Поисковые основы
Разговор о технологии информационного поиска (IR), такой как Поисковый Набор требует некоторых условий и понятий, которые могут быть незнакомыми Вам. В этой главе Вы узнаете о них. По пути Вы узнаете, что поток операций в системе IR не очень отличается от процесса получения информации от Вашей местной библиотеки.
Если Вы понимаете такие условия как корпус, извлечение текста, инвертированный индекс, запрос, Поиск с использованием булевых операторов и ранжирование уместности, можно пропустить эту главу и начать с Поисковых Понятий Набора.
В этой главе описываются информационный поиск как трехступенчатый процесс:
Установление подходящего источника для поиска
Формулировка запроса
Вызов поиска и обеспечение результатов
Эта глава продвигается Вы через поисковый поток операций с помощью метафоры библиотеки, связывая его с универсальной компьютерной системой IR со случайным упоминанием о Поисковых подробных сведениях Набора.
Установление подходящего источника для поиска
У Вас есть информационная потребность. Но прежде чем можно задать вопрос, Вам нужны кто-то или что-то для выяснения. Т.е. необходимо установить то, кто или что Вы примете как полномочия для ответа. Таким образом, перед выяснением у вопроса, необходимо определить цель вопроса.
Такая цель может быть настолько же широкой как весь Интернет для простого Google использования поиска, или столь же определенная как локальный почтовый ящик в Почтовой программе пользователя. Используя метафору библиотеки здесь, Вы спросите библиотекаря, который будет поочередно консультироваться с некоторыми индексами журнала. Библиотекарь играет роль Вашего приложения. Специальные ссылочные навыки библиотекаря играют роль Поискового Набора. Индексы журнала играют роль Поисковых индексов Набора.
Выбор коллекции документов
Цель вопроса соответствует понятию информационного поиска коллекции документов, или более формально, корпус, как изображено на рисунке 1-1.
Если Вы полагаете, что статья журнала документ, то проблема журнала составляет корпус — это - набор одного или более документов. 12 проблемами, опубликованными через год, являются корпуса (“Этих корпусов, который имеет большинство статей?”), но рассмотренный как единственный, больший набор, они становятся единственным, большим корпусом (“В этом корпусе, включающем 12 проблем, какие статьи упоминают спортивные автомобили?”).
Точно так же, если Вы полагаете, что сообщение электронной почты документ, то каждый из почтовых ящиков в Почтовом приложении пользователя является корпусом. Ряд почтовых ящиков, когда Вы ищете в одном или другом индивидуально, является корпусами. При поиске ряда почтовых ящиков как единственное большое количество набор составляет единственный, больший корпус.
Так вообще говоря, информационный поиск является двумя процессами шага, запускающимися с указания корпуса и доходов к указанию запроса.
При вызове библиотекаря Вы выбрали библиотеку в качестве своего корпуса. Если Вы тогда спрашиваете, “Какая марка автомобиля имеет лучшее значение предмета, сдаваемого в счет оплаты нового?” библиотекарь мог бы сузить эффективный корпус путем просмотра статей в проблемах прошлого года журнала для потребителей и автомобильного журнала. В этом сценарии библиотекарь, действуя от Вашего имени, ожидает, что один или больше этих документов будет содержать хороший ответ — т.е. библиотекарь ожидает, что те проблемы составляют надлежащий корпус для поиска.
Построение индексов
Для возвращения к Вам в разумном количестве времени, конечно, библиотекарь не подошел бы к полкам журнала и считал бы каждую проблему, опубликованную за прошлый год, полный. Он использовал бы индексы. Компьютерные информационно-поисковые системы делают то же.
Индекс отображает существенную информацию в корпусе в формат, разработанный, чтобы позволить Вам быстро определить местоположение определенного содержания. Например, годовой индекс журнала включает ключевые термины от каждой статьи в каждой проблеме, опубликованной в том году.
Инвертированные индексы
Каждая запись в индексе журнала указывает на Вас на одну или более статей. Можно думать об индексе как о списке терминов с каждым сроком, сопровождаемым списком документов, в которых это появляется. Этот вид индекса, тот, о котором обычно думают люди, формально известен как инвертированный индекс. Термин «инвертированный» относится к расположению информации в индексе, предназначающемся для определения местоположения документов путем соответствия на условиях. Это «инвертируется» по сравнению с использованием документов непосредственно: если Вы забираете книгу, Вы «соответствуете» на документе и «определяете местоположение» всех условий в нем.
Рисунок 1-2 показывает инвертированный индекс схематично и изображает упрощенную версию того, как такой индекс мог бы представлять условия от ряда документов.
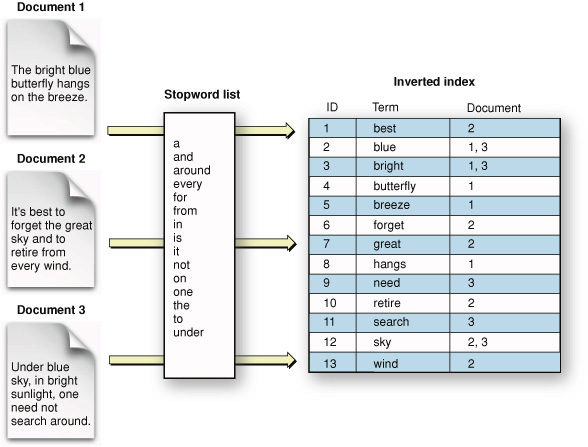
Это число включает что-то вызванное список стоп-слова, используемый для отфильтровывания указанных условий во время извлечения текста. (SStopwords и Минимальный срок Lengthtopwords описаны вскоре.)
Извлечение текста
Когда первое соответствие Библии создавалось, самым ранним известным использованием инвертированных индексов является 1 247 CE. Тогда процесс потребовал усилий нескольких сотен монахов. (Эта историческая информация прибывает из академического обзора анализа текста из университета Альберты, назвал то, Что Анализ текста?.)
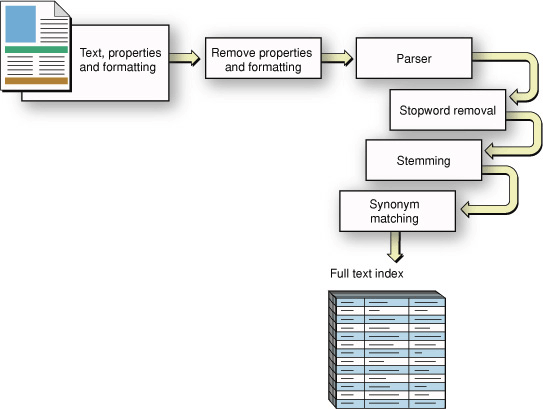
Информационно-поисковая система, вместо того, чтобы полагаться на многократных монахов, использует алгоритм извлечения текста для сбора урожая соответствующих условий из документа. Срок, становящийся записью в индексе, обычно является словом. Рисунок 1-3 иллюстрирует основные шаги в извлечении текста, начиная с отформатированного документа и приводящий к полнотекстовому индексу.
Стоп-слова и длина минимального срока
Извлечение текста влечет за собой компромисс между покрытием и уместностью. При индексации каждого срока в корпусе Вы имеете совершенное покрытие и не пропустите ничего, но Вы закончите с индексом, процент которого полезных записей является низким. Во многих случаях нет никакого преимущества к извлечению слов как, «и», или «это» и размещению их в индексе.
Индексирование систем, таких как та в Поисковом Наборе, позволило Вам указать список стоп-слов — условия, чтобы проигнорировать во время извлечения текста — и указать длину минимального срока. Условия в корпусе или короче, чем длина минимального срока или включенный в список стоп-слова пропускаются во время извлечения текста. Рисунок 1-4 показывает выборку из типичного списка стоп-слова.

Любое слово, пропущенное таким образом, не будет в индексе и так не будет доступно для поиска. Это иногда, что Вы хотите. Такие слова редко касаются значения или значения документа.
Но если Вы хотите поддерживать поиск точных фраз, исключая общие слова может быть проблематичным точно, потому что они распространены и часто появляются во фразах. Одна опция некоторое системное использование IR для решения этой дилеммы должно индексировать все, затем отфильтровать на стоп-словах и длине минимального срока во время запроса, если запрос не основан на фразе. Для больше на основанном на фразе поиске, посмотрите Фразовые поиски.
Списки стоп-слова являются, конечно, определенным языком и возможно даже зависящим от домена. Корпус химических описаний, вероятно, получил бы преимущества от различного списка стоп-слова, чем корпус детских рассказов будет. Если Вы планируете представить свое приложение на рынке различным культурным областям, или на широко расходящиеся рынки даже в одной области, помните это.
Синонимы и стемминг
Индексирующие системы также используют списки синонимов для повышения поискового качества. Например, если Вы задаете библиотекарю вопрос о значении предмета, сдаваемого в счет оплаты нового подержанной машины, он мог бы посмотреть в некоторых индексах журнала под «автомобилем»; но текст соответствующей статьи мог бы упомянуть только “пассажирский механизм” или «автомобиль». Если бы система индексации связала эти альтернативные условия как синонимы «автомобиля», то соответствующие статьи были бы также присоединены к индексному термину «автомобиль».
Обучение системы индексации о синонимах составляет предоставление его список, создание которого является выполняемым вручную процессом. Поисковый Набор поддерживает синонимы как так называемый «список заменителей» в словаре свойств анализа текста индекса. Для больше на этом, посмотрите kSKSubstitutions и SKIndexCreateWithURL в ссылке SearchKit.
Существует алгоритмический метод также для увеличения пользователей вероятности, найдет то, что они ищут. Этот метод вызывают, происходя или, иногда, отсечение суффиксов. Поисковый Набор не выполняет стемминг, но полезно знать об этом так, можно лучше понять поведение Поискового Набора в приложении. Можно хотеть обеспечить стемминг функциональности сами.
Большинство языков имеет тесно связанные слова, известные как морфологические или флективные варианты, на основе общей части, известной как основа или корневое слово. На английском языке основа имеет тенденцию прибывать в начале слов: «плавайте», «плавание», и доля «пловца», общая основа «плавает».
Система индексации, знающая, как произойти, преобразует каждую альтернативную словоформу, во время извлечения текста, к общему слову основы. Связанная система запросов также преобразует слова в строке запроса к надлежащей основе. Например, «плавайте», «плавание», и «пловец» был бы все преобразован для «плавания». Некоторые происходящие системы могут иметь дело с неправильными окончаниями также. Например, стеммер мог приравняться, «плавал» с «плаванием» даже при том, что основа «плавает», не появляется в этом варианте.
Стемминг не только увеличивает вероятность успешного поиска, это также уменьшает индексный размер.
Если Ваше приложение требует стемминга поведения, можно добавить его сами использование стандартного алгоритма, такого как тот, разработанный Мартином F. Швейцар в 1980. Используя алгоритм стемминга Портера, иногда называемый стеммером Портера, Ваше приложение получило бы текст из документов в корпусе, остановило бы его, и затем вручило бы его для Поиска Набора индексацию. Ваше приложение также применило бы стемминг к запросам.
Следует иметь в виду, что стемминг, как полезный список синонимов, и как список стоп-слова, является языком и доменным зависимым.
Частота минимального срока
Другой способ сократить индексный размер и индексное качество увеличения состоит в том, чтобы использовать частоту минимального срока во время извлечения текста. Система индексации, поддерживающая частоту минимального срока, перескакивает через условия, появляющиеся в документе меньше, чем конкретное количество времен.
Идея позади частоты минимального срока состоит в том что, если срок появляется только один раз в документе, что документ вряд ли будет полезным источником информации о той теме. Поисковый Набор в настоящее время не поддерживает частоту минимального срока, но Вы могли добавить это поведение к своему приложению с помощью других платформ OS X.
Информационно-поисковая система, которая должна поддерживать фразовые поиски, не должна исключать слова из индекса на основе частотности термина, так же, как это не должно исключать слова с помощью длины минимального срока или списка стоп-слова.
Фразовые поиски
Индексы могут быть созданы в пути, поддерживающем поиск близости или фраза. Они позволяют пользователям искать, например, для “Поискового Набора” как полная фраза, в противоположность поиску документов, содержащих условия «поиск» и «набор» где угодно в их содержании.
В индексе, поддерживающем поиск фразы, линейная позиция срока в документе зарегистрирована вместе со ссылкой на документ, в котором появляется срок. Посмотрите рисунок 1-5.
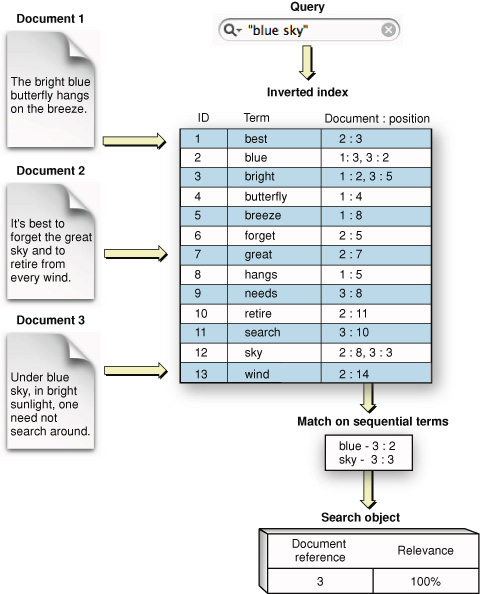
Поиск фразы составляет поиск ряда условий, появляющихся в последовательном порядке. Точно так же поиск близости составляет поиск пары терминов, линейное расстояние которой является маленьким. Поисковый Набор поддерживает фразу, ищущую в инвертированных и инвертировано-векторных индексах, но в настоящее время не поддерживает поиск близости.
Поиск многократных индексов
Возврат теперь нашей метафоре библиотеки: Если библиотекарь выбирает два годовых индекса (один каждый из двух журналов) для нахождения ответа на вопрос об автомобильных значениях предмета, сдаваемого в счет оплаты нового, он создает индексную группу, состоящую из двух индексов, каждый из которых содержит условия из многократных документов. Информационно-поисковые системы могут предложить ту же функциональность. В случае Поискового Набора это до Вашего приложения, чтобы определить и управлять индексными группами.
Так же, как корпус является набором один или несколько связанные документы, индексная группа объединяет один или несколько связанные индексы, как показано на рисунке 1-6.
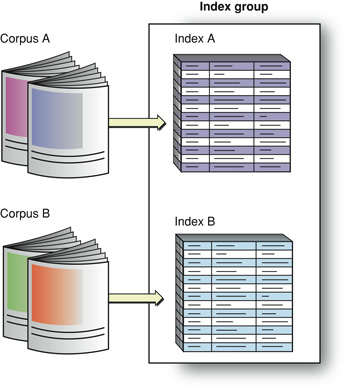
Это число иллюстрирует два индекса, что каждый представляет различный корпус. Можно также создать два индекса на том же корпусе для включения в группу. Например, один индекс мог бы содержать только заголовки статьи, и другой мог бы содержать основной текст статьи. При создании индексной группы с этими двумя индексами поиски на ней покрыли бы оба вида содержания. Индекс «группа», содержащая только индекс заголовка, позволил бы пользователю счесть статьи базируемыми строго на заголовках.
Так же, как библиотекарь не читает журналы при поиске статьи (но переходит прямо к индексу вместо этого), система IR не сканирует документы в корпусе во время поиска. Таким образом, существует задержка между временем извлечения текста во время индексной конструкции и время индексного сканирования во время поиска. В зависимости от того, насколько энергозависимый информация находится в корпусе, и как быстро пользователь ожидает поисковый ответ, приложение, использующее систему IR, может хотеть обновить свои индексы прежде, чем вызвать поиск.
Часто, наилучшее время для обновления индекса после того, как изменение внесено в любой из его ссылочных документов. Когда приложение осуществляет монопольный контроль над созданием, удалением и редактированием его документов, это является надлежащим. Центр внимания, например, использует эту стратегию каждый раз, когда документ изменен, добавлен к или удален из файловой системы OS X.
Формулировка запроса
В нашем продолжающемся примере Вы запустили с потребности общей информации и использовали его для идентификации подходящего, доступного для поиска корпуса — а именно, библиотека с дружелюбным библиотекарем. Вы ожидали, что библиотека будет содержать информацию, в которой Вы нуждаетесь, и Вы ожидали, что он будет эффективно доступен. Благодаря издателям журнала, создающим годовые индексы, это. Рисунок 1-7 числа суммирует эти шаги от вершины вниз на правой стороне.
Следующий шаг в использовании системы IR должен определить определенную информационную потребность и представлять его как запрос, процесс, который число иллюстрирует на левой стороне.
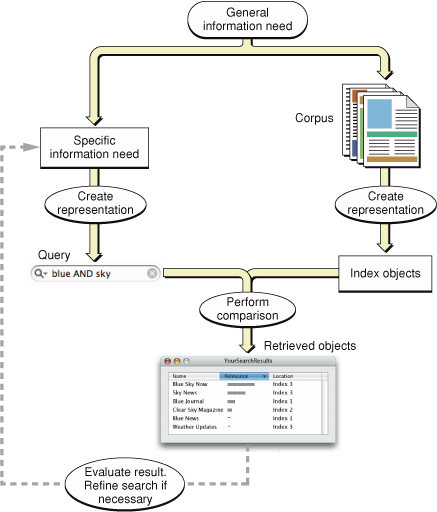
В этой главе мы предположили, что Вы хотите знать, какая марка автомобиля имеет лучшее значение предмета, сдаваемого в счет оплаты нового, и мы предположили, что Вы пользуетесь библиотекой для нахождения ответа. Также Вы могли бы спросить друга или использовать Google. В каждом случае Вы ожидаете, что Ваш выбранный корпус будет содержать ответ. И, в каждом случае необходимо сформулировать определенный запрос, что экспрессы, что Вы хотите знать в условиях, понятых, кем или что Вы спрашиваете.
Вы используете естественный язык для выяснения у друга или библиотекаря и подобного булевской переменной синтаксиса для Google. Для получения ответа с помощью индекса журнала Вы (или библиотекарь) отсканировали бы его алфавитные списки при содержании одного или более ключевых слов в памяти. Другими словами, система IR определяет соответствующую форму для запроса.
Некоторые общие виды запросов для основанных на программном обеспечении систем IR являются булевской переменной, префиксом и фразой. Для получения, что Вы хотите необходимо выбрать надлежащий тип поиска и затем использовать соответствующий синтаксис запроса.
Библиотекарь или система IR могут дать представление для продвижения успешного поиска. Виджет поля поиска Apple, например, обеспечивает стандартный и гибкий интерфейс для вызова поиска.
Чтобы рассмотреть и затем завершить нашу метафору библиотеки, Вы вызываете свою местную библиотеку и просите справочный стол. Очень совместный библиотекарь слушает Ваш автомобильный вопрос о значении предмета, сдаваемого в счет оплаты нового и затем приостанавливает Вас в течение нескольких минут. Библиотекарь выполняет поиск путем сравнения запроса с доступными индексами, представленными на рисунке 1-7 числа, как «Выполняют сравнение» шаг. Он возвращается по телефону, с Вашим полученным ответом на клочок бумаги, и говорит, “Делать из автомобиля с лучшей торговлей в значении в этом году является XYZ”.
У Вас есть свой ответ, но это - не обязательно конец истории. Ответ мог бы предложить Вам понимать, что Вы хотите рассмотреть другие критерии, такие как закупочная цена. Или Вы могли бы хотеть знать, который делает, занимают второе место и треть.
Ответ, который Вы получаете, становится частью того, что известно и помогает Вам фокусироваться более ясно на том, что Вы хотите знать. Информационный поиск часто цикличен таким образом. Системы IR, которые Вы разрабатываете, должны ожидать, что ответы приводят к новым вопросам. Ссылки «Похожих страниц» Google являются примером этого.
Обеспечение результатов
Два основных способа обеспечить результаты в системе IR включением/исключением и уместностью.
Результат включения/исключения включает только документы, удовлетворяющие запрос. Документы не будут ни в каком определенном порядке — они не будут оцениваться уместностью. Если пользователь хочет знать, который CDs в каталоге является (вымышленной) рок-группой Розовыми Виджетами, то Вы просто хотите возвратить все Розовые Виджеты заголовки CD в результате. Можно упорядочить результаты на основе даты выпуска или популярности, но те - соображения вне запроса, инкапсулировавшего запросом.
В случае поиска библиотеки значений предмета, сдаваемого в счет оплаты нового подержанной машины библиотекарь в нашем примере не потрудился говорить, какая статья была лучшей. Он просто нашел информацию и дал ее Вам.
Основанный на уместности результат, с другой стороны, включает документы с диапазоном отношения к запросу. Например, система IR могла бы сортировать заголовки CD Розовыми Виджетами к вершине таблицы результатов, но также и перечислить CDs, содержащий заголовки песни с 'розовыми' словами и 'виджет' в них или CDs, содержащий кавер-версии Розовых песен Виджетов, сортированных ниже в таблице.
Лучший вид представления результата поместит большинство удовлетворяющих соответствий наверху. Больше, чем это, это представит соответствия в пути, помогающем пользователю совершенствовать поиск в случае необходимости — возможно, путем обеспечения контекста для каждого результата, возможно путем предоставления связанной информации, такой как дата модификации или вводимые пользователями комментарии.
Как только Вы добавили информационный поиск к своему приложению, Вы, вероятно, захотите подстроить представление результатов обеспечить максимальное значение. Один способ приблизиться к такой подстройке путем экспериментирования с представительным корпусом и с комплектом ожидаемых пользовательских запросов. С таким экспериментированием можно обнаружить, например, что можно представить наборы аналогичных документов или документов, совместно использующих общий атрибут, как группы в представлении стиля структуры. Например, поиск в OS X с помощью поля поиска Центра внимания показывает, что результаты сортировали по категориям, такие как Документы, Сообщения электронной почты и Документы в формате PDF.