Spec-Zone .ru
спецификации, руководства, описания, API
|
|
Spec-Zone .ru
спецификации, руководства, описания, API
|
Репликация в MySQL Cluster использует много выделенных таблиц в mysql база данных
на каждом экземпляре MySQL Server, действующем как узел SQL и в тиражируемом кластере и в ведомом устройстве
репликации (является ли ведомое устройство единственным сервером или кластером). Эти таблицы составляются во
время процесса установки MySQL mysql_install_db сценарием, и включают таблицу для того,
чтобы хранить данные индексации двоичного журнала. Начиная с ndb_binlog_index
таблица локальна для каждого сервера MySQL и не участвует в кластеризации, это использует MyISAM
механизм хранения. Это означает, что должно быть создано отдельно на каждом mysqld, участвующем в основном кластере. (Однако, сам
двоичный журнал содержит обновления от всех серверов MySQL в кластере, который будет тиражирован.) Эта таблица
определяется следующим образом:
CREATE TABLE `ndb_binlog_index` ( `Position` BIGINT(20) UNSIGNED NOT NULL, `File` VARCHAR(255) NOT NULL, `epoch` BIGINT(20) UNSIGNED NOT NULL, `inserts` INT(10) UNSIGNED NOT NULL, `updates` INT(10) UNSIGNED NOT NULL, `deletes` INT(10) UNSIGNED NOT NULL, `schemaops` INT(10) UNSIGNED NOT NULL, `orig_server_id` INT(10) UNSIGNED NOT NULL, `orig_epoch` BIGINT(20) UNSIGNED NOT NULL, `gci` INT(10) UNSIGNED NOT NULL, `next_position` bigint(20) unsigned NOT NULL, `next_file` varchar(255) NOT NULL, PRIMARY KEY (`epoch`,`orig_server_id`,`orig_epoch`)) ENGINE=MyISAM DEFAULT CHARSET=latin1;
Размер этой таблицы зависит от числа эпох на двоичный файл журнала и числа двоичных файлов журнала. Число эпох
на binlog файл обычно зависит от количества двоичного журнала, сгенерированного на эпоху и размер двоичного
файла журнала с меньшими эпохами, приводящими к большему количеству эпох на файл. Это должно быть отмечено это,
когда --ndb-log-empty-epochs
опция ON, тогда даже пустые эпохи приводят к вставкам к ndb_binlog_index
файл, означая, что число записей на файл зависит от отрезка времени, что файл используется; то есть,
[number of epochs per file] = [time spent per file / TimeBetweenEpochs
Занятый MySQL Cluster пишет в двоичный журнал регулярно и по-видимому поворачивает двоичные файлы журнала более
быстро чем тихий. Это означает что "тихий" MySQL
Cluster с --ndb-log-empty-epochs=ON
может фактически иметь намного более высокое число ndb_binlog_index строки на файл
чем один с большим действием.
Когда mysqld запускается с
опция, orig_server_id и orig_epoch хранилище столбцов,
соответственно, ID сервера, на котором событие произошло и эпоха, в которой событие имело место на инициирующем
сервере, который полезен в установках репликации MySQL Cluster, нанимающих многократные ведущие устройства. SELECT оператор, привыкший к найти самую близкую binlog позицию к самой
высокой примененной эпохе на ведомом устройстве в мультиосновной установке (см. Раздел
17.6.10, "MySQL Cluster Replication: мультиосновная и Круговая Репликация"), использует эти
два столбца, которые не индексируются. Это может привести к проблемам производительности, пытаясь перестать
работать, так как запрос должен выполнить сканирование таблицы, особенно когда ведущее устройство работало с --ndb-log-empty-epochs=ON.
Можно улучшить мультиосновные failover времена, добавляя индексирование к этим столбцам, как показано здесь:
ALTER TABLE mysql.ndb_binlog_index ADD INDEX orig_lookup USING BTREE (orig_server_id, orig_epoch);
Добавление этого индексирует, не предоставляет преимущества, тиражируясь от единственного ведущего устройства к
единственному ведомому устройству, так как запрос, используемый, чтобы получить двоичную позицию журнала в таких
случаях, делает нет смысла orig_server_id или orig_epoch.
См. Раздел 17.6.8, "Реализовывая
Failover с MySQL Cluster Replication", для получения дополнительной информации об использовании next_position и next_file столбцы.
Следующие данные показывают отношение главного сервера репликации MySQL Cluster, его binlog потока инжектора, и
mysql.ndb_binlog_index таблица.
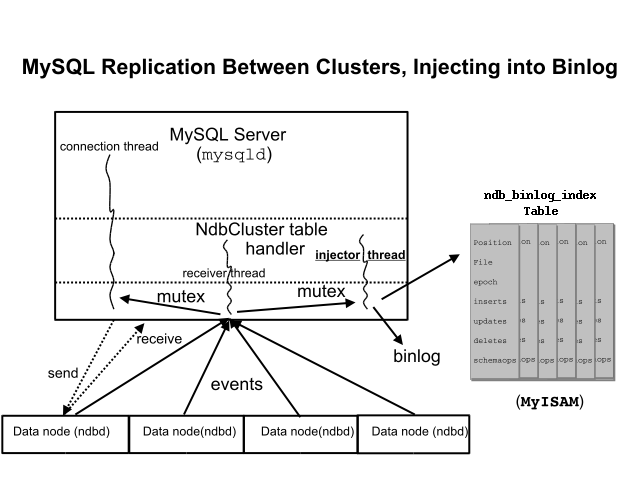
Дополнительная таблица, названная ndb_apply_status, используется, чтобы вести учет
операций, которые были тиражированы от ведущего устройства в ведомое устройство. В отличие от случая с ndb_binlog_index, данные в этой таблице не являются определенными для любого узла
SQL в (ведомом) кластере, и таким образом, ndb_apply_status может использовать
NDBCLUSTER механизм хранения, как показано здесь:
CREATE TABLE `ndb_apply_status` ( `server_id` INT(10) UNSIGNED NOT NULL, `epoch` BIGINT(20) UNSIGNED NOT NULL, `log_name` VARCHAR(255) CHARACTER SET latin1 COLLATE latin1_bin NOT NULL, `start_pos` BIGINT(20) UNSIGNED NOT NULL, `end_pos` BIGINT(20) UNSIGNED NOT NULL, PRIMARY KEY (`server_id`) USING HASH) ENGINE=NDBCLUSTER DEFAULT CHARSET=latin1;
Эта таблица заполняется только на ведомых устройствах; на ведущем устройстве, нет DataMemory выделяется этому. Так как эта таблица заполняется от данных,
происходящих на ведущем устройстве, нужно позволить тиражироваться; любая фильтрация репликации или двоичная
фильтрация журнала постановляют, что непреднамеренно препятствуют тому, чтобы ведомое устройство обновило ndb_apply_status или ведущее устройство от записи в двоичный журнал может
предотвратить репликацию между кластерами от работы должным образом. Для получения дополнительной информации о
потенциальных проблемах, являющихся результатом таких правил фильтрации, см. Репликацию
и двоичные правила фильтрации журнала с репликацией между MySQL Clusters.
ndb_binlog_index и ndb_apply_status таблицы
составляются в mysql база данных, потому что они не должны быть явно тиражированы
пользователем. Вмешательство пользователя обычно не требуется создать или поддержать ни одну из этих таблиц,
начиная с обоих ndb_binlog_index и ndb_apply_status
сохраняются NDB двоичный журнал (binlog) поток инжектора. Это сохраняет основной процесс
mysqld обновленным к изменениям выполняемый NDB механизм хранения. NDB поток инжектора binlog получает события
непосредственно из NDB механизм хранения. NDB инжектор ответственен за получение всех событий данных в пределах
кластера, и гарантирует, что все события, которые изменяются, вставляют, или удаляют данные, записываются в
ndb_binlog_index таблица. Ведомый поток ввода-вывода передает события от двоичного
журнала ведущего устройства до релейного журнала ведомого устройства.
Однако, желательно проверить на существование и целостность этих таблиц как начальный шаг в подготовке MySQL
Cluster для репликации. Возможно просмотреть данные события, записанные в двоичном журнале, запрашивая mysql.ndb_binlog_index представьте в виде таблицы непосредственно на ведущем
устройстве. Это может быть также быть выполненным, используя SHOW BINLOG EVENTS оператор или на ведущем устройстве репликации или на
ведомых серверах MySQL. (См. Раздел 13.7.5.3,"SHOW BINLOG EVENTS Синтаксис".)
Можно также получить полезную информацию из вывода SHOW ENGINE NDB STATUS.
ndb_schema таблица используется, чтобы отследить изменения схемы, произведенные в NDB таблицы. Это определяется как показано здесь:
CREATE TABLE ndb_schema ( `db` VARBINARY(63) NOT NULL, `name` VARBINARY(63) NOT NULL, `slock` BINARY(32) NOT NULL, `query` BLOB NOT NULL, `node_id` INT UNSIGNED NOT NULL, `epoch` BIGINT UNSIGNED NOT NULL, `id` INT UNSIGNED NOT NULL, `version` INT UNSIGNED NOT NULL, `type` INT UNSIGNED NOT NULL, PRIMARY KEY USING HASH (db,name)) ENGINE=NDB DEFAULT CHARSET=latin1;
В отличие от этих двух таблиц, ранее упомянутых в этом разделе, ndb_schema таблица
не видима любой к MySQL SHOW операторы, или в любом INFORMATION_SCHEMA
таблицы; однако, это может быть замечено в выводе ndb_show_tables, как показано здесь:
shell> ndb_show_tables -t 2id type state logging database schema name4 UserTable Online Yes mysql def ndb_apply_status5 UserTable Online Yes ndbworld def City6 UserTable Online Yes ndbworld def Country3 UserTable Online Yes mysql def NDB$BLOB_2_37 UserTable Online Yes ndbworld def CountryLanguage2 UserTable Online Yes mysql def ndb_schemaNDBT_ProgramExit: 0 - OK
Это также возможно к SELECT от этой таблицы в mysql и других клиентских приложениях MySQL, как показано здесь:
mysql> SELECT * FROM mysql.ndb_schema WHERE
name='City' \G*************************** 1. row *************************** db: ndbworld name: City slock: query: alter table City engine=ndbnode_id: 4 epoch: 0 id: 0version: 0 type: 71 row in set (0.00 sec)
Это может иногда быть полезно, отлаживая приложения.
Когда выполнение схемы изменяется на NDB таблицы, приложения должны ожидать до ALTER TABLE оператор возвратился в клиентском соединении MySQL, которое
сделало заявление прежде, чем попытаться использовать обновленное определение таблицы.
Если ndb_apply_status таблица или ndb_schema таблица
не существует на ведомом устройстве, ndb_restore воссоздает недостающую таблицу или таблицы
(Ошибка #14612).
Разрешение конфликтов для MySQL Cluster Replication требует присутствия дополнительного mysql.ndb_replication
таблица. В настоящий момент эта таблица должна быть составлена вручную. Для получения информации о том, как
сделать это, см. Раздел 17.6.11, "MySQL
Cluster Replication Conflict Resolution".