Параллель данных вычисляет обработку: вычислите кодер команды
Эта глава объясняет, как создать и использовать a MTLComputeCommandEncoder объект закодировать параллель данных вычисляет состояние обработки и команды и представляет им для выполнения на устройстве.
Для выполнения параллельного данным вычисления выполните эти основные шаги:
Используйте a
MTLDeviceметод для создания вычислить состояния (MTLComputePipelineState) это содержит скомпилированный код от aMTLFunctionобъект, как обсуждено в Создании Вычислить состояния.MTLFunctionобъект представляет вычислить функцию, записанную с Металлическим языком штриховки, как описано в Функциях и Библиотеках.Укажите
MTLComputePipelineStateобъект, который будет использоваться вычислить кодером команды, как обсуждено в Указании Вычислить состояния и Ресурсов для Вычислить Кодера Команды.Укажите ресурсы и связанные объекты (
MTLBuffer,MTLTexture, и возможноMTLSamplerState) это может содержать данные, которые будут обработаны и возвращены вычислить состоянием, как обсуждено в Указании Вычислить состояния и Ресурсов для Вычислить Кодера Команды. Также установите их табличные индексы параметра, так, чтобы Металлический код платформы мог определить местоположение соответствующего ресурса в коде программы построения теней. В любой данный момент,MTLComputeCommandEncoderможет быть связан со многими объектами ресурса.Диспетчеризируйте вычислить функцию конкретное количество времен, как объяснено в Выполнении Вычислить Команды.
Создание вычислить конвейерное состояние
A MTLFunction объект представляет параллельный данным код, который может быть выполнен a MTLComputePipelineState объект. MTLComputeCommandEncoder объект кодирует команды, устанавливающие параметры и выполняющие вычислить функцию. Поскольку создание, вычислить конвейерное состояние может потребовать дорогой компиляции Металлического кода языка штриховки, можно использовать или блокирование или асинхронный метод запланировать такую работу в пути который лучшие адаптации проект приложения.
Для синхронного создания вычислить конвейерного объекта состояния вызовите любого
newComputePipelineStateWithFunction:error:илиnewComputePipelineStateWithFunction:options:reflection:error:методMTLDevice. В то время как Металл компилирует код программы построения теней для создания конвейерного объекта состояния, эти методы блокируют текущий поток.Для асинхронного создания вычислить конвейерного объекта состояния вызовите любого
newComputePipelineStateWithFunction:completionHandler:илиnewComputePipelineStateWithFunction:options:completionHandler:методMTLDevice. Эти методы сразу возвращаются — Металл асинхронно компилирует код программы построения теней для создания конвейерного объекта состояния, затем вызывает обработчик завершения для обеспечения новогоMTLComputePipelineStateобъект.
Когда Вы создаете a MTLComputePipelineState объект можно также принять решение создать отражательные данные, показывающие подробные данные вычислить функции и ее параметров. newComputePipelineStateWithFunction:options:reflection:error: и newComputePipelineStateWithFunction:options:completionHandler: методы предоставляют эти данные. Избегите получать отражательные данные, если они не будут использоваться. Для получения дополнительной информации о том, как проанализировать отражательные данные, посмотрите Определение Функциональных Подробных данных во Время выполнения.
Указание вычислить состояние и ресурсы для вычислить кодера команды
setComputePipelineState: метод a MTLComputeCommandEncoder объект указывает, что состояние, включая скомпилированный вычисляют функцию программы построения теней, для использования для параллели данных вычисляют передачу. В любой данный момент вычислить кодер команды может быть связан с только одним, вычисляют функцию.
Следующий MTLComputeCommandEncoder методы указывают ресурс (т.е. буфер, текстура, состояние сэмплера или threadgroup память), который используется в качестве параметра вычислить функции, представленной MTLComputePipelineState объект.
Каждый метод присваивает один или несколько ресурсов соответствующему параметру (ам), как проиллюстрировано на рисунке 6-1.
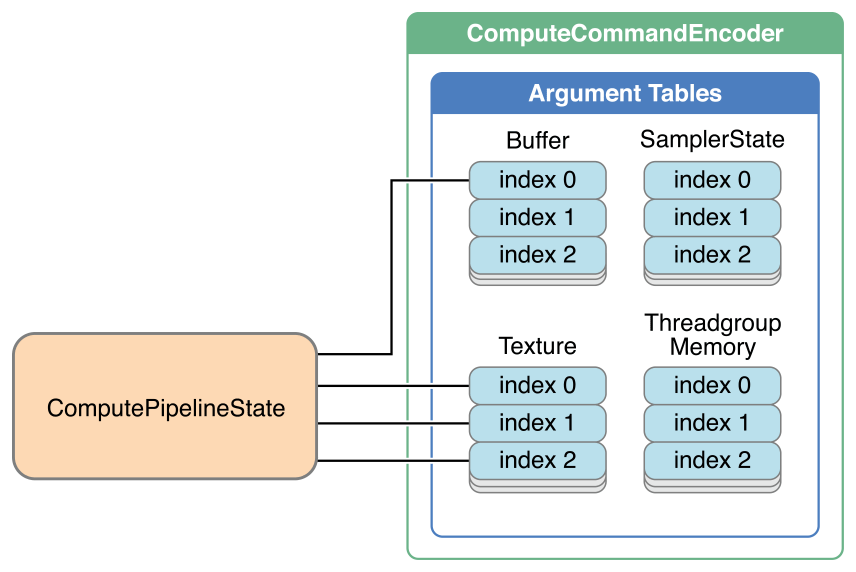
Существует максимум 31 записи в буферной таблице параметра, 31 записи в таблице параметра текстуры и 16 записей в таблице параметра состояния сэмплера.
Общее количество всех threadgroup выделений памяти не должно превышать 16 КБ; иначе, ошибка происходит.
Выполнение вычислить команда
Для кодирования команды для выполнения вычислить функции вызовите dispatchThreadgroups:threadsPerThreadgroup: метод MTLComputeCommandEncoder и укажите threadgroup размерности и число threadgroups. Можно запросить threadExecutionWidth и maxTotalThreadsPerThreadgroup свойства MTLComputePipelineState оптимизировать выполнение вычислить функции на этом устройстве.
Для самого эффективного выполнения вычислить функции, определенной общий номер потоков, указанных threadsPerThreadgroup параметр dispatchThreadgroups:threadsPerThreadgroup: метод к кратному числу threadExecutionWidth. Общее количество потоков в threadgroup является продуктом компонентов threadsPerThreadgroup: threadsPerThreadgroup.width * threadsPerThreadgroup.height * threadsPerThreadgroup.depth. maxTotalThreadsPerThreadgroup свойство указывает максимальное количество потоков, которые могут быть в единственном threadgroup для выполнения, это вычисляет функцию на устройстве.
Вычислите команды, выполняются в порядке, в котором они кодируются в буфер команд. Когда весь threadgroups, связанный с выполнением конца команды и все результаты, записаны в память, вычислить команда заканчивает выполнение. Из-за этого упорядочивания результаты вычислить команды доступны любым командам, закодированным после него в буфере команд.
Для окончания команд кодирования для вычислить кодера команды вызовите endEncoding метод MTLComputeCommandEncoder. После окончания предыдущего кодера команды можно создать новый кодер команды любого типа для кодирования дополнительных команд в буфер команд.
Пример кода: выполнение параллельных данным функций
Перечисление 6-1 показывает пример, создающий и использующий a MTLComputeCommandEncoder объект выполнить параллельные вычисления преобразования изображений на указанных данных. (Этот пример не показывает, как устройство, библиотека, очередь команды и объекты ресурса создаются и инициализируются.) Пример создает буфер команд и затем использует его для создания MTLComputeCommandEncoder объект. Следующий a MTLFunction объект создается, который представляет точку входа filter_main загруженный из MTLLibrary объект, показанный в Перечислении 6-2. Тогда функциональный объект используется для создания a MTLComputePipelineState объект вызывают filterState.
Вычислить функция выполняет преобразование изображений и работу фильтрации на изображении inputImage с результатами, возвращенными в outputImage. Сначала setTexture:atIndex: и setBuffer:offset:atIndex: методы присваивают текстуру и буферизуют объекты к индексам в указанных таблицах параметра. paramsBuffer указывает, что значения раньше выполняли преобразование изображений, и inputTableData указывает веса фильтра. Вычислить функция выполняется как 2D threadgroup размера 16 x 16 пикселей в каждой размерности. dispatchThreadgroups:threadsPerThreadgroup: метод ставит в очередь команду для диспетчеризации потоков, выполняющих вычислить функцию, и endEncoding метод завершается MTLComputeCommandEncoder. Наконец, commit метод MTLCommandBuffer заставляет команды выполняться как можно скорее.
Перечисление 6-1 , указывающее и выполняющее функцию в вычислить состоянии
id <MTLDevice> device; |
id <MTLLibrary> library; |
id <MTLCommandQueue> commandQueue; |
id <MTLTexture> inputImage; |
id <MTLTexture> outputImage; |
id <MTLTexture> inputTableData; |
id <MTLBuffer> paramsBuffer; |
// ... Create and initialize device, library, queue, resources |
// Obtain a new command buffer |
id <MTLCommandBuffer> commandBuffer = [commandQueue commandBuffer]; |
// Create a compute command encoder |
id <MTLComputeCommandEncoder> computeCE = [commandBuffer computeCommandEncoder]; |
NSError *errors; |
id <MTLFunction> func = [library newFunctionWithName:@"filter_main"]; |
id <MTLComputePipelineState> filterState |
= [device newComputePipelineStateWithFunction:func error:&errors]; |
[computeCE setComputePipelineState:filterState]; |
[computeCE setTexture:inputImage atIndex:0]; |
[computeCE setTexture:outputImage atIndex:1]; |
[computeCE setTexture:inputTableData atIndex:2]; |
[computeCE setBuffer:paramsBuffer offset:0 atIndex:0]; |
MTLSize threadsPerGroup = {16, 16, 1}; |
MTLSize numThreadgroups = {inputImage.width/threadsPerGroup.width, |
inputImage.height/threadsPerGroup.height, 1}; |
[computeCE dispatchThreadgroups:numThreadgroups |
threadsPerThreadgroup:threadsPerGroup]; |
[computeCE endEncoding]; |
// Commit the command buffer |
[commandBuffer commit]; |
Перечисление 6-2 показывает соответствующий код программы построения теней для предыдущего примера. (Функции read_and_transform и filter_table заполнители для определяемого пользователем кода).
Перечисление 6-2 , заштриховывающее язык, вычисляет объявление функции
kernel void filter_main(
texture2d<float,access::read> inputImage [[ texture(0) ]],
texture2d<float,access::write> outputImage [[ texture(1) ]],
uint2 gid [[ thread_position_in_grid ]],
texture2d<float,access::sample> table [[ texture(2) ]],
constant Parameters* params [[ buffer(0) ]]
)
{
float2 p0 = static_cast<float2>(gid);
float3x3 transform = params->transform;
float4 dims = params->dims;
float4 v0 = read_and_transform(inputImage, p0, transform);
float4 v1 = filter_table(v0,table, dims);
outputImage.write(v1,gid);
} |