Spec-Zone .ru
спецификации, руководства, описания, API
|
|
Spec-Zone .ru
спецификации, руководства, описания, API
|
Возможно использовать MySQL Cluster в мультиосновной репликации, включая круговую репликацию между многим MySQL Clusters.
Круговой пример репликации. В следующих немногих абзацах мы рассматриваем пример установки репликации, включающей три MySQL Clusters пронумерованный 1, 2, и 3, в который Кластер 1 действие как ведущее устройство репликации для Кластера 2, Кластер 2 действия как ведущее устройство для Кластера 3, и Кластера 3 действия как ведущее устройство для Кластера 1. У каждого кластера есть два узла SQL, с узлами SQL A и B, принадлежащий Кластеру 1, узлы SQL C и D, принадлежащий Кластеру 2, и узлы SQL E и F, принадлежащий Кластеру 3.
Круговая репликация, используя эти кластеры поддерживается, пока следующие условия встречаются:
Узлы SQL на всех ведущих устройствах и ведомых устройствах являются тем же самым
Все узлы SQL, действующие как ведущие устройства репликации и ведомые устройства,
запускаются, используя --log-slave-updates опция
Этот тип круговой установки репликации показывают в следующей схеме:
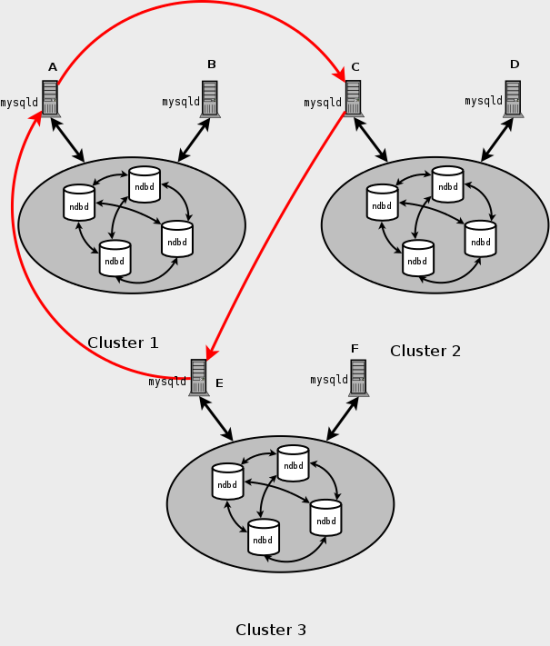
В этом сценарии узел SQL в Кластере 1 тиражируется к узлу SQL C в Кластере 2; узел SQL C тиражируется к узлу SQL E в Кластере 3; узел SQL E тиражируется к узлу SQL A. Другими словами строка репликации (обозначенный красными стрелками в схеме) непосредственно соединяет все узлы SQL, используемые в качестве ведущих устройств репликации и ведомых устройств.
Также возможно установить круговую репликацию таким способом, которым не все основные узлы SQL являются также ведомыми устройствами, как показано здесь:
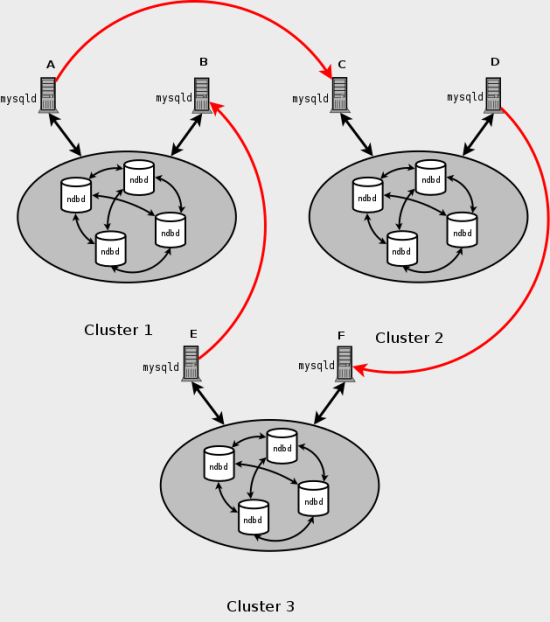
В этом случае различные узлы SQL в каждом кластере используются в качестве ведущих устройств репликации и
ведомых устройств. Однако, не следует запустить ни одно использование
узлов SQL --log-slave-updates.
Этот тип круговой схемы репликации MySQL Cluster, в котором строка репликации (снова обозначенный красными
стрелками в схеме) прерывиста, должен быть возможным, но нужно отметить, что это еще не было полностью
протестировано и должно поэтому все еще считаться экспериментальным.
Следует выполнить следующий оператор прежде, чем запустить круговую репликацию:
mysql> SET GLOBAL SLAVE_EXEC_MODE =
'IDEMPOTENT';
Это необходимо, чтобы подавить двойной ключ и другие ошибки, которые иначе повреждают круговую
репликацию в MySQL Cluster. IDEMPOTENT режим также требуется для мультиосновной
репликации при использовании MySQL Cluster. (Ошибка #31609)
См. slave_exec_mode,
для получения дополнительной информации.
Используя NDB-собственное резервное копирование и восстановление, чтобы инициализировать ведомый MySQL
Cluster. Устанавливая круговую репликацию, возможно
инициализировать ведомый кластер при использовании клиента управления BACKUP
команда на одном MySQL Cluster, чтобы создать резервное копирование и затем применение этого резервного
копирования на другом MySQL Cluster, используя ndb_restore. Однако, это автоматически не создает двоичный
файл, входит в систему второй узел SQL Кластера MySQL, действующий как ведомое устройство репликации. Чтобы
заставить двоичные журналы создаваться, Вы должны проблема a SHOW TABLES оператор на том узле SQL; это должно быть сделано до выполнения
START
SLAVE.
Это - известная проблема, которую мы намереваемся решить в будущем выпуске.
Мультиосновной failover пример. В этом разделе мы обсуждаем failover в мультиосновной установке репликации MySQL Cluster с тремя MySQL Clusters, имеющими ID сервера 1, 2, и 3. В этом сценарии Кластер 1 тиражируется к Кластерам 2 и 3; Кластер 2 также тиражируется, чтобы Кластеризироваться 3. Это отношение показывают здесь:
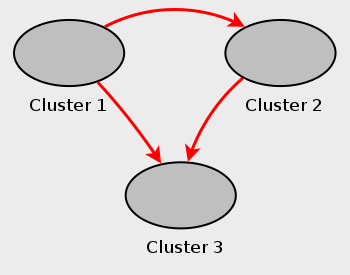
Другими словами данные тиражируются от Кластера 1, чтобы Кластеризироваться 3 через 2 различных маршрута: непосредственно, и посредством Кластера 2.
Не все принятие участия серверов MySQL в мультиосновной репликации должно действовать и как ведущее устройство и как ведомое устройство, и данный MySQL Cluster мог бы использовать различные узлы SQL для различных каналов репликации. Такой случай показывают здесь:
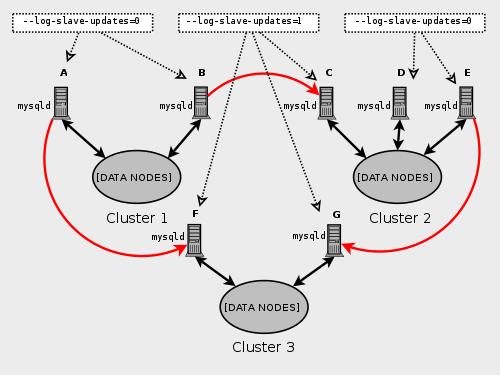
Серверы MySQL, действующие как ведомые устройства репликации, должны быть выполнены с --log-slave-updates опция. Какие процессы mysqld требуют, чтобы этот вариант также показался в предыдущей
схеме.
Используя --log-slave-updates опция не имеет никакого эффекта на серверы, не выполняемые
как ведомые устройства репликации.
Потребность в failover возникает, когда один из тиражирующихся кластеров теряет работоспособность. В этом примере мы рассматриваем случай, где Кластер 1 теряется к службе, и таким образом, Кластер 3 теряет 2 источника обновлений от Кластера 1. Поскольку репликация между MySQL Clusters является асинхронной, нет никакой гарантии, что Кластер 3 обновления, происходящие непосредственно из Кластера 1, более свеж чем полученные через Кластер 2. Можно обработать это, гарантируя что Кластер 3 выгоды до Кластера 2 относительно обновлений от Кластера 1. С точки зрения серверов MySQL это означает, что Вы должны тиражировать любые выдающиеся обновления от сервера MySQL C к серверу F.
На сервере C, выполните следующие запросы:
mysqlC> SELECT @latest:=MAX(epoch) -> FROM mysql.ndb_apply_status -> WHERE server_id=1;mysqlC> SELECT -> @file:=SUBSTRING_INDEX(File, '/', -1), -> @pos:=Position -> FROM mysql.ndb_binlog_index -> WHERE orig_epoch >= @latest -> AND orig_server_id = 1-> ORDER BY epoch ASC LIMIT 1;
Можно улучшить производительность этого запроса, и таким образом вероятно, ускорить failover
времена значительно, добавляя, что соответствующие индексируют к ndb_binlog_index таблица. См. Раздел
17.6.4, "MySQL Cluster Replication Schema и Tables", для получения дополнительной
информации.
Скопируйте по значениям для @file и @pos вручную от сервера C к серверу F (или имеют Ваше приложение,
выполняют эквивалент). Затем, на сервере F, выполните следующий CHANGE MASTER TO оператор:
mysqlF> CHANGE MASTER TO -> MASTER_HOST = 'serverC' -> MASTER_LOG_FILE='@file', -> MASTER_LOG_POS=@pos;
Как только это было сделано, Вы можете проблема a START
SLAVE оператор на сервере MySQL F, и любые недостающие обновления, происходящие из сервера B, будут
тиражированы в сервер F.
CHANGE MASTER TO оператор также поддерживает IGNORE_SERVER_IDS
опция, которая берет список разделенных запятой значений ID сервера и заставляет события, происходящие из
соответствующих серверов быть проигнорированными. Для получения дополнительной информации см. Раздел
13.4.2.1,"CHANGE MASTER TO Синтаксис", и Раздел
13.7.5.35,"SHOW SLAVE STATUS Синтаксис".