Поисковые понятия набора
В этой главе Вы узнаете о возможностях Поискового Набора, архитектуре, потоке операций и внутренних работах. Прежде, чем считать его необходимо понять условия и идеи, покрытые Поисковыми Основами.
Apple разработал Поисковый Набор как очень гибкую платформу информационного поиска. При использовании Поискового Набора «документ» является любым текстовым контейнером, как понято под Вашим приложением. Вы не ограничиваетесь ищущими файлами на диске, но можете искать любую организацию текстовой информации — страницы, распределенные через сеть, живое содержание базы данных или пользовательские, определенные с помощью приложения данные. Точно так же Ваше приложение может определить что количества как «срок» для Поискового Набора. Для японского текста Поисковый Набор анализирует использование условий японская аналитическая технология языка Apple.
Поисковый Набор использует документ объекты URL, подобные объектам CFURL, для обращения к документам. Используя документ объекты URL, Ваше приложение может определить любой вид иерархии объекта документа и схемы расположения.
Первые два раздела этой главы — Поисковая Архитектура Набора и Поисковый Поток операций Приложения Набора — обеспечивают высокоуровневое понимание. Суть этой главы находится в заключительном разделе, Как Поисковые Работы Набора.
Поисковая архитектура набора
Поисковый Набор API является платформой языка C в платформе защиты Core Services. Также, это использует соглашения управления памятью и обработки ошибок от Базовой технологии Основы Apple и использует Базовые типы данных Основы.
Этот раздел является кратким туром через архитектуру Поискового Набора, обеспечивая как раз достаточно контекста, чтобы понять, как совмещаются части Поискового Набора. Для рытья глубже в любую из тем, представленных в этом разделе, обратитесь к Как Поисковые Работы Набора и Поисковые Задачи Набора.
Индексы, документы и условия
Поисковый Набор использует простую информационную иерархию вместимости, чтобы позволить Вашему приложению управлять содержанием или корпусом, это ответственно за. Рисунок 2-1 иллюстрирует эту иерархию путем увеличивания масштаб последовательно слева направо.
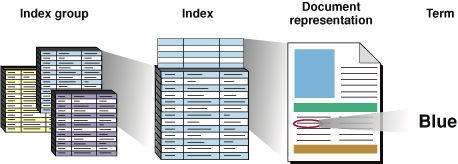
На наиболее удаленном уровне, как показано в числе слева, приложение обычно работает с группой индексов. Индивидуальный индекс, изображенный в числе под возглавляющим «Индексом» и представленный в Поисковом Наборе как SKIndexRef непрозрачный тип, содержит представления одного или более документов.
Представление документа в индексе является парой ключ/значение. Ключ является легким весом, уникальным идентификатором типа SKDocumentID. Соответствующее значение включает документ объект URL типа SKDocumentRef. Увеличивая масштаб одного такого представления документа, число изображает отдельный срок, связанный с одним документом.
Поисковый индекс Набора связывает каждый документ с условиями, извлеченными из него. Срок также представлен как пара ключ/значение в индексе. Ключ срока, как ключ документа, является легким весом, уникальным идентификатором. Срок ID имеет тип CFIndex. Значение для срока включает термин сама строка. Учитывая срок ID, Ваше приложение может получить срок путем вызова SKIndexCopyTermStringForTermID функция.
Индексные группы, как показано слева на рисунке 2-1, явно не поддерживаются в Поисковом Наборе, но имеют много использования. Вы реализуете их в своем приложении для таких вещей как:
Одновременно ища многократные поля в документах, таких как электронные письма, где у Вас есть один индекс для содержания организации, другой для «К» заголовку, и т.д.
Одновременно ища многократные корпуса, такие как многократные почтовые почтовые ящики
Индексные типы
Вы будете обычно создавать находящиеся на диске (персистентные) индексы с помощью SKIndexCreateWithURL функция, создающая индекс в файле. Один индексный файл может содержать любое число Поисковых индексов Набора. Выбор поместить один или больше чем один индекс в файл имеет импликации относительно того, как приложение управляет поисками, как описано далее в этой главе.
Поисковый Набор поддерживает основанные на памяти индексы также с SKIndexCreateWithMutableData функция.
Является ли это файлом или базируемой памятью, Вы устанавливаете возможности индекса при создании его. Существует два аспекта для рассмотрения.
Индексный тип определяет, будет ли индекс оптимизирован для поиска запроса или поиска подобия.
Словарь свойств анализа текста индекса определяет, будет ли индекс поддерживать основанные на фразе поиски. Это также устанавливает различные индексные атрибуты, опирающиеся на индексный размер и поисковую эффективность.
Индексы и поисковые объекты
Новый Поисковый индекс Набора пуст, готов принять документы. Поисковый Набор обеспечивает функции для создания документа объекты URL для добавления их и их связанного текста к индексам, и для переиндексации документов то изменение или перемещение.
Для нахождения документов приложение создает и затем запрашивает поисковый объект. Поисковый объект, после его создания, инициирует поиск и затем действует как динамический репозиторий для результатов. Ваше приложение может сразу запросить поисковый объект после его создания и затем неоднократно получать дополнительные результаты.
Каждый поисковый объект связан точно с одним индексом. Путем создания многократных поисковых объектов можно выполнить поиски на многократных индексах последовательно или параллельно, согласно требованиям приложения.
Поисковый поток операций приложения набора
Выполнение поиска является прямым, двухступенчатым процессом:
Создайте доступный для поиска корпус.
Используя запрос пользователя, выполните поиск и выведите на экран результаты.
Создайте доступный для поиска корпус
Вы делаете текстовое содержание доступным для поиска путем индексации его. Сделать это, Вас:
Создайте пустой индекс с помощью
SKIndexCreateWithURLфункция для основанного на файле индекса, или сSKIndexCreateWithMutableDataфункция для основанного на памяти индекса.Создайте документ, которому URL возражает для добавления к индексу путем вызова
SKDocumentCreateWithURLилиSKDocumentCreateфункция, в зависимости от того, как Ваше приложение хочет управлять Вашим корпусом.Добавьте документ объекты URL и текст к индексу с
SKIndexAddDocumentWithTextилиSKIndexAddDocumentфункции. В общем случае Ваше приложение берет на себя ответственность за вытаскивание текста из документа, с помощью других платформ OS X, и затем вручает текст индексу в форме объекта CFString использованиеSKIndexAddDocumentWithTextфункция. ТакжеSKIndexAddDocumentфункция использует текстовые средства импорта Центра внимания для получения текста от локального, основанного на файле документа.
Выполните поиск и выведите на экран результаты
Запрос информации пользователя включает запрос вместе со спецификацией того, где искать. Запрос включает слова и возможно операторов, такой как “&”, представление логического AND, или «*», подстановочный символ. Спецификация того, где искать — т.е. который индексирует для использования — может быть предоставлена приложением или предоставлена пользователем. Как пример предоставленного пользователями поискового расположения, набор почтовых ящиков, которые пользователь выбирает в Почте, становится активным набором расположений для поиска.
Различные типы индексов поддерживают различные типы поиска, таким образом, можно хотеть, чтобы приложение направило пользователей соответственно в отношении типа запроса. Например, если индекс не поддерживает поиск фразы, Ваше приложение могло бы обеспечить надлежащую обратную связь, если пользователь вводит запрос с разграниченной двойной кавычкой текстовой строкой.
Как подготовка к поиску, Ваше приложение должно использовать SKIndexFlush функционируйте, чтобы обновить и сбросить к диску индексы, указанные в запросе. Обновление и сбрасывание гарантируют, чтобы Вы вызвали поиск на новые данные.
Однако, если информация в корпусе редко изменяется, или если корпус является столь большим, что время, использованное путем обновления индексов, разбило бы пользовательские ожидания, можно хотеть обновить более стратегически. Например, если Ваше управление приложениями, когда документы изменяются, можно обновить индекс инкрементно каждый раз, когда документ изменяется. OS X делает это для поисков файловой системы, использующих Центр внимания посредством уведомлений файловой системы.
Вы создаете поисковый объект с асинхронным SKSearchCreate функция. Вы тогда запрашиваете его с SKSearchFindMatches функция, обеспечивающая результаты как массив документа IDs и параллельный массив, если требуется, очков уместности. Ваше приложение может получить расположения документа для этого IDs, в форме документа объекты URL, путем вызова SKIndexCopyDocumentURLsForDocumentIDs функция. Наконец, Ваше приложение может вывести на экран эти расположения документа как результаты поиска с помощью других платформ OS X.
Дополнительные потоки операций
В дополнение к основанным на запросе поискам Поисковый Набор поддерживает поиск подобия и реферирование. Этот раздел кратко описывает эти потоки операций, а также ведение индексов с точки зрения удаления и переиндексации документов.
Поиск подобия
В поиске подобия пользователь ищет документы, подобные документу в качестве примера. Поток операций почти идентичен потоку операций для поиска запроса с этими различиями:
При создании поискового объекта с
SKSearchCreateфункция, используйтеkSKSearchOptionFindSimilarфлаг в inSearchOptions параметре.Обеспечьте строку, представляющую документ или часть документа, к
SKSearchCreateпараметр запроса функции.
Используя реферирование
Начиная с OS X v10.4, Поисковый Набор вытесняет функциональность реферирования, ранее доступную в Находке Apple С помощью технологии Содержания. Можно использовать реферирование независимо от поиска или как дополнение к дисплею приложения результатов поиска. Найдите Содержанием, остается доступным в OS X для обратной совместимости только.
Для выполнения реферирования, Вы создаете объект реферирования типа SKSummaryRef путем передачи текстовой строки SKSummaryCreateWithString функция. Вы тогда используете SKSummaryCopySentenceSummaryString или SKSummaryCopyParagraphSummaryString функции для генерации предложения - или основанная на абзаце сводка размера Вы хотите. Каждая из этих функций имеет параметр, позволяющий Вам указать сводную длину как целое число предложений или абзацев.
Вы видите реферирование в действии путем выбора блока текста в приложении Mac и затем выбора службы Summarize из подменю Services в меню приложения.
Для дополнительного управления реферированием Поисковый Набор предоставляет другие функции, позволяющие Вам работать с отдельными предложениями и абзацами от объекта реферирования. Для получения дополнительной информации обратитесь к Ссылке SearchKit.
Ведение индексов
Чтобы повторно индексировать документ, изменившийся, но чье расположение является тем же, Вы просто заменяете его в индексе. Если документ переместился, или переместился и изменился, Вы удаляете старую версию и затем добавляете новую версию. Для получения дополнительной информации относитесь для Поиска Задач Набора.
Как работает поисковый набор
Здесь Вы изучаете, как Поисковый Набор работает с документами как абстрактные объекты, как он индексирует содержание, и как он управляет запросами и результатами.
Как поисковые работы набора с документами
Поисковый Набор работает с любым набором текстовой информации как иерархия объекта документа. Этот подход дает Вашему приложению большую гибкость в том, как это определяет и управляет документами.
Существует два способа, которыми Набор Поиска может управлять иерархией объекта документа. Каждый в частности для документов, которые являются находящимися на диске файлами — те, URLs которых использует file схема. Другой является общим; это работает с любым видом документа, является ли это базируемым файлом, память, базируемая, или определенное приложение.
Если Ваше приложение работает с документами, которые являются находящимися на диске файлами, можно использовать иерархию файловой системы непосредственно. При использовании этой опции Вы позволяете Поисковому Набору найти документы и получить их содержание. Документ объекты URL в этом подходе эквивалентен путям файловой системы.
Если Ваши документы не являются находящимися на диске файлами, или Вы хотите больше управления иерархией объекта документа, используете общий подход Поискового Набора. В этом подходе Ваше приложение указывает, с помощью гибкого Формата ссылки, как обратиться к документам. Ваше приложение берет на себя ответственность за определение местоположения документов, и во время индексации, Ваше приложение вручает текстовое содержание документа для Поиска Набора в форме объекта CFString.
С любым подходом при создании документа объект URL Вы даете Поисковый Набор, информация должна была найти документ. Это может быть файловой системой URL, Интернет URL, SQL-оператор, Идентификационный номер, и т.д. — формат до Вашего приложения. Во время поиска, когда Поисковый Набор идентифицирует документ в ответ на запрос пользователя, Ваше приложение может попросить информацию о расположении и использовать его для получения ассоциированного документа.
Работа с документами и документом объекты URL
Используя Поисковый Набор, определение «документа» в основном до Вашего приложения. Документ, для Поиска Набора, является просто locatable блоком текста. Разделение на блоки зависит от Вашего приложения, служащего посредником между Поисковым Набором и информацией, которую Вы хотите искать.
Почтовый клиент, например, мог бы использовать единственный файл простого текста (такой как в Unix mbox формат) для содержания многократных документов — а именно, набор сообщений электронной почты в почтовом ящике. Другое приложение могло бы использовать взаимно-однозначное соответствие между файлами и документами. Или приложение могло бы полагать, что все файлы в папке были единственным, многослойным документом — в этом случае, поиск, пораженный в любом из файлов, на которые ссылаются, мог бы направить пользователя к содержанию папки или пакета. Это до Вашего приложения.
Для Поиска Набора документ является атомарным в этом, это определяет гранулярность поиска. Используя Поисковый Набор, Ваше приложение может найти документы — поскольку Ваше приложение понимает их — но не может определить местоположение позиции срока в документе. Если Вы хотите определить местоположение соответствий для запроса пользователя в найденном документе, используйте MLTE TXNFind функция в Углероде или NSStringrangeOfCharacterFromSet:options: метод в Какао.
Для Поиска Кита структура документа не важна в том Поиске, индексы Кита ничего не знают об абзацах, подзаголовках, тегировании или полях информации в документе. Поиск Кит рассматривает содержание документа просто как мешок условий. Если Вы хотите позволить пользователям искать различными атрибутами документов, Вы создаете индекс для каждого атрибута.
Поисковый Набор затронут только с текстовым содержанием, таким образом, это не отслеживает атрибуты файловой системы, такие как метки времени модификации. В Углероде используйте PBCatSearch функционируйте для поиска атрибутами файловой системы. В Какао используйте NSFileManager класс. Можно также использовать Центр внимания API для поиска документов согласно атрибутам файловой системы или другим метаданным.
Используя расположения документа
Как описано выше, понятие Поискового Набора расположения документа инкапсулируется что-то вызванное документ объект URL. Документ объекты URL соответствует простому типу данных SKDocumentRef. Документ объект URL подобен CFURL, возражает, но позволяет Вам использовать любой формат, что Вам нравится представлять расположение документа. Это до Вашего приложения для интерпретации расположения для получения документа.
Существуют многократные способы создать документ объекты URL. Можно создать их путем преобразования объектов CFURL с помощью SKDocumentCreateWithURL функция. Также можно дать этой функции URL непосредственно. В этом случае можно использовать любую схему URL, которую Вы любите, включая стандартные схемы такой как file, http и ftp; или нестандартные схемы Вашего собственного проекта, такой как data.
Еще один способ создать документ, которому возражает URL, состоит в том, чтобы создать узел иерархии объекта документа узлом. Поисковый Набор поддерживает здание иерархий объекта документа с SKDocumentCreate функция. Эта функция, вместо того, чтобы брать полный URL как SKDocumentCreateWithURL делает, создает URL для Вас от тройной из информации, что Вы вручаете ее: название документа, родительский документ объект URL и дополнительная схема.
Рисунок 2-2 иллюстрирует эти компоненты, поскольку они появляются в URL. Если Вы хотите использовать в своих интересах возможность Поискового Набора определить местоположение и считать локальные, основанные на файле документы, часть Имени должна соответствовать имя файла документа. Если Ваше приложение управляет документами в своих корпусах, часть Имени может соответствовать имя файла документа или нет, согласно потребностям приложения.
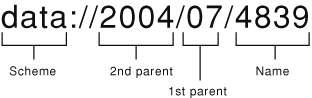
Полный URL является информацией о расположении в документе объект URL. Часть налево от Имени, до, но не включая заключительную наклонную черту, является информацией о расположении в документе объект URL для родителя. Сказать SKDocumentCreate функционируйте схема документа объект URL, используйте текст, запускающийся слева и до, но не включая, двоеточие.
Иерархия объекта документа может быть плоской, основанной на дереве, или более сложной. Ваше приложение определяет и использует его.
Если Вы хотите, с помощью функций, можно определить документ URLs путем сборки их часть частью SKDocumentGetName, SKDocumentGetParent, и SKDocumentGetSchemeName запрашивать документ объекты URL. Запустите в листовом документе и пересеките вверх, родитель к родителю. Это работает со всем документом объекты URL — создаваемые путем преобразования объектов CFURL, создаваемые из URLs непосредственно и создаваемых при помощи имени, родителя и схемы.
Основанное на родителе-дочерними элементами управление иерархий объекта документа Вы добираетесь при помощи SKDocumentCreate когда Вы хотите присоединить информацию, чтобы незадокументировать узлы в иерархии, функция может быть полезной. Например, когда документы в папке были в последний раз индексированы, можно хотеть записать; можно связать ту информацию с документом объект URL папки включения. Это может также быть полезно, когда документы в Вашем корпусе не соответствуют находящимся на диске файлам — например, когда они - записи базы данных или теговые блоки текста в файле включения. В случаях как они узел недокумента является хорошим местом для хранения метаинформации о подчиненных документах.
Побочный эффект мощной общности Поискового Набора в обработке иерархий объекта документа состоит в том, что при создании документа объект URL из многослойного URL Поисковый Набор создает ряд документа объекты URL, один для каждого элемента по пути. Используйте их, если Вы хотите, как просто описано, или игнорируете их, если они не полезны.
В особом случае file URLs, Поиск, который знает Кит, как найти документы для Вас. Это также знает, как получить содержание локальных файлов, как описано в Условиях, От Документов до Индексов. В любом случае Ваше приложение управляет иерархией объекта документа и интерпретирует расположения документа из документа объекты URL.
Можно получить URL самостоятельно из документа объект URL путем передачи объекта SKDocumentCopyURL функция.
Свойства документа
Можно связать информацию с каждым документом в индексе посредством словаря свойств, с помощью SKIndexSetDocumentProperties функция. Формат этого дополнительного словаря может быть столь простым или сложным, как Вы хотите. Например, почтовая программа могла включать словарь свойства для каждого почтового ящика, описывая метаинформацию, такую как число чтения и непрочитанных сообщений, расположения файловой системы почтового ящика, и т.д.
Можно использовать эту информацию о свойстве в качестве контекста для пользователя или для приложения, но Вы не можете непосредственно искать его. Получите информацию о свойстве с помощью SKIndexCopyDocumentProperties функция.
То, как ищут набор, извлекает слова из документов
Условия являются валютой информационного поиска. В поиске Вы обеспечиваете запрос, состоящий из условий, возможно включая операторов, и Поисковый Набор соответствует запрос индексируемым условиям, извлеченным из документов. Здесь Вы изучаете, как условия добираются из документов в индексы. Вы также узнаете о Поисковых индексных типах Набора и о том, как они поддерживают различные типы поиска.
Можно хотеть сначала рассмотреть Индексы Построения в Поисковой главе Основ, обеспечивающей независимое от реализации введение в индексы.
Условия, от документов до индексов
Условия добираются из документов в Поисковые индексы Набора посредством трехступенчатого процесса:
Вы просите, чтобы Поисковый Набор создал новый, пустой индекс, при необходимости в том. Иначе, получите ссылку для существующего индекса.
Вы создаете документ объект URL для каждого из документов, которые Вы хотите индексировать.
Вы добавляете документ объекты URL и текстовое содержание к индексу.
Рисунок 2-3 изображает этот процесс.
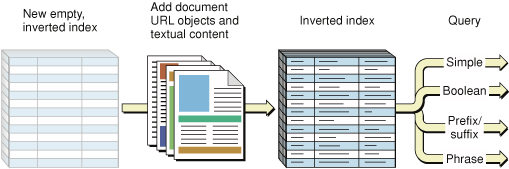
В общем случае и для документов, не соответствующих дисковым файлам — веб-страницам, записям базы данных, разграниченным тегом подмножествам файлов, данных в памяти или пользовательского, специализированного содержания — используют SKIndexAddDocumentWithText функция. Ваше приложение явно отправляет текст документа в форме объекта CFString к функции и обеспечивает расположение документа как документ объект URL. Когда Вы хотите больше управления процессом индексации, можно также использовать эту функцию для дисковых, основанных на файле документов. Когда Ваше приложение понимает семантику тегирования, Вы могли бы сделать это, например, для XML-документа.
Чтобы попросить Искать Набор для получения текстового содержания для Вас от дискового файла с помощью средств импорта Центра внимания используйте SKIndexAddDocument функция. Эта функция преобразовывает путь файловой системы к документу, объект URL, и (со справкой от средств импорта Центра внимания) заставляет текст быть помещенным в индекс.
Если Ваше приложение полагается на средства импорта Центра внимания, когда Ваша программа запускается, скажите Поисковому Набору загружать их путем вызова SKLoadDefaultExtractorPlugIns функция.
В любом случае, функциях «добавлять-документа» —SKIndexAddDocument и SKIndexAddDocumentWithText— проанализируйте текстовое содержание в условия прежде, чем поместить его в индекс. Если Ваше приложение читает японский текст, Поисковый Набор использует японскую аналитическую технологию языка Apple.
Каждый срок в Поисковом индексе Набора имеет уникальный идентификатор и связан со списком документа объекты URL, как проиллюстрировано в Поисковой главе Основ на рисунке 1-2. Различные Поисковые функции Набора позволяют Вам преобразовать между условиями и IDs, определить, какие документы содержат срок, получают число раз, срок появляется в документе и т.д.
Индексные типы
Три типа Поисковых индексов Набора обрабатывают различные требования функциональности и эффективности:
Инвертированные индексы отображают условия на документы. Используйте инвертированный индекс, чтобы позволить пользователям обнаруживать, какие документы соответствуют свои запросы. Это - предпочтительный индексный тип для большинства приложений.
Вектор индексирует документы карты условиям. Используйте векторный индекс, чтобы позволить пользователям найти документы на основе подобного, указанного документа — т.е. выполнить поиск подобия.
Инвертировано-векторные индексы комбинируют характеристики и возможности инвертированных и векторных индексов. Они используют больше пространства памяти и файлового пространства, чем любой из их составляющих типов.
При создании индекса Вы указываете один из этих трех индексных типов с помощью inIndexType параметра в любом SKIndexCreateWithURL или SKIndexCreateWithMutableData функция. Тип определяет, как каждый добавленный документ будет индексирован и косвенно определяет, какие виды поисков Ваши пользователи могут выполнить. Например, векторный индекс не поддерживает Логические запросы или основанный на фразе поиск. Рисунок 2-4 перечисляет различные индексные типы и возможности поиска каждого.

Инвертированные индексы оптимизированы для быстрых основанных на запросе поисков и для минимального индексного размера. Они отображают условия на документ. Т.е. условия являются ключами в парах ключ/значение в инвертированных индексах.
Используйте инвертированный индекс, если основное использование Вашего приложения не является поиском подобия. Несмотря на то, что работа инвертированных индексов для поиска подобия, производительность медленнее, ища подобием с помощью векторного индекса.
Поисковый инвертированный индекс Набора перечисляет каждый составляющий срок точно один раз — независимо от того, сколько из документов, содержавшихся в индексе, включает срок и независимо от того как часто срок появляется в любом из документов. Значение в сроке (ключ, значение) пара в инвертированном индексе включает число, указывающее, сколько из документов индекса содержит срок, IDs документов, использующих термин, и как часто срок появляется в каждом документе.
При указании ищущей близость поддержки при создании индекса индекс также отслеживает позицию каждого экземпляра срока в каждом документе.
Вектор индексирует документы карты условиям. Т.е. документы являются ключами (ключ, значение) пары в векторных индексах. Их основное использование является быстрым поиском подобия.
Значение в документе (ключ, значение) пара в векторном индексе включает число, указывающее, сколько условий документ содержит, IDs условий в документе, и как часто каждый срок появляется в документе.
Векторные индексы не поддерживают булевскую переменную или основанный на фразе поиск. Эти ограничения, вместе с их относительно большим размером, делают их плохим выбором, если Ваша насущная потребность не является быстрым поиском подобия.
Инвертировано-векторные индексы поддерживают каждый тип Поискового Набора, запрашивают, но больше все еще, чем векторные индексы. Когда индексный размер не будет проблемой, их единственное практическое применение должно поддерживать булевскую переменную, основанное на фразе, и быстрое подобие, ищущее на том же индексе, и.
Свойства анализа текста
В дополнение к наличию типа каждый Поисковый индекс Набора имеет словарь свойств анализа текста, определяющий множество индексных характеристик и возможностей. Среди них основанный на фразе поиск, синонимы, слова для исключения из индекса («стоп-слова»), и т.д.
Вы указываете словарь свойств анализа текста для индекса с помощью inAnalysisProperties параметра в любом SKIndexCreateWithURL или SKIndexCreateWithMutableData функция. Доступные ключи для словаря определяются в Text Analysis Keys константы, описанные в Ссылке SearchKit.
Необходимо гарантировать, что целесообразен набор атрибутов, которые Вы присуждаете индексу. Например, потому что Векторные индексы не поддерживают основанный на фразе поиск, не используйте a kCFBooleanTrue значение для kSKProximityIndexing введите словарь свойств анализа текста Векторного индекса.
Разработка индексной архитектуры
Для разработки индексной архитектуры для приложения начните путем ответа на эти вопросы:
Которым документы должны быть в данном индексе?
Индексы должны быть персистентными или базируемая память?
Какие виды запросов индексы должны поддерживать?
Вы хотите отфильтровать содержание, как оно добавляется к индексу (использующий стоп-слова или длину минимального срока)?
Вам нужен список замен срока?
Ваши ответы на эти вопросы будут вести Ваш выбор индексного типа и свойств анализа текста.
Сбрасывание и уплотнение индексов
Когда Ваше приложение добавляет или удаляет документ объект URL из индекса, дисковое или основанное на памяти представление индекса становится устаревшим. Поиск на индексе в таком состоянии не будет иметь доступа к невспыхнувшим обновлениям. Решение состоит в том, чтобы вызвать SKIndexFlush функция перед поиском. SKIndexFlush информация об индексном обновлении сбросов и передает основанные на памяти индексные кэши диску, в случае дискового индекса, или к объекту памяти, в случае основанного на памяти индекса. В обоих случаях вызывание этой функции делает состояние индекса непротиворечивым.
Индексы могут разработать фрагментацию (т.е. они могут стать чрезмерно увеличенными в размерах с неиспользованным текстом), как Ваше приложение добавляет и удаляет документ объекты URL. В случае необходимости, когда Ваше приложение вызывает, поисковый Набор уплотняет индекс SKIndexCompact функция. Поскольку эта функция обычно занимает время для выполнения ее работы, вызовите ее только, когда Вы находите, что значительно фрагментируется индекс.
Для проверки на чрезмерное увеличение размера, можно использовать в своих интересах способ, которым Набор Поиска выделяет документ IDs. Это делает настолько стартовый в 1, и не снова используя ранее выделил IDs для индекса. Просто сравните самый высокий документ ID, найденный с SKIndexGetMaximumDocumentID функция, с количеством текущего документа, найденным с SKIndexGetDocumentCount функция.
Как поисковый набор выполняет поиски
Как только у Вас есть доступный для поиска корпус в форме заполненных индексов, Вы готовы искать. Поиск является многоступенчатым процессом:
Получите запрос пользователя, включая, если применимо, их спецификация того, где искать.
Создайте (или повторное использование) соответствующую индексную группу.
Обновите индексы для запросов по мере необходимости.
Вызовите поиск.
Результаты дисплея на основе информации от возвращенного поискового объекта, и продолжают обновлять результаты как надлежащие, продолжая запрашивать поисковый объект.
В этом разделе описываются работу с индексами и вниманием на общий случай поиска многократных индексов. Это также описывает различные типы запроса, доступного в Поисковом Наборе, и кратко описывает работу с результатами поиска.
Поиск многократных индексов
Во многих случаях приложения должны вызвать поиск по многократным индексам. Например, скажите, что автомобильный покупатель хочет узнать об автомобилях из Америки, Германии и Японии. Ваше приложение могло бы управлять своими автомобильными данными при помощи отдельного индекса для каждой страны изготовления. В этом случае Вы включали бы индексы из указанных стран в поиске пользователя.
Как немного более сложный пример, скажите, что у Вас есть большой набор статических веб-страниц (не сгенерированный по требованию от базы данных) создание интернет-каталога. Каждая страница перечисляет несколько продуктов. Каждый продукт, в свою очередь, мог бы быть элемент одной или более категорий продуктов — спортивный инвентарь, домой и сад, элементы продаж, и т.д. Скажите, что Вы хотели бы, чтобы Ваши пользователи были в состоянии искать названием продукта, ценой и категорией.
Одна стратегия обеспечения поиска на таком веб-сайте состояла бы в том, чтобы определить и соответственно тегировать каждое описание отдельного продукта как документ. Вспомните, что при использовании Поискового Набора «документ» - что-либо, чем Ваше приложение определяет его, чтобы быть. Вы включали бы тегирование в каждом описании продукта, указывающем название продукта, цену и список категорий, которым принадлежит продукт.
Вы могли тогда создать отдельный индекс через веб-сайт для каждого такого поля информации, вместе с индексом всего содержания видимого текста. Поиск пользователя мог указать, какие поля искать на, и Ваше приложение добавят соответствующие индексы к индексной группе, используемой для поиска.
Ищите асинхронная архитектура Набора позволяет Вам искать многократные индексы в последовательности или параллельно, в зависимости от потребностей Вашего приложения и на структуре Вашей информации.
Если Ваше приложение ищет многократные индексы в единственном файле или в отдельных файлах, но все на том же физическом диске, Apple рекомендует искать индексы в последовательности для лучшей производительности.
Когда индексная группа распределяется через многократные диски или через сеть, или когда индексы - все в памяти, ищут индексы параллельно.
Для параллельного поиска Ваше приложение может использовать отдельный поток для каждого индекса, который будет искаться. Также можно создать поисковый объект для каждого индекса в группе, тогда неоднократно запрашивать поисковые объекты поочередно путем использования опции тайм-аута в SKSearchFindMatches функция.
Запросы
Поисковый Набор реагирует на запрос путем интерпретации условий запроса, явных и неявных операторов и порядка условий и операторов запроса. Используя улучшенный, подобный Google синтаксис, Поисковый Набор поддерживает множество типов запроса, а также произвольных комбинаций этих типов. Например, следующий запрос включает булевскую переменную, префикс и суффиксный поиск:
appl* OR *ing
Используя звездочку (*) подстановочный оператор и булевская переменная OR оператор, этот запрос возвращает документы, содержащие слова, начинающиеся «прикладной», а также документы, содержащие слова тот конец с «лугом».
В следующей таблице перечислены операторов для поисков неподобия. (Поиски подобия не реагируют на операторов.) Синонимы, разделенные запятыми здесь, у всех есть тот же порядок оценки.
Оператор † | Значение |
|---|---|
| Открытие и заключительный разделитель для основанного на фразе поиска. |
| Открытие и заключительные разделители для логической группировки. |
| Булевская переменная |
| Булевская переменная |
| Булевская переменная включительно |
| Подстановочный знак для префикса или суффикса; окружите срок подстановочными символами для поиска подстроки. Проигнорированный в основанных на фразе поисках. |
Поисковый запрос Набора может быть столь сложным, как Вы хотите, комбинируя все различные типы оператора. В целях объяснения этот раздел обсуждает каждый тип запроса отдельно.
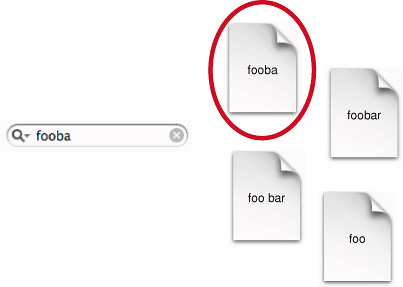
Самый простой вид запроса состоит из:
Одно или более условий
Никакие операторы кроме
<space>символ между условиямиЗначение по умолчанию,
AND- основанное поведение для <пространства>
Такой простой поиск ищет документы в предназначенном наборе индексов, содержащих все условия, вводимые в строку запроса. Индексируемые условия соответствуют запрос, только если они соответствуют точно. Например, если Вы ищете «fooba», и документ содержит «foobar», но не «fooba», Вы не получаете хит. Рисунок 2-5 изображает поведение простого поиска.
Если Вы указываете «средние значения пространства OR«опция с помощью kSKSearchOptionSpaceMeansOR постоянный в SKSearchCreate функция, Поисковый Набор находит не только документы, содержащие все условия запроса. Это также находит документы, содержащие некоторых, но не все, условий запроса; это оценивает такие документы ниже, чем документы, содержащие все условия запроса.
Префиксный поиск ищет документы, представленные в предназначенном наборе индексов, содержащих условия, начинающиеся с символов в запросе. Это особенно полезно для вида живого поиска, Вы видите в Почте и XCode. Поскольку пользователь вводит каждый последовательный символ, найденный набор сужается. Посмотрите рисунок 2-6.
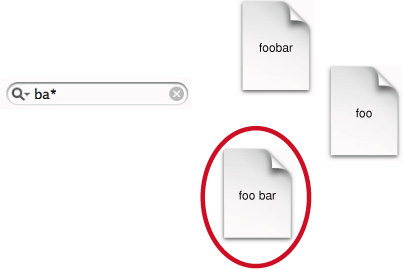
Поиск префикса смотрит на каждый срок в запросе отдельно, ANDлуг многократные условия по умолчанию и соответствия в начале условий в в настоящее время предназначаемом наборе индексов. На рисунке 2-6 слово «панель» в окруженном документе является единственным сроком, начинающимся с тех же символов как в запросе, «ba».
Для вызова префиксного поиска непосредственно пользователь добавил бы звездочку (*) символ до конца каждого срока, который будет использоваться в качестве префикса. Приложение может неявно добавить запаздывающую звездочку для запросов условий перед пересылкой запроса для Поиска Набора.
Вот другой пример префиксного поиска. Если у Вас есть сообщения электронной почты от Билли Боба, Билли Джо и Крупного Руководителя, Вы могли бы войти “Bo*” для нахождения всех сообщений Билли Боба, или “Jo*” для нахождения сообщений Билли Джо. Ввод “Bi*” соответствовал бы сообщения от всех трех друзей “.Bi* OR Ch*” соответствовал бы Крупному Руководителю самой высокой уместности, но будет также соответствовать Билли Бобу и Билли Джо, потому что каждый из них содержит один срок, соответствующий одним из условий запроса. Запрос “illy*” не соответствовал бы ни одного из сообщений электронной почты.
Очень подобный префиксному запросу суффиксный поиск. Поиск суффикса смотрит на каждый срок в запросе отдельно, ANDлуг многократные условия по умолчанию и соответствия на концах условий в в настоящее время предназначаемом наборе индексов. Снова подстановочный символ является звездочкой, но помещенный перед сроком как в»*illy«. И снова можно разработать приложение так, чтобы пользователи явно ввели звездочку перед условиями, или можно добавить звездочку неявно перед передаванием запроса для Поиска Набора.
Поиск с использованием булевых операторов предлагает полную функциональность Поиска с использованием булевых операторов с помощью операторов, описанных в Таблице 2-1. Можно разработать интерфейс приложения так, чтобы пользователи ввели операторов непосредственно, или можно обеспечить альтернативный интерфейс — преобразование запроса для использования Поискового синтаксиса оператора стандарта Набора перед передачей запроса к SKSearchCreate функция.
Поиск с использованием булевых операторов на рисунке 2-7 нанимает группирующихся операторов, а также булевы операторы.
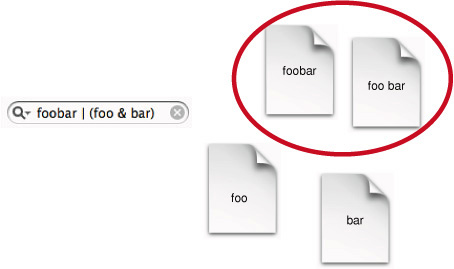
В числе запрос в поле поиска указывает запрос на документы, содержащие точный срок «foobar», а также документы, содержащие и термин «foo» и термин «панель».
Фразовый поиск работает в инвертированном (и инвертированный вектор) индексы, создававшиеся с истинным значением для kSKProximityIndexing введите словарь свойств анализа текста. Такой индекс хранит позицию каждого срока в каждом документе, вместе с информацией, иначе хранившей в инвертированном (или инвертированный вектор) индекс.
Несмотря на имя kSKProximityIndexing свойства анализа текста ключевой, Поисковый Набор в настоящее время не поддерживают произвольный поиск близости. Т.е. Вы не можете искать документы, в которых два слова друг около друга, но не смежны. Поисковый Набор поддерживает только поиск фразы.
Когда пользователь вводит «Яблочный пирог» как запрос — включая окружающие кавычки — Поисковый Набор пытается найти документы, содержащие эту точную фразу. Посмотрите рисунок 2-8 для иллюстрации поиска фразы.

Результаты поиска
Непосредственно после вызова запроса — т.е. после создания поискового объекта — Поисковый Набор асинхронный поиск накапливает результаты в поисковый объект. Используя SKSearchFindMatches функция, Ваше приложение получает результаты поискового объекта, поскольку они входят.
Поиск не возвращает документы по сути. Это возвращает документ IDs. Ваше приложение, в свою очередь, использует документ IDs для получения документа объекты URL от обозначенных индексов. Документ объекты URL, в свою очередь, обратитесь к документам, удовлетворяющим запрос.
Поисковая платформа Набора не обеспечивает функциональность дисплея. Вместо этого Ваше приложение использует другие платформы OS X для представления основных данных результата в способе, которым Вы решаете быть самыми полезными. Таблицы являются популярным способом вывести на экран результаты, но Вы могли точно также представить поисковые хиты в форме схемы как график, или как акустическая обратная связь.