Управление OpenCL / Взаимодействие OpenGL С GCD
Приложение, работающее на узле (CPU), может направить работу или данные (возможно в разрозненных блоках) к устройству с помощью стандартного OpenCL и OpenGL APIs и OS X v10.7 расширения. В то время как устройство выполняет работу, это было присвоено, узел может продолжать работать асинхронно. В конечном счете узлу нужны результаты, еще не сгенерированные устройством, выполняющим работу. В той точке узел ожидает устройства, чтобы уведомить его, что была завершена порученная работа.
OpenCL и OpenGL могут также совместно использовать работу и данные. Как правило, используйте OpenCL, чтобы генерировать или изменить буферные данные, тогда представляющиеся OpenGL. Или, Вы могли бы использовать OpenGL, чтобы создать изображение и затем постобработать его использование OpenCL. В любом случае удостоверьтесь, что Вы синхронизируетесь так, чтобы обработка произошла в надлежащем порядке.
Можно всегда выполнять последовательные трудно кодированные вызовы к стандартному OpenCL и функциям OpenGL для получения тонкозернистой синхронизации при работе над совместно используемыми данными. Можно всегда просто смешивать вызовы к функциям OpenCL и OpenGL. (См. OpenGL и спецификации OpenGL для получения дополнительной информации.)
Эта глава показывает, как синхронизировать обработку программно с помощью очередей GCD. Можно использовать GCD для синхронизации:
-
Узел с OpenCL. (См. Используя GCD Для Синхронизации Узла С OpenCL.)
-
Узел с OpenCL с помощью семафора отгрузки. (См. Синхронизацию Узла С OpenCL Используя Семафор Отгрузки.)
-
Многократные очереди OpenCL. (См. синхронизирующиеся многократные очереди.)
Используя GCD для синхронизации узла с OpenCL
В Перечислении 11-1 узел ставит в очередь данные в двух очередях к GCD. В то время как узел продолжает выполнять свою собственную работу, в этом примере обрабатываются данные с очередями. Когда узлу нужны результаты, он ожидает обеих очередей для завершения их работы.
Перечисление 11-1 , Синхронизирующее узел с обработкой OpenCL
// Create a workgroup so host can wait for results from more than one kernel. |
dispatch_group_t group = dispatch_group_create(); |
// Enqueue some of the data to the add_arrays_kernel on q0. |
dispatch_group_async(group, q0, |
^{ // Because the call is asynchronous, |
// the host will not wait for the results. |
cl_ndrange ndrange = { 1, {0}, {N/2}, {0} }; |
add_arrays_kernel(&ndrange, a, b, c); |
}); |
// Enqueue some of the data to the add_arrays_kernel on q1. |
dispatch_group_async(group, q1, |
^{ // Because the call is asynchronous, |
// the host will not wait for the results. |
cl_ndrange ndrange = { 1, {N/2}, {N/2}, {0} }; |
add_arrays_kernel(&ndrange, a, b, c); |
}); |
// Perform more work independent of the work being done by the kernels. |
// ... |
// At this point, the host needs the results before it can proceed. |
// So it waits for the entire workgroup (on both queues) to complete its work. |
dispatch_group_wait(group, DISPATCH_TIME_FOREVER); |
Синхронизация узла с OpenCL Используя семафор отгрузки
Перечисление 11-2 иллюстрирует, как можно использовать OpenCL и OpenGL вместе в приложении. В этом примере два буферных объекта вершины (VBOs), создаваемый в OpenGL (не показанный), представляют позиции некоторых объектов на моделировании N-организации. Объекты памяти OpenCL, создаваемые из этих VBOs (строка [2]), позволяют ядру OpenCL воздействовать непосредственно на память устройства, содержащую эти данные. Ядро обновляет эти позиции согласно некоторому алгоритму, выраженному как работа на объект во включенном ядре. Объекты тогда представляются в получающемся VBO использованием OpenGL (прокомментировал, но не показанный, в [4]).
OpenCL обновляет позиции на очереди отгрузки, работающей асинхронно относительно потока, делающего рендеринг OpenGL. Чтобы гарантировать, что объекты не представляются, перед, ядро закончило обновлять позиции, приложение использует механизм семафора отгрузки.
dispatch_semaphore_t (строка [1]), создается, прежде чем основной цикл начинается. В блоке, представленном очереди отгрузки, создаваемой в OpenCL, сразу после вызова ядра, сообщен семафор. Между тем «основной» поток выполнения продолжался вперед - возможно, выполняющий больше работы - в конечном счете достижение вызова к dispatch_semaphore_wait(...) (строка [3]). Основной поток останавливается в этой точке и ожидает, пока сигнал постъядра не «зеркально отражает» семафор. Как только это происходит, код может продолжаться к части рендеринга OpenGL кода, безопасного в знании, что обновление позиции для этого раунда завершено.
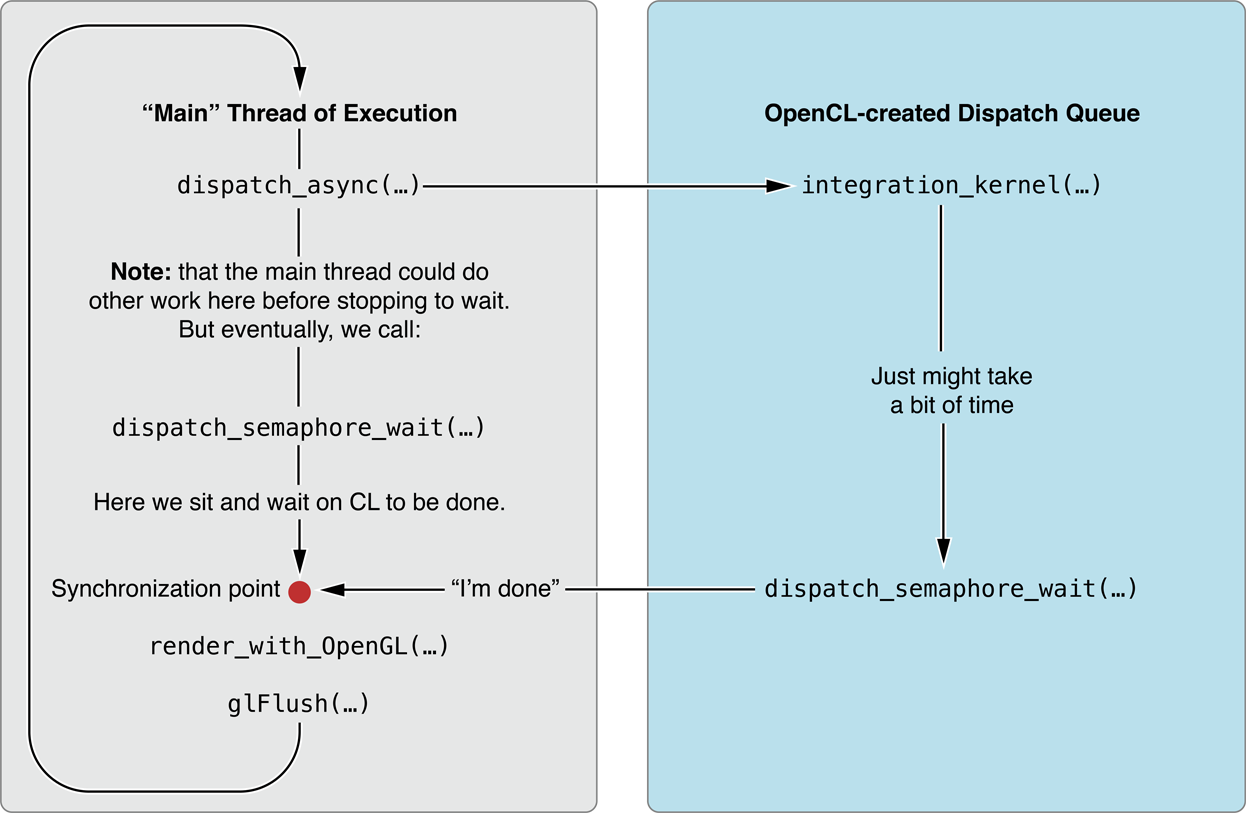
Перечисление 11-2 , Синхронизирующееся узел с OpenCL с помощью семафора отгрузки
// In this case, the kernel code updates the position of the vertex. |
// ... |
// The host code: |
// Create the dispatch semaphore. [1] |
dispatch_queue_t queue; |
dispatch_semaphore_t cl_gl_semaphore; |
void *pos_gpu[2], *vel_gpu[2]; |
GLuint vbo[2]; |
float *host_pos_data, *host_vel_data; |
int num_bodies; |
int curr_read_index, curr_write_index; |
// The extern OpenCL kernel declarations. |
extern void (^integrateNBodySystem_kernel)(const cl_ndrange *ndrange, |
float4 *newPos, float4 *newVel, |
float4 *oldPos, float4 *oldVel, |
float deltaTime, float damping, |
float softening, int numBodies, |
size_t sharedPos); |
void initialize_cl() |
{ |
gcl_gl_set_sharegroup(CGLGetShareGroup(CGLGetCurrentContext()); |
// Create a CL dispatch queue. |
queue = gcl_create_dispatch_queue(CL_DEVICE_TYPE_GPU, NULL); |
// Create a dispatch semaphore to support CL/GL data sharing. |
cl_gl_semaphore = dispatch_semaphore_create(0); |
// Create CL objects from GL VBOs that have already been created. [2] |
pos_gpu[0] = gcl_gl_create_ptr_from_buffer(vbo[0]); |
pos_gpu[1] = gcl_gl_create_ptr_from_buffer(vbo[1]); |
vel_gpu[0] = gcl_malloc(sizeof(float4)*num_bodies, NULL, 0); |
vel_gpu[1] = gcl_malloc(sizeof(float4)*num_bodies, NULL, 0); |
// Allocate and generate position and velocity data |
// in host_pos_data and host_vel_data. |
… |
// Initialize CL buffers with host position and velocity data. |
dispatch_async(queue, |
^{gcl_memcpy(pos_gpu[curr_read_index], host_pos_data, |
sizeof(float4)*num_bodies); |
gcl_memcpy(vel_gpu[curr_read_index], host_vel_data, |
sizeof(float4)*num_bodies);}); |
} |
void execute_cl_gl_main_loop() |
{ |
// Queue CL kernel to dispatch queue. |
dispatch_async(queue, |
^{ |
ndrange_t ndrange = { 1, {0}, {num_bodies} } ; |
// Get local workgroup size that kernel can use for |
// device associated with queue. |
gcl_get_kernel_block_workgroup_info( |
integrateNBodySystem_kernel, |
CL_KERNEL_WORK_GROUP_SIZE, |
sizeof(size_t), &nrange.local_work_size[0], |
NULL); |
// Queue CL kernel to dispatch queue. |
integrateNBodySystem_kernel(&ndrange, |
pos_gpu[curr_write_index], |
vel_gpu[curr_write_index], |
pos_gpu[curr_read_index], |
vel_gpu[curr_read_index], |
damping, softening, num_bodies, |
sizeof(float4)*ndrange.local_work_size[0]); |
// Signal the dispatch semaphore to indicate that |
// GL can now use resources. |
dispatch_semaphore_signal(cl_gl_semaphore);}); |
// Do work not related to resources being used by CL in dispatch block. |
// Need to use VBOs that are being used by CL so wait for the CL commands |
// in dispatch queue to be issued to the GPU’s command-buffer. [3] |
dispatch_semaphore_wait(cl_gl_semaphore, DISPATCH_TIME_FOREVER); |
// Bind VBO that has been modified by CL kernel. |
glBindBuffer(GL_ARRAY_BUFFER, pos_gpu[curr_write_index]); |
// Now render with GL. [4] |
// Flush GL commands. |
glFlush(); |
} |
void release_cl() |
{ |
gcl_free(pos_gpu[0]); |
gcl_free(pos_gpu[1]); |
gcl_free(vel_gpu[0]); |
gcl_free(vel_gpu[1]); |
dispatch_release(cl_gl_semaphore); |
dispatch_release(queue); |
} |
Синхронизация многократных очередей
В Перечислении 11-3 узел ставит в очередь данные в двух очередях к GCD. Вторая очередь ожидает первой очереди, которая завершит ее обработку прежде, чем выполнить ее работу. Хост-приложение не ожидает завершения ни одной очереди.
Перечисление 11-3 , Синхронизирующее многократные очереди
// Create the workgroup which will consist of just the work items |
// that must be completed first. |
dispatch_group_t group = dispatch_group_create(); |
dispatch_group_enter(group); |
// Start work on the workgroup. |
dispatch_async(q0, |
^{ |
cl_ndrange ndrange = { 1, {0}, {N/2}, {0} }; |
add_arrays_kernel(&ndrange, a, b, c); |
dispatch_group_leave(group); |
}); |
// Simultaneously enqueue data on q1, |
// but immediately wait until the workgroup on q0 completes. |
dispatch_async(q1, |
^{ |
// Wait for the work of the group to complete. |
dispatch_group_wait(group, DISPATCH_TIME_FOREVER); |
cl_ndrange ndrange = { 1, {N/2}, {N/2}, {0} }; |
add_arrays_kernel(&ndrange, a, b, c); |
}); |
// Host application does not wait. |