Совместное использование данных между OpenCL и OpenGL
OpenGL (Открытая библиотека графических функций) является API для записи приложений, производящих два - и трехмерная компьютерная графика. OpenCL и OpenGL разработаны для взаимодействия. В частности OpenCL и OpenGL могут совместно использовать данные, сокращающие наверху. Например, объекты OpenGL и объекты памяти OpenCL, создаваемые из объектов OpenGL, могут получить доступ к той же памяти. Кроме того, GLSL (Язык Штриховки OpenGL) программы построения теней и ядра OpenCL может получить доступ к совместно используемым данным.
Для проверки OpenCL и OpenGL сотрудничают гладко:
Установите свою программу, чтобы сделать все ее вычисление и представляющий на GPU.
Это улучшит производительность, потому что Вы избежите иметь необходимость передать данные между узлом и GPU.
Выделите память, чтобы гарантировать, что данные совместно используются эффективно.
Эта глава показывает, как OpenCL API может использоваться для создания объектов памяти OpenCL из буферных объектов вершины OpenGL (VBOs), объектов текстуры и объектов renderbuffer. Это также показывает, как создать буферные объекты OpenCL из буферных объектов OpenGL и как создать объект изображения OpenCL из текстуры OpenGL или объекта renderbuffer.
Sharegroups
Чтобы позволить приложению OpenCL получать доступ к объекту OpenGL, используйте контекст OpenCL, создающийся из OpenGL sharegroup (CGLShareGroupObj) объект. OpenCL возражает, что Вы создаете в этом контексте, сошлется на эти объекты OpenGL. Когда контекст OpenCL подключен к OpenGL sharegroup объект таким образом, и OpenCL и контексты OpenGL могут сослаться на те же объекты.
Рисунок 10-1 иллюстрирует типичный сценарий, в котором OpenCL генерирует геометрию на GPU, и OpenGL представляет совместно используемую геометрию, также на GPU. Они могут видеть то, на что они смотрят как различные объекты - в этом случае, OpenGL рассматривает данные как VBO, и OpenCL рассматривает его как a cl_mem. Результат состоит в том, что и OpenCL и контексты OpenGL заканчивают тем, что сослались на тот же sharegroup (CGLShareGroupObj) объект, посмотрите те же устройства и получите доступ к этой совместно используемой геометрии.
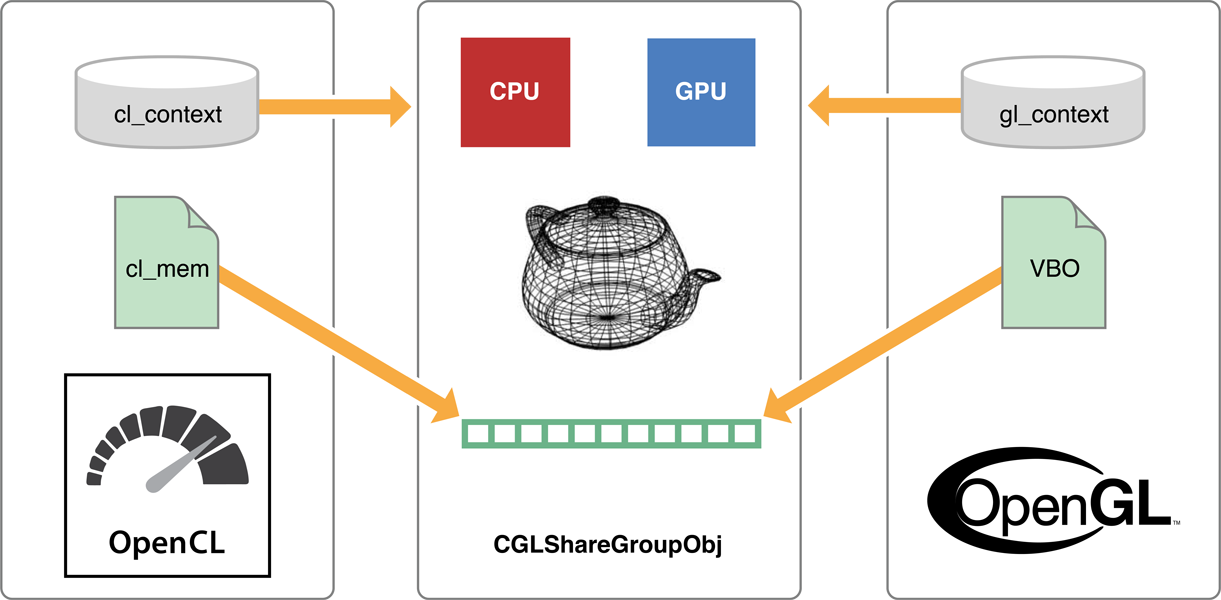
Взаимодействовать между OpenCL и OpenGL:
-
Установите sharegroup:
CGLContextObj cgl_context = CGLGetCurrentContext();
CGLShareGroupObj sharegroup = CGLGetShareGroup(cgl_context);
gcl_gl_set_sharegroup(sharegroup);
...
После того, как sharegroup был установлен, можно создать объекты памяти OpenCL из существующих объектов OpenGL:
Для создания буферного объекта OpenCL из буферного объекта OpenGL вызовите:
void * gcl_gl_create_ptr_from_buffer(GLuint bufobj);
Для создания объекта изображения OpenCL из объекта текстуры OpenGL вызовите:
cl_image gcl_gl_create_image_from_texture(
GLenum texture_target,
GLint mip_level,
GLuint texture);
Для создания объекта двухмерного изображения OpenCL из буферного объекта рендеринга OpenGL вызовите:
cl_image gcl_gl_create_image_from_renderbuffer(GLuint render_buffer);
Синхронизация Доступа К Совместно используемому OpenCL / Объекты OpenGL
Для обеспечения целостности данных приложение должно синхронизировать доступ к объектам, совместно использованным OpenCL и OpenGL. Отказ обеспечить такую синхронизацию может привести к условиям состязания или другому неопределенному поведению включая немобильность между реализациями. Для получения информации о синхронизирующихся событиях OpenCL и OpenGL и пределах, посмотрите Управление OpenCL / Взаимодействие OpenGL С GCD.
Пример: OpenCL и буферы совместного использования OpenGL
Этот пример кода выбирается от OpenCL Процедурный Геометрический Пример Смещения с Интеграцией GCD. Это показывает, как OpenCL может связать с существующими буферами OpenGL во избежание копирования данных назад от вычислить устройства, когда это должно использовать результаты вычисления для рендеринга. В этом примере OpenCL вычисляет ядро, перемещает вершины управляемого OpenGL буферного объекта вершины (VBO). Вычислить ядро вычисляет несколько октав процедурного шума для продвижения получающихся позиций вершины за пределы и вычисляет новые нормальные направления с помощью конечных разностей. Вершины тогда представляются OpenGL.
Создавать это приложение:
Включайте заголовочный файл, сгенерированный XCode. Этот заголовочный файл содержит блочное объявление ядра.
#include "displacement_kernel.cl.h"Объявите очередь отгрузки и семафор отгрузки, используемый для синхронизации между OpenCL и OpenGL. Для получения дополнительной информации о семафорах отгрузки, посмотрите Синхронизацию Узла С OpenCL Используя Семафор Отгрузки.
static dispatch_queue_t queue;
static dispatch_semaphore_t cl_gl_semaphore;
Объявите объекты памяти, которые будут содержать данные ввода и вывода.
static void *InputVertexBuffer;
static void *OutputVertexBuffer;
static void *OutputNormalBuffer;
Установите sharegroup, создайте очередь отгрузки и семафор отгрузки, и получите вычислить устройство.
static int setup_compute_devices(int gpu)
{int err;
size_t returned_size;
ComputeDeviceType =
gpu ? CL_DEVICE_TYPE_GPU : CL_DEVICE_TYPE_CPU;
printf(SEPARATOR);
printf("Using active OpenGL context...\n");// Set the sharegroup.
CGLContextObj kCGLContext =
CGLGetCurrentContext();
CGLShareGroupObj kCGLShareGroup =
CGLGetShareGroup(kCGLContext);
gcl_gl_set_sharegroup(kCGLShareGroup);
// Create a dispatch queue.
queue = gcl_create_dispatch_queue(
ComputeDeviceType, NULL);
if (!queue)
{printf("Error: Failed to create a dispatch queue!\n");return EXIT_FAILURE;
}
// Create a dispatch semaphore.
cl_gl_semaphore = dispatch_semaphore_create(0);
if (!cl_gl_semaphore)
{printf("Error:Failed to create a dispatch semaphore!\n");
return EXIT_FAILURE;
}
// Get the device ID.
ComputeDeviceId =
gcl_get_device_id_with_dispatch_queue(queue);
// Report the device vendor and device name.
cl_char vendor_name[1024] = {0};cl_char device_name[1024] = {0};err = clGetDeviceInfo(
ComputeDeviceId, CL_DEVICE_VENDOR,
sizeof(vendor_name), vendor_name,
&returned_size);
err|= clGetDeviceInfo(
ComputeDeviceId, CL_DEVICE_NAME,
sizeof(device_name), device_name,
&returned_size);
if (err != CL_SUCCESS)
{printf(
"Error: Failed to retrieve device info!\n");
return EXIT_FAILURE;
}
printf(SEPARATOR);
printf(
"Connecting to %s %s...\n",
vendor_name, device_name);
return CL_SUCCESS;
}
Создайте объекты памяти, которые будут содержать данные ввода и вывода и инициализировать входной объект памяти с входными данными.
Этот пример создает новый объект памяти,
InputVertexBuffer, использованиеgcl_mallocфункция. Это тогда используетgcl_gl_create_ptr_from_bufferфункция для создания объектов OpenCL (OutputVertexBufferиOutputNormalBuffer) от существующего OpenGL VBOs (VertexBufferIdиNormalBufferId).InputVertexBufferобъект памяти инициализируется с входными данными, хранившими вVertexBuffer, использованиеgcl_memcpyфункция.static int setup_compute_memory()
{size_t bytes =
sizeof(float) * VertexComponents * VertexElements;
printf(SEPARATOR);
printf("Allocating buffers on compute device...\n");InputVertexBuffer = gcl_malloc(bytes, NULL, 0);
if (!InputVertexBuffer)
{printf("Failed to create InputVertexBuffer!\n");return EXIT_FAILURE;
}
OutputVertexBuffer =
gcl_gl_create_ptr_from_buffer(VertexBufferId);
if (!OutputVertexBuffer)
{printf("Failed to create OutputVertexBuffer!\n");return EXIT_FAILURE;
}
OutputNormalBuffer =
gcl_gl_create_ptr_from_buffer(NormalBufferId);
if (!OutputNormalBuffer)
{printf("Failed to create OutputNormalBuffer!\n");return EXIT_FAILURE;
}
dispatch_async(queue,
^{gcl_memcpy(InputVertexBuffer,
VertexBuffer, VertexBytes);});
return CL_SUCCESS;
}
Создайте вычислить ядро из блока ядра, сгенерированного XCode.
static int setup_compute_kernels(void)
{int err = 0;
ComputeKernel =
gcl_create_kernel_from_block(displace_kernel);
// Get the maximum work group size for executing
// the kernel on the device.
size_t max = 1;
err = clGetKernelWorkGroupInfo(
ComputeKernel, ComputeDeviceId,
CL_KERNEL_WORK_GROUP_SIZE, sizeof(size_t),
&max, NULL);
if (err != CL_SUCCESS)
{printf("Error:Failed to retrieve kernel work group
info! %d\n", err);
return EXIT_FAILURE;
}
MaxWorkGroupSize = max;
printf("Maximum Workgroup Size '%d'\n",MaxWorkGroupSize);
return CL_SUCCESS;
}
Используйте
cl_ndrangeструктура для указания параллели данных передвигается, по которому можно выполнить ядро. Диспетчеризируйте блок ядра асинхронно с помощьюdispatch_asyncфункция. После того, как Вы будете диспетчеризировать ядро, будете сигнализировать семафор отгрузки, чтобы указать, что OpenGL может теперь получить доступ к совместно используемым ресурсам.static int recompute(void)
{size_t global[2];
size_t local[2];
cl_ndrange ndrange;
uint uiSplitCount = ceilf(sqrtf(VertexElements));
uint uiActive = (MaxWorkGroupSize / GroupSize);
uiActive = uiActive < 1 ? 1 : uiActive;
uint uiQueued = MaxWorkGroupSize / uiActive;
local[0] = uiActive;
local[1] = uiQueued;
global[0] = divide_up(uiSplitCount, uiActive) * uiActive;
global[1] = divide_up(uiSplitCount, uiQueued) * uiQueued;
ndrange.work_dim = 2;
ndrange.global_work_offset[0] = 0;
ndrange.global_work_offset[1] = 0;
ndrange.global_work_size[0] = global[0];
ndrange.global_work_size[1] = global[1];
ndrange.local_work_size[0] = local[0];
ndrange.local_work_size[1] = local[1];
dispatch_async(queue,
^{displace_kernel(&ndrange,
InputVertexBuffer,
OutputNormalBuffer,
OutputVertexBuffer,
ActualDimX, ActualDimY,
Frequency, Amplitude, Phase,
Lacunarity, Increment, Octaves,
Roughness, VertexElements);
dispatch_semaphore_signal(
cl_gl_semaphore);
});
return 0;
}
Освободите объекты памяти OpenCL, выпустите вычислить ядро, очередь отгрузки и семафор.
static void shutdown_opencl(void)
{gcl_free(InputVertexBuffer);
gcl_free(OutputVertexBuffer);
gcl_free(OutputNormalBuffer);
clReleaseKernel(ComputeKernel);
if(VertexBuffer)
free(VertexBuffer);
if(NormalBuffer)
free(NormalBuffer);
dispatch_release(cl_gl_semaphore);
dispatch_release(queue);
}