Автовекторизатор
GPUs обрабатывают скалярные данные эффективно, но CPU потребности векторизованные данные для хранения его полностью занятым. Что означает, что, или Вы пишете различное ядро для каждого устройства, на котором Ваше приложение могло бы работать, каждый оптимизированный для того устройства, или производительность приложения пострадает.
Автовекторизатор обнаруживает операции в скалярной программе, которая может быть выполнена параллельно и преобразовывает их в векторные операции, которые могут быть обработаны эффективно сегодняшним CPUs. Если Вы знаете о выполнении кода через автовекторизатор можно записать единственную, простую скалярную программу, зная, что автовекторизатор векторизует тот код для Вас так, чтобы его производительность на CPU была максимизирована, в то время как тот же код работает на GPU, как записано.
Что делает автовекторизатор
Достигает повышений производительности до векторной ширины CPU без дополнительного усилия с Вашей стороны.
Позволяет Вам писать одно ядро, работающее эффективно на CPU или GPU.
Единицы работы пакетов вместе в векторные инструкции.
-
Генерирует цикл по всей рабочей группе.
Выполнения по умолчанию, компилируя ядра в CPU.
Если автовекторизация успешна, размер рабочей группы может быть увеличен.
Выполнения по умолчанию при компиляции в CPU.
Запись оптимального кода для CPU
Записать код, который может лучше всего быть оптимизирован автовекторизатором:
Сделать
-
Запишите единственное ядро, которое может работать на CPU и GPU. Используйте надлежащие типы данных (скаляр или плавание) по мере необходимости Вашим алгоритмом.
Переместитесь неконтролируемый доступ к памяти текут если возможный; например:
if (condition)
a[index] = 1
else
a[index] = 2
должен быть кодирован как:
if (condition)
tmp = 1;
else
tmp = 2;
a[index] = tmp;
При доступе к элементам матрицы, лучше доступ последовательные элементы матрицы в последовательных единицах работы. Посмотрите Таблицу 14-2 для реального примера того, как получить доступ к последовательным элементам матрицы в последовательных единицах работы наиболее эффективно.
Не делать
-
Запишите специфичную для устройства оптимизацию.
-
Запишите поток управления зависимого ID единицы работы, если это возможно. (Если бы это происходит во многих местах в коде, он, вероятно, препятствовал бы тому, чтобы успешно выполнилась автовекторизация.)
Включение и отключение автовекторизатора в XCode
Можно отключить или повторно включить автовекторизацию в настройках сборки XCode для приложений OpenCL. По умолчанию автовекторизатор включен при генерации ядер в XCode. Выбрать No выключить автовекторизатор. Эта установка вступает в силу только для CPU.
|
Установка |
Ввести |
Значение по умолчанию |
Флаг командной строки |
|---|---|---|---|
|
Автовекторизатор |
Булевская переменная |
Включить: Отключить: |
Пример: автовекторизация скалярных плаваний
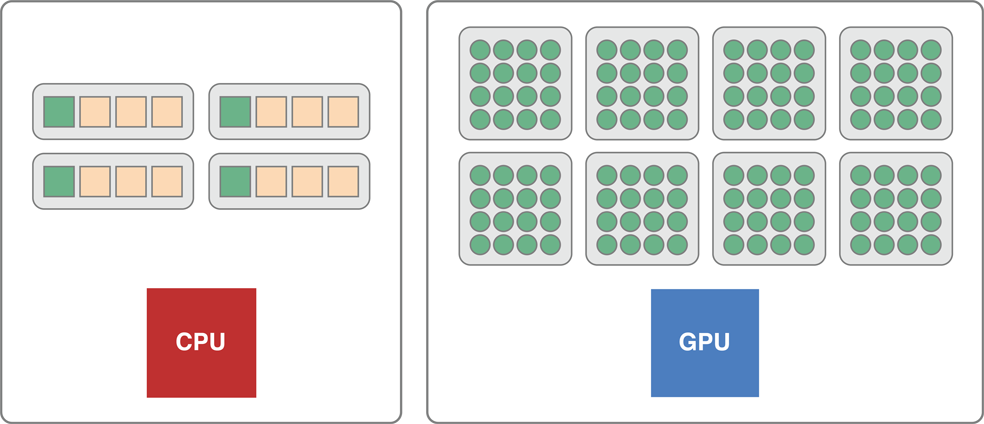
OpenCL рассматривает устройства как наличие, много вычисляют ядра и в них много элементов обработки. Когда скалярный код работает на CPU, он работает на каждом ядре, но не использует в своих интересах весь векторный модуль.
Например, на SSE4 CPU, скаляр кодирует выполнения в одном маршруте векторного модуля, когда это могло работать в четырех маршрутах. Монитор сообщил бы, что CPU абсолютно занят, потому что все ядра работают, но CPU фактически только использует четверть его векторной ширины.
Перечисление 13-1 является примером ядра, принимающего простые плавания:
Перечисление 13-1 , Передающее единственные плавания в ядро
kernel void add_arrays(global float* a, global float* b, global float* c) |
{ |
size_t i = get_global_id(0); |
c[i] = a[i] + b[i]; |
} |
При передаче простых плаваний в ядро ядро делает скалярное дополнение; работа на одном элементе данных за один раз. Как проиллюстрировано на рисунке 13-1 при передаче скалярного плавания GPU GPU становится полностью занятым обработкой данных. При передаче этого того же плавания CPU только одна четверть векторной ширины элемента обработки в каждом ядре используется.
Вы могли вместо этого передать float4* параметры к ядру, делающему дополнение векторным дополнением. Вычисление теперь специализировано для CPU. Это извлекло бы как можно больше работы от CPU, но оставило бы GPU неактивным.
Без автовекторизатора необходимо было бы записать многократные специфичные для устройства, нескалярные ядра, один для CPU и один для GPU.