработки, чем те на GPU, то GPU проводит больше неактивного времени. В этой ситуации можно быть в состоянии использовать в своих интересах параллелизм в системах с многократным CPUs. Разделите свой код рендеринга OpenGL на отдельное вычисление и обработку задач, и выполните их параллельно. Рисунок 14-1 показывает ясное разделение труда. Одна задача производит данные, использующиеся вторым и представленным к OpenGL.
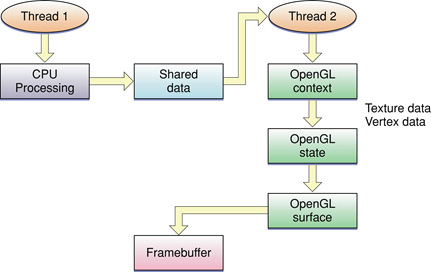
Для лучшей производительности Ваше приложение должно избежать копировать данные между задачами. Например, вместо того, чтобы вычислить данные в одной задаче и скопировать его в буферный объект вершины в другом, отобразитесь, буферный объект вершины в установке кодируют и вручают указатель непосредственно на задачу работника.
Если Ваше приложение может далее анализировать задачу модификаций в подзадачи, можно видеть лучшие преимущества. Например, примите два или больше буфера вершины, каждый из которых должен быть обновлен прежде, чем представить команды рисования. Каждый может быть повторно вычислен независимо от других. В этом сценарии модификации к каждому буферу становятся работой, с помощью NSOperationQueue объект управлять работой:
Установите текущий контекст.
Отобразите первый буфер.
Создайте
NSOperationвозразите, чья задача состоит в том, чтобы заполнить тот буфер.Очередь, что работа на очереди работы.
Выполните шаги 2 - 4 для других буферов.
Вызвать
waitUntilAllOperationsAreFinishedна очереди работы.Не отобразите буферы.
Выполните команды рендеринга.
В многожильной системе многократные потоки выполнения могут позволить буферам быть заполненными одновременно. Шаги 7 и 8 могли даже быть выполнены отдельной работой, поставленной в очередь на ту же очередь работы, при условии, что работа установила надлежащие зависимости.
Используйте многократные контексты OpenGL
Если Ваше приложение имеет многократные сцены, которые могут быть представлены параллельно, можно использовать контекст для каждой сцены, которую необходимо представить. Создайте один контекст для каждой сцены и присвойте каждый контекст работе или задаче. Поскольку каждая задача имеет свой собственный контекст, все могут представить команды рендеринга параллельно.
Специфичный для Apple OpenGL APIs также предоставляет возможность для совместного использования данных между контекстами, как показано на рисунке 14-2. Совместно используемые ресурсы автоматически устанавливаются как взаимное исключение (взаимное исключение) объекты. Заметьте, что распараллеливают 2, рисует к пиксельному буферу, соединяющемуся с общим состоянием как текстура. Поток 1 может тогда нарисовать использование та текстура.
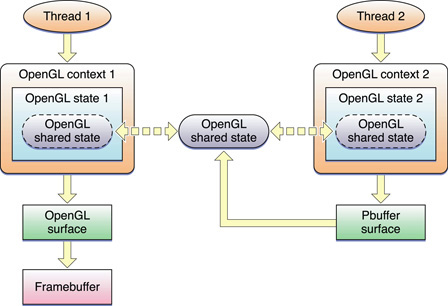
Это - наиболее сложная модель для разработки приложения. Изменения в объектах в одном контексте должны быть сброшены так, чтобы другие контексты видели изменения. Точно так же, когда Ваше приложение заканчивает воздействовать на объект, оно должно сбросить те команды перед выходом, чтобы гарантировать, что все команды рендеринга были представлены аппаратным средствам.
Инструкции для поточной обработки приложений OpenGL
Следуйте этим инструкциям для обеспечения успешной поточной обработки в приложении, использующем OpenGL:
Используйте только один поток на контекст. Команды OpenGL для определенного контекста не ориентированы на многопотоковое исполнение. У Вас никогда не должно быть больше чем одного потока, получающего доступ к единственному контексту одновременно.
Контексты, которые находятся на различных потоках, могут совместно использовать объектные ресурсы. Например, приемлемо для одного контекста в одном потоке изменить текстуру и второй контекст во втором потоке для изменения той же текстуры. Обработка общего объекта, предоставленная Apple APIs автоматически, защищает от ошибок потока. И, Ваше приложение следует за «одним потоком на контекст» инструкция.
Когда Вы используете
NSOpenGLViewобъект с приказами OpenGL, изданными от потока кроме основного, необходимо установить взаимоисключающую блокировку. Взаимоисключающая блокировка необходима, потому что, если Вы не переопределяете поведение по умолчанию, основной поток, возможно, должен связаться с представлением для таких вещей как изменение размеров.Приложения, использующие Objective C с многопоточностью, могут заблокировать контексты с помощью функций
CGLLockContextиCGLUnlockContext. Если Вы хотите выполнить рендеринг в потоке кроме основного, можно заблокировать контекст, что Вы хотите получить доступ и безопасно выполнить команды OpenGL. Вызовы блокировки должны быть помещены вокруг всех Ваших вызовов OpenGL во всех потоках.CGLLockContextблокирует поток, он идет, пока все другие потоки не разблокировали тот же контекст с помощью функцииCGLUnlockContext. Можно использоватьCGLLockContextрекурсивно. Зависящие от контекста вызовы CGL собой не требуют блокировки, но можно гарантировать последовательную обработку для группы вызовов путем окружения ихCGLLockContextиCGLUnlockContext. Следует иметь в виду, что вызовы от OpenGL API (API, предоставленный Рабочей группой OpenGL Khronos), требуют блокировки.Отслеживайте текущий контекст. При переключении потоков просто переключить контексты непреднамеренно, который вызывает непредвиденные эффекты на выполнение графических команд. Необходимо установить текущий контекст при переключении на недавно создаваемый поток.