Создание и управление буферными объектами в OpenCL
Интерфейс программирования OpenCL обеспечивает буферные объекты для представления универсальных данных в Ваших программах OpenCL. Вместо того, чтобы иметь необходимость преобразовать Ваши данные в домен определенного типа аппаратных средств, OpenCL позволяет Вам передать свои данные как есть устройству OpenCL через буферные объекты и затем воздействовать на те данные, использующие те же функции языка, что Вы приучены к в C.
Поскольку передача данных является дорогостоящей, лучше минимизировать чтения и записи как можно больше. Путем упаковки всех данных узла в буферный объект, который может остаться на устройстве, Вы сокращаете трафик объема данных, необходимый для обработки данных.
Выделение памяти для буферного объекта в памяти устройства
Создать буферный объект в вызове памяти устройства:
void * gcl_malloc(size_t bytes, void *host_ptr, cl_malloc_flags flags)
gcl_malloc функция очень подобна языку C malloc функция. gcl_malloc функционируйте возвращает непрозрачный указатель на буфер памяти устройства.
Если недостаточно память существует на устройстве для удовлетворения запроса, эта функция возвраты NULL.
Параметр | Описание |
|---|---|
| Размер в байтах запроса выделения. |
| Указатель на буфер стороны узла, который будет использоваться для инициализации выделения памяти если |
| Битовое поле, состоящее из 0 или больше флагов памяти, обсужденных в Разделе 5.2.1 из спецификации OpenCL 1.1. Если Вы указываете некоторую комбинацию |
Преобразование Дескриптора К Объекту cl_mem Для Использования Со Стандартным OpenCL API
Если Вы будете собираться быть использованием стандартного вызова API OpenCL, то Вам будет нужен a cl_mem объект. Создать a cl_mem объект, вызовите gcl_malloc функция для выделения памяти затем вызовите gcl_create_buffer_from_ptr функционируйте для преобразования дескриптора gcl_malloc возвраты для использования со стандартным OpenCL API. Вызовите:
cl_mem gcl_create_buffer_from_ptr(void *ptr)
Эта функция требуется только в случаях, где Вы будете использовать стандартный OpenCL API рядом gcl_ точки входа. Это возвращает a cl_mem объект, подходящий для использования со стандартным OpenCL API.
Это принимает a ptr параметр — указатель, создаваемый gcl_malloc функционируйте и возвращает соответствие cl_mem объект, подходящий для использования со стандартным OpenCL API.
Код будет выглядеть примерно так:
void* device_ptr = gcl_malloc(…); |
cl_mem device_mem = gcl_create_buffer_from_ptr(device_ptr); |
// Do stuff with device_ptr and device_mem. |
clReleaseMemObject(device_mem); |
gcl_free(device_ptr); |
Параметр | Описание |
|---|---|
| Указатель, возвращенный |
Доступ к глобальной памяти устройства
Получить доступ к глобальной памяти устройства, представленной данной подсказкой, создававшейся путем вызова gcl_malloc функция, вызовите:
void *gcl_map_ptr(void *ptr, cl_map_flags map_flags, size_t cb); |
gcl_map_ptr функция обеспечивает функциональность, подобную тому из стандарта OpenCL clEnqueueMapBuffer функция. Это возвращает доступный для узла указатель на память, представленную указателем памяти устройства, подходящим для чтения и записи. Можно использовать это в качестве альтернативы различному gcl_ скопируйте функции для доступа к глобальной памяти устройства, представленной данной подсказкой, создававшейся вызовом к gcl_malloc функция.
Параметр | Описание |
|---|---|
| Указатель в память устройства, которая должна быть отображена. Этот указатель создается |
| Указание битового поля |
| Число байтов буфера для отображения. (cb обозначает 'количество в байтах'). |
Копирование буферных объектов
Когда Вы выделяете память устройства с помощью gcl_malloc функция, Вы не должны создавать его на специфичной для устройства очереди отгрузки. Но когда время настает для фактического использования памяти, или для выполнения ядра или для копии некоторого вида, OpenCL должен знать, какое устройство Вы намереваетесь использовать.
Копирование данных от устройства или памяти хоста для хостинга или память устройства
Для копирования данных или с устройства или с памяти хоста для или хостинга или память устройства вызовите:
void gcl_memcpy(void *dst, const void *src, size_t size); |
Параметр | Описание |
|---|---|
| Указатель, указывающий на память, в которую будут скопированы байты. Это может или быть регулярный указатель узла, или это может быть указатель памяти устройства, создаваемый |
| Указатель на память, которая должна быть скопирована. Как с |
| Объем памяти в байтах для копирования с |
| |
Выполнение обобщенной копии от буфера к буферу
Для выполнения обобщенной копии от буфера к буферу, размещающей случай, где буферные данные концептуально многомерны вызовите:
void gcl_memcpy_rect( |
void *dst, |
const void *src,
const size_t dst_origin[3],
const size_t src_origin[3],
const size_t region[3],
size_t dst_row_pitch,
size_t dst_slice_pitch,
size_t src_row_pitch,
size_t src_slice_pitch); |
Эта функция обеспечивает функциональность, подобную тому из стандарта OpenCL clEnqueueCopyBufferRect функция; это копирует один - два - или трехмерная прямоугольная область от src указатель на dst указатель, с помощью соответствующих параметров источника для определения точек, в которых можно читать и записать. Как показано на рисунке 9-1, region параметр указывает и размер и форму области, которая будет скопирована.
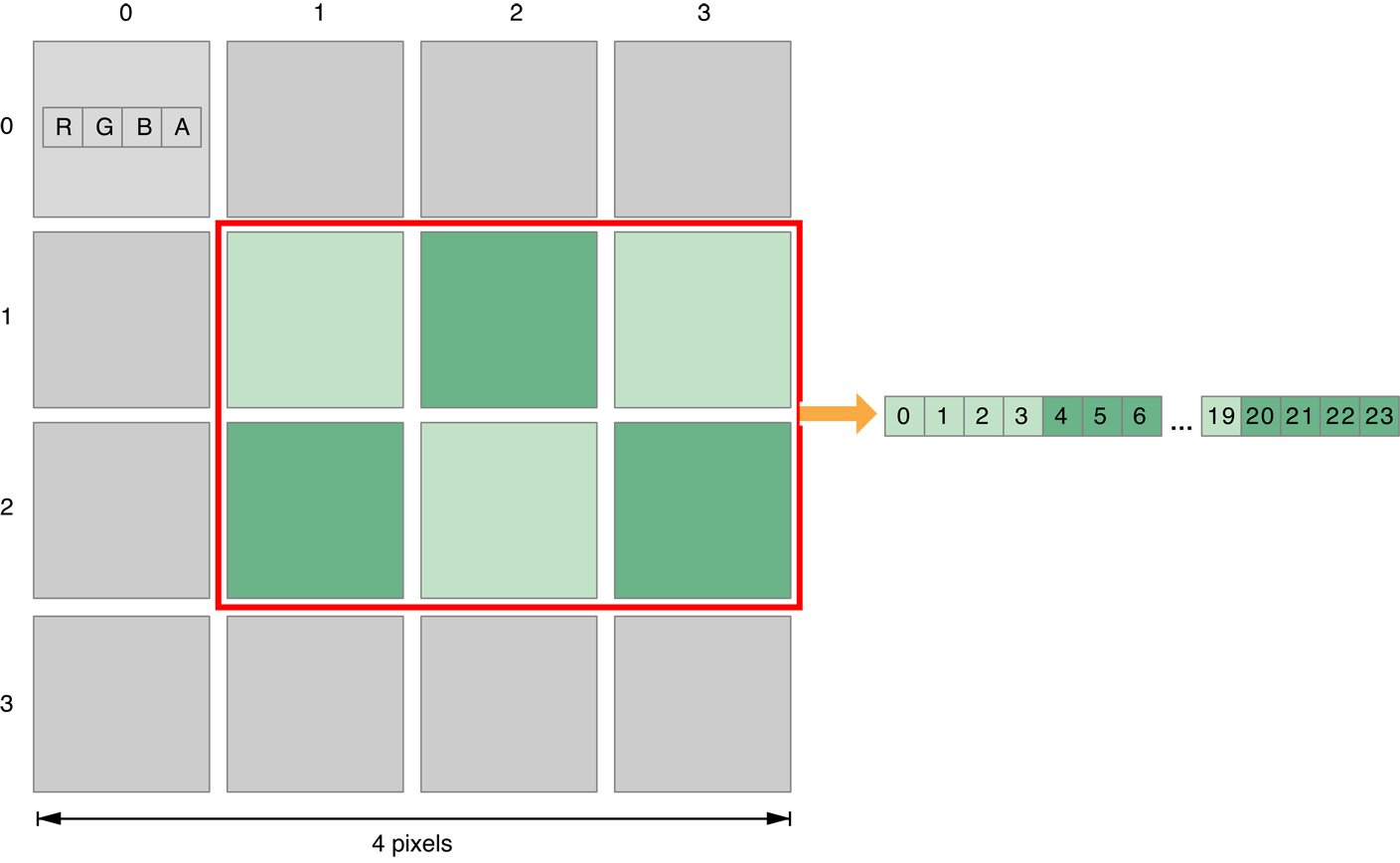
Так как это - буфер для буферизации копии, все параметры находятся в байтах.
Как со стандартом OpenCL clEnqueueCopyBufferRect функция, копирование начинается при исходном смещении (src_origin) и целевое смещение (dst_origin). Каждый байт ширины области копируется от исходного смещения до целевого смещения. После того, как каждая ширина была скопирована, источник и целевые смещения постепенно увеличиваются их соответствующим источником и целевыми шагами строки.
После того, как каждый двумерный прямоугольник копируется, источник и целевые смещения постепенно увеличиваются источником (src_slice_pitch) и место назначения (dst_slice_pitch) часть делает подачу соответственно.
Параметр | Описание |
|---|---|
| Указатель на память, в которую будут скопированы байты. Это может быть или регулярный указатель узла или указатель памяти устройства, создаваемый |
| Указатель на память, которая должна быть скопирована. Как с |
| Смещение, в байтах, который указывает, где в целевой буферной записи должен запуститься. Это вычисляется как:
|
| Смещение, в байтах, который указывает, где начать читать в исходном буфере. Это вычисляется как:
|
| Два - или трехмерная область для копирования. |
| Длина каждой строки в байтах, которые будут использоваться для области памяти, связалась с |
| После того, как каждый двумерный прямоугольник копируется, источник и целевые смещения постепенно увеличиваются источником ( |
| Длина каждой строки в байтах, которые будут использоваться для области памяти, связалась с |
| После того, как каждый двумерный прямоугольник копируется, источник и целевые смещения постепенно увеличиваются источником ( |
Выпуск буферных объектов
Для предотвращения утечек памяти свободный буфер возражает, когда они больше не необходимы. Вызовите gcl_free функционируйте к объектам свободного буфера создаваемое использование gcl_malloc функция.
void gcl_free(void *ptr); |
Параметр | Описание |
|---|---|
| Дескриптор буферного объекта, который будет выпущен. |
Пример: выделение, Используя, и выпуск буферных объектов
В Перечислении 9-1 узел создает один входной буфер и один буфер вывода, инициализирует входной буфер, вызывает ядро (см. Перечисление 9-2) для обработки на квадрат каждому значению во входном буфере, затем проверяет результаты.
Демонстрационная функция узла перечисления 9-1 создает буферы, тогда вызывает функцию ядра
#include <stdio.h> |
#include <stdlib.h> |
#include <OpenCL/opencl.h> |
// Include the automatically-generated header which provides the |
// kernel block declaration. |
#include "kernels.cl.h" |
#define COUNT 2048 |
static void display_device(cl_device_id device) |
{ |
char name_buf[128]; |
char vendor_buf[128]; |
clGetDeviceInfo( |
device, CL_DEVICE_NAME, sizeof(char)*128, name_buf, NULL); |
clGetDeviceInfo( |
device, CL_DEVICE_VENDOR, sizeof(char)*128, vendor_buf, NULL); |
fprintf(stdout, "Using OpenCL device: %s %s\n", vendor_buf, name_buf); |
} |
static void buffer_test(const dispatch_queue_t dq) |
{ |
unsigned int i; |
// We'll use a semaphore to synchronize the host and OpenCL device. |
dispatch_semaphore_t dsema = dispatch_semaphore_create(0); |
// Create some input data on the _host_ ... |
cl_float* host_input = (float*)malloc(sizeof(cl_float) * COUNT); |
// ... and fill it with some initial data. |
for (i=0; i<COUNT; i++) |
host_input[i] = (cl_float)i; |
// Let's use OpenCL to square this array of floats. |
// First, allocate some memory on our OpenCL device to hold the input. |
// We *could* write the output to the same buffer in this case, |
// but let's use a separate buffer. |
// Memory allocation 1: Create a buffer big enough to hold the input. |
// Notice that we use the flag 'CL_MEM_COPY_HOST_PTR' and pass the |
// host-side input data. This instructs OpenCL to initialize the |
// device-side memory region with the supplied host data. |
void* device_input = |
gcl_malloc(sizeof(cl_float)*COUNT, host_input, |
CL_MEM_COPY_HOST_PTR); |
// Memory allocation 2: Create a buffer to store the results |
// of our kernel computation. |
void* device_results = gcl_malloc(sizeof(cl_float)*COUNT, NULL, 0); |
// That's it -- we're ready to send the work to OpenCL. |
// Note that this will execute asynchronously with respect |
// to the host application. |
dispatch_async(dq, ^{ |
cl_ndrange range = { |
1, // We're using a 1-dimensional execution. |
{0}, // Start at the beginning of the range. |
{COUNT}, // Execute 'COUNT' work items. |
{0} // Let OpenCL decide how to divide work items |
// into workgroups. |
}; |
square_kernel( |
&range, (cl_float*) device_input, |
(cl_float*) device_results ); |
// The computation is done at this point, |
// but the results are still "on" the device. |
// If we want to examine the results on the host, |
// we need to copy them back to the host's memory space. |
// Let's reuse the host-side input buffer. |
gcl_memcpy(host_input, device_results, COUNT * sizeof(cl_float)); |
// Okay -- signal the dispatch semaphore so the host knows |
// it can continue. |
dispatch_semaphore_signal(dsema); |
}); |
// Here the host could do other, unrelated work while the OpenCL |
// device works on the kernel-based computation... |
// But now we wait for OpenCL to finish up. |
dispatch_semaphore_wait(dsema, DISPATCH_TIME_FOREVER); |
// Test our results: |
int results_ok = 1; |
for (i=0; i<COUNT; i++) |
{ |
cl_float truth = (cl_float)i * (cl_float)i; |
if (host_input[i] != truth) { |
fprintf(stdout, |
"Incorrect result @ index %d: Saw %1.4f, expected %1.4f\n\n", |
i, host_input[i], truth); |
results_ok = 0; |
break; |
} |
} |
if (results_ok) |
fprintf(stdout, "Buffer results OK!\n"); |
// Clean up device-side memory allocations: |
gcl_free(device_input); |
// Clean up host-side memory allocations: |
free(host_input); |
} |
int main (int argc, const char * argv[]) |
{ |
// Grab a CPU-based dispatch queue. |
dispatch_queue_t dq = gcl_create_dispatch_queue(CL_DEVICE_TYPE_CPU, NULL); |
if (!dq) |
{ |
fprintf(stdout, "Unable to create a CPU-based dispatch queue.\n"); |
exit(1); |
} |
// Display the OpenCL device associated with this dispatch queue. |
display_device(gcl_get_device_id_with_dispatch_queue(dq)); |
buffer_test(dq); |
fprintf(stdout, "\nDone.\n\n"); |
dispatch_release(dq); |
} |
Демонстрационное ядро перечисления 9-2 придает входному массиву квадратную форму
// A very simple kernel which squares an input array. The results are |
// stored in another buffer, but could just as well be stored in the |
// 'input' array -- that's a developer choice. |
// Note that input and results are declared as 'global', indicating |
// that they point to allocations in the device's global memory. |
kernel void square( global float* input, global float* results ) |
{ |
// We've launched our kernel (in the host-side code) such that each |
// work item squares one incoming float. The item each work item |
// should process corresponds to its global work item id. |
size_t index = get_global_id(0); |
float val = input[index]; |
results[index] = val * val; |
} |