Синтез речи в OS X
OS X включает усовершенствованный синтезатор речи, обеспечивающий высококачественную синтезированную речь и всесторонний синтез речи APIs, позволяющий разработчикам создавать и настраивать разговорный вывод.
В этой главе рассматриваются некоторые преимущества использования синтеза речи в Вашем приложении и описывает компоненты платформы Синтеза речи OS X. Кроме того, эта глава обеспечивает обзор путей, которыми можно настроить речь, которую генерирует приложение. Необходимо считать эту главу, если Вы незнакомы с понятиями синтеза речи или если Вы задаетесь вопросом, как использовать в своих интересах синтезированную речь в Вашем приложении.
Почему синтезированная речь использования?
Несмотря на то, что люди учились связываться с компьютерами и приложениями с помощью экранов дисплея и различных устройств ввода данных, эти методы представляют усилие со стороны пользователей соответствовать коммуникационной парадигме компьютера, не наоборот. Когда приложение производит синтезированную речь, однако, это связывается с пользователями в человеческих условиях естественным и эффективным способом. Используя речь, приложение может передать почти бесконечный диапазон информации пользователю. Поскольку это не ограничивается созданием маленькой группы пользователей звуков, должен учиться связываться с особыми условиями или действиями, приложение, генерирующее речь, может дать пользователям точную информацию о сложных подлежащих и условиях.
Рассмотрите, например, домашнее заявление учета, в которое пользователи вводят данные о своих расходах в течение месяца. Если приложение говорит каждое число, поскольку это вводится, пользователи знают сразу, когда они ввели неправильный номер, никогда не имея необходимость смотреть на экран дисплея. Другим примером является почтовая программа, говорящая пользователям, не только когда новое сообщение поступает, но также и от кого.
Приложения могут также настроить разговорный вывод для соответствия определенным требованиям. Например, изучающее язык приложение может настроить речь для создания точно произнесенных слов, и пользователи фраз могут подражать. Игры и другие приложения развлечения могут использовать речевую настройку для подчеркивания индивидуальности различных экранных символов.
Конечно, приложение, генерирующее речь, могло бы также получить преимущества от разрешения пользователям говорить с нею, использование технологии вызвало распознавание речи. Однако этот документ фокусируется на стороне синтеза речи разговора пользователя компьютера. Можно счесть справочную документацию на распознавании речи OS X APIs в менеджере по Распознаванию речи Референсе.
Разговорный вывод и доступность
Важно понять, что добавление синтезированной речи к приложению и подавание заявки, доступной для всех пользователей (процесс вызвал включение доступа), являются различными процессами с различными целями. В частности добавление поддержки синтезированной речи к Вашему приложению не является тем же как соответствием требованиям доступности, таким как установленные разделом 508 из Закона о реабилитации США 1973.
Несмотря на то, что и сгенерированная приложением речь и речь, произведенная программой экранного доступа или другим вспомогательным приложением, могли бы звучать как то же (и использовать большую часть той же базовой технологии), они выполняют различные функции. Синтезированная речь улучшает пользовательский интерфейс приложения и помогает выполнить специализированные задачи, такие как описание состояний ошибки или обеспечение словесной обратной связи на действиях пользователей. Напротив, речь, сгенерированная вспомогательным приложением, позволяет пользователям получить доступ ко всем частям операционной системы и управлять пользовательскими интерфейсами других приложений, не используя мышь или экран дисплея. Поскольку вспомогательное приложение должно быть в состоянии помочь пользовательскому доступу все приложения, которые они могли бы запустить, это фокусируется на обеспечении доступа к функциям, которые все приложения имеют вместе, такие как меню, кнопки и поля ввода текста.
Для иллюстрирования различия между ролями разговорного вывода приложения и речи, сгенерированной вспомогательным приложением, рассмотрите поддерживающее доступ шахматное заявление. В целях этого обсуждения предположите, что это шахматное приложение производит разговорный вывод, описывающий перемещения, взятые и пользователем и приложением. Используя вспомогательное приложение, слабовидящие пользователи могут запустить это шахматное приложение и активировать все кнопки и другие средства управления в его пользовательском интерфейсе. Однако вспомогательное приложение не может описать перемещение, которое шахматное приложение делает в свою очередь, потому что та информация является результатом изменения во внутреннем состоянии шахматного приложения, не от выбора пункта меню или нажатия кнопки. Если бы шахматное приложение не производило свой собственный разговорный вывод, то слабовидящие пользователи были бы в состоянии передвинуть свои собственные шахматные фигуры, но не были бы в состоянии узнать, как ответило приложение.
В OS X v10.3 Apple, представленном VoiceOver, альтернативный способ взаимодействовать с Macintosh, позволяющим слабовидящим пользователям использовать приложения и сам OS X с помощью только клавиатуру. Поскольку VoiceOver и много других вспомогательных приложений генерируют разговорный вывод, они используют тот же синтезатор речи OS X Ваше использование приложения, когда это генерирует разговорный вывод. В то время как VoiceOver работает, поэтому, пользователи могут испытать прерывания в речи или перекрестных помехах Вашего приложения (перекрывающаяся речь). Чтобы узнать, как VoiceOver взаимодействует с разговорным выводом Вашего приложения и как избежать прерывать разговорный вывод других приложений, посмотрите, Избегают Перекрестных помех.
Понятия синтеза речи и компоненты
В OS X, поддержка платформы Синтеза речи преобразование текста в речь, с помощью общего API для управления речью и синтезаторами. Эта архитектура поддержки многократные, сменные синтезаторы и языки от различных поставщиков, а также многократная речь для каждого синтезатора. Разработчики приложений взаимодействуют с платформой Синтеза речи с помощью API на базе С, определенного в платформе Прикладных служб, Objective C API, определенный в Наборе Приложения или AppleScript say команда. Разработчики инструментов командной строки и других процессов могут соединиться с платформой Прикладных служб для создания разговорного вывода, потому что нет никакого графического интерфейса пользователя, свойственного от синтезированной речи. Даже если Вы не планируете предложить какие-либо специализированные речевые функции, Ваше приложение или преимущества процесса от функции в масштабе всей системы, позволяющей пользователям слышать говоривший вслух почти любой текст, который они могут выбрать.
Платформа Синтеза речи включает:
API синтеза речи Углерода (также названный менеджером по Синтезу речи), который определяется в подплатформе Синтеза речи в платформе Прикладных служб. API синтеза речи Углерода обеспечивает обширное управление синтезом речи к приложениям, которые могут соединиться с платформой Прикладных служб.
NSSpeechSynthesizerкласс, определяющийся в платформе Набора Приложения.NSSpeechSynthesizerкласс обеспечивает основную функциональность синтеза речи для приложений Какао.Синтезаторы речи, содержащиеся в загружаемых пакетах и находящиеся в
/System/Library/Speech/Synthesizers. Синтезаторы выполняют преобразование текста к речи и содержат код, выполняющий лексический анализ и определяющий произношение. Встроенный синтезатор Apple является синтезатором MacinTalk, описанным в Синтезаторе MacinTalk.Речевая речь, которая является пакетами, содержащими отдельные речевые характеристики и, иногда, код. Apple обеспечивает больше чем 20 встроенной речи, находящейся в
/System/Library/Speech/Voices. Для получения дополнительной информации о речи и их отношении к синтезаторам, посмотрите Речь.
Следующие разделы обрисовывают в общих чертах процесс генерации речи OS X и описывают компоненты платформы Синтеза речи и понятия генерации речи. Информация в этих разделах применима к любому приложению, или обработайте, который производит синтезированную речь, независимо от синтеза речи API, который это использует.
Процесс генерации речи
По существу платформа Синтеза речи является механизмом отгрузки, позволяющим Вашему приложению использовать в своих интересах возможности любых синтезаторов речи, речи, и аппаратные средства установлены на компьютере пользователя. Платформа Синтеза речи обеспечивает удобный интерфейс программирования, управляющий доступом к синтезаторам речи и, косвенно, к звуковому оборудованию. Рисунок 1-1 иллюстрирует процесс генерации речи на высоком уровне.
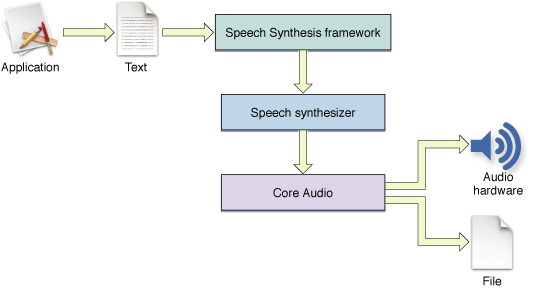
Как обрисовано в общих чертах на рисунке 1-1, Ваше приложение инициирует генерацию речи путем передачи строки или буфера текста к платформе Синтеза речи через надлежащий API. Платформа Синтеза речи ответственна за отправку текста к синтезатору речи, компонента, содержащее исполняемый код, управляющий всей коммуникацией между платформой Синтеза речи и Core Audio.
Синтезатор содержит ряд встроенных словарей, и произношение постановляет, что использует, чтобы определить, как объявить текст. Синтезатор получает текст от приложения и преобразовывает его в фонемы (описанный в Представлениях Речи) и отправляет результат, включая дополнительные директивы произношения, к речи. Каждый синтезатор может работать с только той речью, разработанной для него; даже если речь установлена в компьютере, это не может использовать речь, разработанную для других синтезаторов.
Как показано на рисунке 1-1, Core Audio получает цифровой ввод звуковой волны от синтезатора и отправляет эти данные в текущее устройство звукового вывода или в файл. Поскольку вся коммуникация между платформой Синтеза речи и Core Audio очевидна для Вашего приложения, Вы не должны быть обеспокоены потенциальными изменениями в базовой технологии или реализациях в этой области.
Приложение может участвовать в процессе генерации речи на разных уровнях, в пределах от простого для объединения. В одном конце спектра приложение может быть абсолютно пассивным, позволив пользователям использовать предоставленные систему речевые функции для выбора, когда услышать текст приложения, на котором говорят вслух и с который речь. С другой стороны, приложение может предоставить платформу Синтеза речи точную информацию о том, как речь должна быть произведена и с которой речью на этом нужно говорить. Для больше на путях можно использовать синтезированную речь в приложении, видеть Возможности для Настройки Синтезированной речи.
Представления речи
Существует два способа, которыми Ваше приложение может представлять речь: дословно и фонематическим образом. Текстовое представление состоит из последовательности стандартных, человекочитаемых слов в строке или буфере. Фонематическое представление является текстом, преобразованным в фонемы, которые являются отличными модулями, отличающими одно слово от другого. Различные языки имеют различные наборы фонем. Например, на английском языке, слова «клавиатура» и «плохо» отличены фонемами «p» и «b». Каждая фонема представлена уникальным символом, состоящим из единственных или соединившим прописные или строчные буквы (для полного списка североамериканских английских символов фонемы, распознанных синтезатором MacinTalk, посмотрите Фонемы). Например, фонематическое представление слова “клавиатура" является «pAEd», где символы фонемы «p», “AE “и «d» обозначают “p “, короткое звук, и “d “, соответственно.
Синтезатор речи всегда преобразовывает текст в фонемы прежде, чем отправить его в речь, потому что фонематическое представление позволяет ему кодировать точное произношение каждого слова. Платформа Синтеза речи обеспечивает функцию, позволяющую Вашему приложению преобразовывать текст в фонемы, прежде чем это будет отправлено в синтезатор. В приложениях, говорящих только текст, что пользователи вводят эту функцию, имеет ограниченную полноценность, потому что Вы не можете ожидать то, что мог бы ввести пользователь. Однако, если Ваше приложение говорит конечное множество слов или фраз, которые Вы создаете, может быть полезно представлять, по крайней мере, часть того текста фонематическим образом для обеспечения его желаемого произношения.
Выполнение Вашего собственного графемно-фонемного преобразования имеет следующие преимущества:
Можно использовать процесс графемно-фонемного преобразования, который мог бы иметь более высокое качество, чем предоставленный доступным синтезатором. Можно тогда использовать фонематические данные, которые Вы генерируете таким образом с любым синтезатором речи для создания лучшей речи.
Можно использовать модификаторы фонемы для корректировки произношения слов, давая Вам очень высокую степень управления разговорным выводом. Например, можно изменить размещение основного напряжения в слове.
Можно использовать формат TUNE для формирования полной мелодии и синхронизации произнесения. Формат TUNE (описанный в Использовании Формат TUNE для Предоставления Сложных Контуров Подачи) позволяет Вам создавать шаблон подачи и изменений уровня и применять его к фонематическому представлению слова или фразы. Например, можно использовать формат TUNE для создания звука произнесения, как будто на нем говорят с эмоцией.
Платформа Синтеза речи также позволяет Вам вкраплять фонематические представления определенных слов и фраз в буфере текста. Это полезно, если текст, который должно говорить Ваше приложение, содержит слова с нестандартным произношением, таким как имена собственные или слова, Вы хотите говориться определенным способом. Для объединения текстовых и фонематических представлений речи таким образом необходимо использовать встроенные речевые команды (описанный в Речевом Качестве Управления Используя Встроенные Речевые Команды).
Речь
Речь является рядом характеристик, показывающих определенные качества речи, такие как подача и тон. Так же, как речь каждого лица имеет уникальные качества звука, так также делает каждую синтезируемую речь. Синтезируемая речь могла бы звучать как штекер или розетка и могла бы походить на взрослого или дочерний элемент. В то время как другие звучат более естественными, некоторая синтезируемая речь звучит отчетливо как синтетический продукт. Для исследования диапазона речи, прибывающей установленная в OS X перейдите к области Speech Установок системы, щелкните по тексту к вкладке Speech и слушайте речь, перечисленную в Системном Голосовом меню. Ваше приложение может использовать системную речь по умолчанию для генерации речи, или это может использовать синтез речи API, чтобы выбрать (или позволить пользователям выбирать) одна из другой речи, доступной в системе пользователя.
Несмотря на то, что единственная речь поддерживает только один язык и область, синтезатор может содержать любое число речи, каждая из которой может поддерживать различный язык. Рисунок 1-2 показывает, как различные синтезаторы и их речь могут сосуществовать на компьютере.
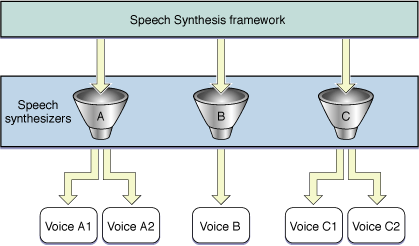
Платформа Синтеза речи определяет структуру данных, названную речевой записью описания, содержащей информацию о речи, такой как ее имя, род, возраст, язык и синтезатор, с которым это связано. Платформа обеспечивает функции, позволяющие Вам идентифицировать, сколько речи в настоящее время доступно в системе пользователя и получить информацию в речевой записи описания для определенной речи. Несмотря на то, что большая часть информации в речевых записях описания не должна быть представлена пользователям, можно вывести на экран часть ее, такую как речевое имя, чтобы помочь пользователям сделать информированный выбор.
Обратите внимание на то, что, в целом, Ваше приложение не должно знать, какой синтезатор речи оно использует или с которым синтезатором речи связан высказавший. Однако некоторые синтезаторы речи обеспечивают специальные возможности в дополнение к предоставленным платформой Синтеза речи. Например, синтезатор речи мог бы позволить Вам выбирать опцию говорить все числа нестандартным способом, такие как цифра-разрядным. Для этих обстоятельств платформа Синтеза речи обеспечивает APIs, позволяющий Вам определять, какой синтезатор связан с речью и обеспечивает рычаги, позволяющие Вашему приложению использовать в своих интересах специфичные для синтезатора возможности.
Поскольку речевая технология продолжает разрабатывать, вероятно, что речь, к которой может получить доступ Ваше приложение, будет звучать все более и более человеческой. При использовании синтеза речи OS X APIs Вы автоматически получаете преимущества от любых улучшений, сделанных к речи, встроенной в систему. Независимо от речи, используемой для разговора вывода, можно настроить способ, которым это говорит текст, использование методов, обрисованных в общих чертах в, Корректирует Речевые Атрибуты и Речеобразование Управления Используя Синтез речи APIs и Речевое Качество Управления Используя Встроенные Речевые Команды.
Речевые каналы
Чтобы отправить текст в синтезатор и указать, какую речь или атрибуты Вы хотели бы, чтобы он использовал, Ваше приложение использует речевой канал. Концептуально, речевой канал является кабелепроводом между Вашим приложением и платформой Синтеза речи. Ваше приложение получает речевой канал, отправляет через него текст, на котором будут говорить, и, дополнительно, устанавливает атрибуты речевого канала, влияющие на синтезированную речь.
Точно то, как Ваше приложение взаимодействует с речевым каналом, определяется API, который оно использует. API синтеза речи Углерода включает функции, которые Вы используете, чтобы создать и управлять речевыми каналами, а также функциями, позволяющими Вам получать и устанавливать атрибуты речевого канала. С другой стороны, в синтезе речи Какао API, управление речевого канала очевидно для Вас. При использовании Какао API для генерации разговорного вывода, необходимые речевые каналы создаются, используются и уничтожаются автоматически. Точно так же AppleScript say команда не представляет использование речевых каналов. Какой бы ни API, который Вы используете, однако, полезно понять роль речевых каналов в процессе генерации речи. Остаток от этого раздела описывает эту роль и как некоторые приложения, возможно, должны были бы создать многократные речевые каналы.
В любом моменте времени речевой канал связан с определенной речью и определенными речевыми атрибутами. Однако многократные речевые каналы могут сосуществовать в отдельном приложении, позволяющем Вашему приложению создавать больше чем одну вокальную среду к, например, моделировать диалог среди различных символов в игре. Также можно использовать единственный речевой канал и переключиться на различную речь при необходимости, но этот подход может быть неэффективным. Примером приложения, требующего многократных речевых каналов, является тот, который должен генерировать речь больше чем на одном языке. Как упомянуто Речью, речь связана только с одним языком и областью, таким образом, для приложения, которое должно произвести разговорный вывод в двуязычной или многоязычной среде, был бы нужен отдельный речевой канал для каждого языка.
Отдельные речевые каналы в отдельном приложении могут генерировать речь одновременно согласно возможностям процессора. Однако эта возможность должна использоваться с ограничением, потому что для пользователей очень трудно понять речь, когда больше чем один канал генерирует речь одновременно. Конечно, различные речевые каналы, создаваемые различными приложениями, могут также произвести речь одновременно; поэтому, это - хорошая идея реализовать арбитражную схему в Вашем приложении (для получения дополнительной информации о том, как сделать это, посмотрите, Избегают Перекрестных помех).
Уведомления, обратные вызовы и речевая синхронизация
Платформа Синтеза речи позволяет Вам получать уведомления об определенных событиях во время процесса генерации речи. Используя эти уведомления, можно синхронизировать речь с действиями в приложении, такими как выделение произнесенного слова или анимирующий рот символа для соответствия объявляемой фонеме.
Не удивительно, синтез речи Какао и Углерода APIs поддерживает различные наборы уведомлений и реализует их по-другому (AppleScript не поддерживает синхронизацию речи с действиями приложения). API Какао определяет методы делегата, которые можно реализовать; API Углерода определяет большое количество обратных вызовов, для которых можно обеспечить функции-обработчики.
Некоторые уведомления, которые можно получить, говорят Вам когда:
Слово собирается быть произнесенным
Фонема собирается говориться
Разговор закончился
Текст обработали, но не обязательно говорили все же (доступный только в Углероде API)
A
syncсо встроенной речевой командой встречаются (доступный только в Углероде API). Для получения дополнительной информации об этой команде, посмотрите OS X Встроенные Речевые Команды.
Для получения дополнительной информации об определенных доступных уведомлениях и как использовать их в Вашем приложении, посмотрите, Синхронизируют Речь со Специализированными Действиями.
Синтезатор MacinTalk
Синтезатор MacinTalk является встроенным синтезатором в OS X. Это генерирует североамериканский английский язык из неограниченного текста и поддерживает добавление многих встроенных в текст команд для управления произношением и интонацией. Вывод синтезатора MacinTalk может играться через динамики компьютера или сохраняться к файлу.
В целом синтезатор производит наиболее естественно звучащую речь, когда это комбинирует свои встроенные правила обработки текста с подсказками произношения, предоставленными автором текста. Синтезатор MacinTalk содержит сложный лексический анализатор, позволяющий ему высказывать “лучшее предположение” в том, как человек мог бы говорить данную выборку текста. Когда Вы предоставляете точную информацию произношения, но синтезатор MacinTalk (как все синтезаторы) выполняет лучшую работу. Является ли синтезированная речь дополнительной функцией или составляет главную центральную часть функциональности Вашего приложения, необходимо рассмотреть использование стратегий настройки, описанных в Возможностях для Настройки Синтезированной речи для обеспечения производства высококачественной речи, соответствующей спецификациям.
Атрибуты синтезированной речи
Любое данное лицо имеет только одну речь, но может значительно изменить характеристики и значение его или ее речи путем варьирования подачи, объема и скорости поставки. Люди инстинктивно реагируют на эти вокальные атрибуты и полагаются на них для обеспечения уровней значения в дополнение к семантическому значению слов, которые они слышат. Платформа Синтеза речи предоставляет функции, позволяющие Вам управлять речевыми атрибутами, такими как подача и скорость, достигать эффектов, которые Вы хотите.
Речевой атрибут является установкой, определенной на речевом канале, влияющем на качество разговорного вывода для определенного подмножества речи, или для всей речи, связанной с определенным синтезатором. В любом единственном моменте времени существует взаимно-однозначное соответствие между речью и речевым каналом, таким образом, можно думать о речевом атрибуте как применяющийся к или речи или к речевому каналу. Используя функции в синтезе речи Углерода API, можно изменить четыре речевых атрибута: уровень, подача, передает модуляцию и объем. Также можно использовать встроенные речевые команды для установки этих четырех атрибутов, плюс атрибут просодии, на основе на слово, независимо от языка программирования, который Вы используете. Для получения дополнительной информации о том, как использовать встроенные команды, посмотрите Использование Встроенные Речевые Команды для Подстраивания Разговорного Вывода.
Речевой уровень
Речевой уровень речевого канала является приблизительным количеством слов текста, который синтезатор говорит за одну минуту. Несмотря на то, что более медленный речевой уровень может произнести речь, проще понять, слушая слова, произнесенные, слишком медленно может быть утомительным. Обязательно протестируйте Ваше приложение для устанавливания оптимального речевого курса для целевой аудитории, таким образом, можно поставить приложение с разумной настройкой по умолчанию. Слабовидящие пользователи, например, часто удобны слушающий намного более быстрые речевые уровни, чем зрячие пользователи.
Речевые уровни выражены как действительные значения. Например, типичная, диалоговая речь на уровне приблизительно 180 слов в минуту, тогда как некоторые слабовидящие пользователи могут удобно слушать VoiceOver на уровнях до 500 слов в минуту. Каждый синтезатор речи определяет свой собственный диапазон речевых уровней, которые могут быть применены к речи, которую он использует. Синтез речи Углерода API включает функции, позволяющие Вам получать и изменять текущий речевой уровень на речевом канале (для получения дополнительной информации о том, как сделать это, посмотрите, Корректируют Настройки Речевого канала Используя Синтез речи Углерода API).
Речевая подача, частота и модуляция подачи
Подача является комбинацией средней говорящей частоты и ее изменений вокруг того среднего числа. При слушании речевого разговора Вы знаете об изменениях в подаче, создающих своего рода мелодию. Часто, Вы больше знаете об этом музыкальном качестве при слушании переговоров на языке, Вы не говорите, потому что Вы не фокусируетесь на семантическом значении того, что Вы слышите. Для создания человекоподобной речи, поэтому, синтезатор должен попытаться тиражировать эти изменения подачи в свою речь.
Речевая подача речевого канала представляет среднюю подачу речи, от которой фактические передачи речи могут меняться в зависимости от повышения и падающих мелодий. Можно думать о речевой подаче как примерно соответствие ключу, который играется песня. Речевая подача выражена как действительное значение в диапазоне от 0.000 до 127 000, где 60.000 соответствует середине C на стандартном фортепьяно. Каждое изменение с 1.000 модулями в значении речевой подачи соответствует музыкальному полушагу. Можно заметить, что это - тот же масштаб, использующийся для указания длительности нот MIDI. Несмотря на то, что масштаб является тем же, однако, значения речевой подачи отличаются от длительности нот MIDI двумя фундаментальными способами: значения речевой подачи не должны являться неотъемлемой частью, и они занимают более узкий диапазон, чем длительность нот MIDI.
В этом масштабе изменение +12 модулей соответствует удвоению частоты (увеличение одной октавы), и изменение-12 модулей соответствует сокращению вдвое частоты (уменьшение одной октавы). Частота является точной индикацией относительно числа герц (Гц) звуковой волны в любой момент. Типичные частоты речевого диапазона могли бы расположиться приблизительно от 75 Гц для низкого мужского голоса приблизительно к 300 Гц для речи высокого дочернего элемента. Эти частоты соответствуют приблизительным значениям речевой подачи в диапазонах 30 000 - 40 000 и 55 000 - 65 000, соответственно. Если необходимо преобразовать между речевыми передачами и герц, обратите внимание на то, что речевая подача 60 000 соответствует 261,625 Гц.
Синтез речи Углерода API включает функции, чтобы определить текущую речевую подачу на речевом канале и изменить речевую подачу (см., Корректирует Настройки Речевого канала Используя Синтез речи Углерода API для получения дополнительной информации о том, как сделать это).
Для моделирования изменчивости в частоте в человеческой речи платформа Синтеза речи определяет вызванную модуляцию подачи атрибута речи. Модуляция подачи речевого канала является максимальной суммой, которой фактическая частота сгенерированной речи может отклониться от речевой подачи.
Модуляция подачи выражена как действительное значение в диапазоне от 0.000 до 100 000. Значение модуляции подачи 0.000 соответствует монотонности, в которой вся речь сгенерирована в частоте, соответствующей речевой подаче. Речь, сгенерированная при этой модуляции подачи, звучит противоестественно автоматизированной.
Динамический диапазон речевых сигналов
Динамический диапазон речевых сигналов речевого канала является средней амплитудой, в которой канал генерирует речь. Динамические диапазоны речевых сигналов выражены как действительные значения в пределах от 0,0 до 1,0. Значение 0,0 соответствует тишине, и значение 1,0 соответствует максимальной громкости, которая может быть произведена доступными аудио аппаратными средствами. Единицы объема лежат на масштабе, который линеен с амплитудой или напряжением; поэтому, удвоение значения динамического диапазона речевых сигналов соответствует удвоению воспринятой громкости.
Так же, как синтезатор обычно не генерирует речь в постоянной частоте, это не генерирует речь в постоянной амплитуде. Даже когда речевой уровень является высокими, краткими случаями тишины (такими как паузы между фразами), разбивают непрекращающийся поток речи. Динамический диапазон речевых сигналов, как речевая подача, является индикатором среднего числа. Синтез речи Углерода API обеспечивает функцию, которую можно использовать для регулирования громкости текущего речевого канала (см., Корректирует Настройки Речевого канала Используя Синтез речи Углерода API, чтобы узнать, как сделать это).
Просодия
Самый сложный речевой атрибут является просодией. Речевой атрибут просодии описывает ритм, модуляцию и образцы акцента речи, такие как слово и напряжение слога и подача в конце предложения. Несмотря на то, что нет никакого простого механизма для Вашего приложения для определения, какие ритмичные образцы синтезатор речи автоматически применяется к речи, можно осуществить некоторый контроль над этим аспектом разговорного вывода при помощи emph встроенная речевая команда (описанный в OS X Встроенные Речевые Команды). Кроме того, можно использовать функции в синтезе речи Углерода API, чтобы включить или отключить конечную просодию, которая является модуляцией подачи, что синтезатор речи применяется к концу предложения.
Основным путем можно влиять на просодию разговорного вывода приложения, при помощи формата TUNE для предоставления подачи и спецификаций уровня для отдельных слов или фраз. Для получения дополнительной информации о том, как сделать это, посмотрите Использование Формат TUNE для Предоставления Сложных Контуров Подачи.
Возможно, больше, чем с другими речевыми атрибутами, можно провести много времени, подстроив просодию речи, которую генерирует приложение. Если у Вас есть ограниченный набор строк, Ваше приложение должно говорить, однако, это хорошо стоит усилия скорректировать просодию (вместе с другими речевыми атрибутами) для достижения цели. Для некоторых других способов произвести лучше звучащую речь, см. Четыре Способа Улучшить Разговорный Вывод.
Возможности для настройки синтезированной речи
Поддержка платформы Синтеза речи много методов для настройки речи Ваше приложение генерирует, в пределах от простого для объединения. Этот раздел обрисовывает в общих чертах различные варианты, доступные Вам.
Когда Вы готовы начать разрабатывать Ваше приложение для включения некоторых или всех настроек, описанных в этом разделе, необходимо считать Разработку и Реализацию Приложения, Выступающего за исследование доступного APIs, руководства на конструктивных соображениях и информации о реализации основных задач синтеза речи. Затем считайте Методы для Настройки Синтезированной речи для всесторонней информации о настройке.
Используйте различную речь
Одной из первых вещей, пользователи замечают о речи Ваши продукты приложения, является речь, говорящая его. Следовательно, использование определенной речи является простым способом настроить разговорный вывод Вашего приложения.
Если сама речь не является важной функцией в Вашем приложении, можно просто использовать речь системного значения по умолчанию (обратите внимание на то, что пользователи могут установить речь по умолчанию в Речевых Установках системы). Однако можно хотеть определять определенную речь (или речь) или предоставить пользователям возможность выбрать речь. Например, если Вы разрабатываете игру, выводящую на экран больше чем один отличный символ, необходимо быть в состоянии дать каждому символу его собственную речь. С другой стороны, при разработке интерактивного приложения для дочерних элементов Вы могли бы хотеть дать им выбор интересной речи, из которой можно выбрать.
Обозначение определенной речи или набора речи требует, чтобы Вы узнали, какая речь доступна в системе пользователя, исследует отдельные речевые описания для определения, которые Вы хотите и говорите синтезатор который речь использовать. И синтез речи Какао и Углерода, APIs обеспечивает программируемые способы сделать это (см. листинги кода в Реализации Основных Задач Синтеза речи Используя Какао и Углерод для некоторых примеров).
Скорректируйте речевые атрибуты и управляйте речеобразованием Используя синтез речи APIs
Как описано в Атрибутах Синтезированной речи, платформа Синтеза речи определяет несколько атрибутов, описывающих аспекты речи, такие как объем и подача. Платформа Синтеза речи обеспечивает функции, позволяющие Вам корректировать уровень и подачу. Обратите внимание на то, что эти функции действуют на речевые каналы, не на сам текст. Это означает, что, например, изменяя речевой уровень речевого канала эффективно изменяет уровень всей речи, которую производит канал. Кроме того, Вы не можете предположить, что такое изменение сохранится при изменении речи на канале. Это вызвано тем, что сообщение канала использовать различную речь может заставить параметры всего канала быть сброшенными к значениям по умолчанию. Кроме того, новая речь может не поддерживать некоторые настройки атрибута. Однако могут быть случаи, в которых это целесообразно для Вашего приложения изменять речевой уровень или подачу, такой как в ответ на пользовательский запрос. Для примера того, как сделать это, посмотрите, Корректируют Настройки Речевого канала Используя Синтез речи Углерода API.
Можно осуществить контроль над производством разговорного вывода при помощи функций синтеза речи, чтобы остановить, приостановить, и продолжать речь. Например, Вы могли бы позволить пользователям выбирать пункт меню Stop Speaking или нажимать кнопку Pause для управления разговорным выводом. Для получения дополнительной информации о функциях и методах можно использовать для управления потоком речи и примерами того, как использовать их, посмотрите Реализующие Основные Задачи Синтеза речи Использовать Какао и Углерод.
Несмотря на то, что можно использовать функции синтеза речи для корректировки речевых атрибутов, таких как объем и подача, Вы не можете использовать их для успешной корректировки произношения слов. Для подстраивания произношения или просодии отдельных слов и фраз необходимо использовать встроенные речевые команды (описанный в Речевом Качестве Управления Используя Встроенные Речевые Команды).
Речевое качество управления Используя встроенные речевые команды
Встроенная речевая команда позволяет Вам управлять качеством разговорного вывода с большой точностью, потому что Вы связываете его с отдельным словом или фразой, на которую Вы хотите влиять. Встроенные команды могут использоваться в буферах (или строки) и текстовых и фонематических представлений речи. Фактически, можно объединить фонематические представления определенных слов или фраз с текстовыми представлениями в той же строке или буфере.
Встроенные команды позволяют Вам вносить точные корректировки в произношение слов, способ, которым слова подчеркнуты в предложении и полном тактовом сигнале речи. Можно использовать встроенные команды, чтобы произнести речь, проще понять и больше звучания человека или подражать определенному произношению и интонациям. Кроме того, использование этого метода присуждает значительное преимущество: Вы не должны делать изменения в API Вашими вызовами приложения для генерации речи, потому что встроенные команды содержатся в тексте, который приложение передает синтезатору. Ваша потребность приложения только вызывает стандартные функции или методы, начинающие процесс генерации речи, такой как SpeakString или startSpeakingString: (для получения дополнительной информации о них посмотрите примеры в Реализации Основных Задач Синтеза речи Используя Какао и Углерод).
Несмотря на то, что встроенные команды являются самыми полезными для управления речью, Вы создаете, можно также добавить, что входят встроенные команды для управления речью, сгенерированной от текстовых пользователей. Например, приложение текстового редактора могло бы встроить команды, говорящие синтезатору подчеркивать произношение слов, которые пользователь имеет наглый или подчеркнутый. Для описания доступных встроенных команд и примеров того, как использовать их, посмотрите Использование Встроенные Речевые Команды для Подстраивания Разговорного Вывода.
Одна встроенная команда, [[inpt <mode>]] команда, говорит синтезатору интерпретировать содержание после команды в режиме, определяемом значением <mode> параметр, пока это не достигает другого [[inpt <mode>]] команда. Например, для предоставления точного, фонематического представления слова, появляющегося в буфере текста Вы предшествуете слову с [[inpt PHON]] команда, говорящая синтезатору интерпретировать следующее содержание фонематическим образом и вставлять [[inpt TEXT]] команда после слова для сигнализации возврата к текстовому представлению.
[[inpt <mode>]] команда также включает режим, позволяющий Вам использовать в своих интересах формат TUNE, который является форматом ввода, кодирующим точную интонацию для слова или фразы. Можно использовать формат TUNE для тиражирования интонации и синхронизации определенного произнесения. Для получения дополнительной информации об этом формате и как использовать его, посмотрите Использование Формат TUNE для Предоставления Сложных Контуров Подачи.