Spec-Zone .ru
спецификации, руководства, описания, API
|
|
Spec-Zone .ru
спецификации, руководства, описания, API
|
public final class String extends Object implements Serializable, Comparable<String>, CharSequence
String класс представляет символьные строки. Все строковые литералы в программах Java, такой как "abc", реализуются как экземпляры этого класса. Строки являются постоянными; их значения не могут быть изменены после того, как они создаются. Строковые буферы поддерживают изменчивые строки. Поскольку Строковые объекты являются неизменными, они могут быть совместно использованы. Например:
String str = "abc";
эквивалентно:
char data[] = {'a', 'b', 'c'};
String str = new String(data);
Вот еще некоторые примеры того, как могут использоваться строки:
System.out.println("abc");
String cde = "cde";
System.out.println("abc" + cde);
String c = "abc".substring(2,3);
String d = cde.substring(1, 2);
Класс String включает методы для того, чтобы исследовать отдельные символы последовательности, для того, чтобы сравнить строки, для того, чтобы искать строки, для того, чтобы извлечь подстроки, и для того, чтобы создать копию строки со всеми символами, преобразованными в верхний регистр или в нижний регистр. Отображение случая основано на версии Стандарта Unicode, определенной Character класс.
Язык Java оказывает специальную поддержку для оператора конкатенации строк (+), и для преобразования других объектов к строкам. Конкатенация строк реализуется через StringBuilder(или StringBuffer) класс и append метод. Преобразования строк реализуются через метод toString, определенный Object и наследованный всеми классами в Java. Для дополнительной информации о конкатенации строк и преобразовании, см. Гусенка, Радость, и Стила, Спецификацию языка Java.
Если не указано иное, передача параметра null конструктору или методу в этом классе вызовет a NullPointerException быть брошенным.
A String представляет строку в формате UTF-16, в котором дополнительные символы представляются суррогатными парами (см. Представления Символа Unicode раздела в Character класс для получения дополнительной информации). Индексные значения обращаются к char элементы кода, таким образом, дополнительный символ использует две позиции в a String.
String класс обеспечивает методы для того, чтобы они имели дело с кодовыми точками Unicode (то есть, символы), в дополнение к тем для того, чтобы иметь дело с элементами кода Unicode (то есть, char значения).
Object.toString(), StringBuffer, StringBuilder, Charset, Сериализированная Форма| Модификатор и Тип | Поле и Описание |
|---|---|
static Comparator<String> |
CASE_INSENSITIVE_ORDER
Компаратор, который упорядочивает
String объекты как compareToIgnoreCase. |
| Конструктор и Описание |
|---|
String()
Инициализирует недавно создаваемый
String возразите так, чтобы это представило пустую символьную последовательность. |
String(byte[] bytes)
Создает новое
String декодируя указанный массив байтов, используя набор символов платформы по умолчанию. |
String(byte[] bytes, Charset charset)
Создает новое
String декодируя указанный массив байтов, используя указанный набор символов. |
String(byte[] ascii, int hibyte)
Осуждаемый.
Этот метод должным образом не преобразовывает байты в символы. С JDK 1.1, привилегированный способ сделать это через
String конструкторы, которые берут a Charset, имя набора символов, или то использование набор символов платформы по умолчанию. |
String(byte[] bytes, int offset, int length)
Создает новое
String декодируя указанный подмассив байтов, используя набор символов платформы по умолчанию. |
String(byte[] bytes, int offset, int length, Charset charset)
Создает новое
String декодируя указанный подмассив байтов, используя указанный набор символов. |
String(byte[] ascii, int hibyte, int offset, int count)
Осуждаемый.
Этот метод должным образом не преобразовывает байты в символы. С JDK 1.1, привилегированный способ сделать это через
String конструкторы, которые берут a Charset, имя набора символов, или то использование набор символов платформы по умолчанию. |
String(byte[] bytes, int offset, int length, String charsetName)
Создает новое
String декодируя указанный подмассив байтов, используя указанный набор символов. |
String(byte[] bytes, String charsetName)
Создает новое
String декодируя указанный массив байтов, используя указанный набор символов. |
String(char[] value)
Выделяет новое
String так, чтобы это представило последовательность символов, в настоящий момент содержавшихся в символьном параметре массива. |
String(char[] value, int offset, int count)
Выделяет новое
String это содержит символы от подмассива символьного параметра массива. |
String(int[] codePoints, int offset, int count)
Выделяет новое
String это содержит символы от подмассива параметра массива кодовой точки Unicode. |
String(String original)
Инициализирует недавно создаваемый
String возразите так, чтобы это представило ту же самую последовательность символов как параметр; другими словами недавно создаваемая строка является копией строки параметра. |
String(StringBuffer buffer)
Выделяет новую строку, которая содержит последовательность символов, в настоящий момент содержавшихся в строковом буферном параметре.
|
String(StringBuilder builder)
Выделяет новую строку, которая содержит последовательность символов, в настоящий момент содержавшихся в строковом разработчике параметр.
|
| Модификатор и Тип | Метод и Описание |
|---|---|
char |
charAt(int index)
Возвраты
char значение по указанному индексу. |
int |
codePointAt(int index)
Возвращает символ (кодовая точка Unicode) по указанному индексу.
|
int |
codePointBefore(int index)
Возвращает символ (кодовая точка Unicode) перед указанным индексом.
|
int |
codePointCount(int beginIndex, int endIndex)
Возвращает число кодовых точек Unicode в указанном текстовом диапазоне этого
String. |
int |
compareTo(String anotherString)
Сравнивает две строки лексикографически.
|
int |
compareToIgnoreCase(String str)
Сравнивает две строки лексикографически, игнорируя различия в случае.
|
Строка |
concat(String str)
Связывает указанную строку до конца этой строки.
|
boolean |
contains(CharSequence s)
Возвращает true, если и только если эта строка содержит указанную последовательность значений случайной работы.
|
boolean |
contentEquals(CharSequence cs)
Сравнивает эту строку с указанным
CharSequence. |
boolean |
contentEquals(StringBuffer sb)
Сравнивает эту строку с указанным
StringBuffer. |
static String |
copyValueOf(char[] data)
Возвращает Строку, которая представляет символьную последовательность в определенном массиве.
|
static String |
copyValueOf(char[] data, int offset, int count)
Возвращает Строку, которая представляет символьную последовательность в определенном массиве.
|
boolean |
endsWith(String suffix)
Тесты, если эта строка заканчивается указанным суффиксом.
|
boolean |
equals(Object anObject)
Сравнивает эту строку с указанным объектом.
|
boolean |
equalsIgnoreCase(String anotherString)
Сравнивает это
String другому String, игнорирование соображений случая. |
static String |
format(Locale l, String format, Object... args)
Возвращает отформатированную строку, используя указанную локаль, строку формата, и параметры.
|
static String |
format(String format, Object... args)
Возвращает отформатированную строку, используя указанную строку формата и параметры.
|
byte[] |
getBytes()
Кодирует это
String в последовательность байтов, используя набор символов платформы по умолчанию, храня результат в новый байтовый массив. |
byte[] |
getBytes(Charset charset)
Кодирует это
String в последовательность байтов, используя данный набор символов, храня результат в новый байтовый массив. |
void |
getBytes(int srcBegin, int srcEnd, byte[] dst, int dstBegin)
Осуждаемый.
Этот метод должным образом не преобразовывает символы в байты. С JDK 1.1, привилегированный способ сделать это через
getBytes() метод, который использует набор символов платформы по умолчанию. |
byte[] |
getBytes(String charsetName)
Кодирует это
String в последовательность байтов, используя именованный набор символов, храня результат в новый байтовый массив. |
void |
getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin)
Символы копий от этой строки в целевой массив символа.
|
int |
hashCode()
Возвращает хэш-код для этой строки.
|
int |
indexOf(int ch)
Возвращает индекс в пределах этой строки первого возникновения указанного символа.
|
int |
indexOf(int ch, int fromIndex)
Возвращает индекс в пределах этой строки первого возникновения указанного символа, запуская поиск по указанному индексу.
|
int |
indexOf(String str)
Возвращает индекс в пределах этой строки первого возникновения указанной подстроки.
|
int |
indexOf(String str, int fromIndex)
Возвращает индекс в пределах этой строки первого возникновения указанной подстроки, запускающейся по указанному индексу.
|
Строка |
intern()
Возвращает каноническое представление для строкового объекта.
|
boolean |
isEmpty()
Возвраты true, если, и только если,
length() 0. |
int |
lastIndexOf(int ch)
Возвращает индекс в пределах этой строки последнего вхождения указанного символа.
|
int |
lastIndexOf(int ch, int fromIndex)
Возвращает индекс в пределах этой строки последнего вхождения указанного символа, ища назад запускающийся по указанному индексу.
|
int |
lastIndexOf(String str)
Возвращает индекс в пределах этой строки последнего вхождения указанной подстроки.
|
int |
lastIndexOf(String str, int fromIndex)
Возвращает индекс в пределах этой строки последнего вхождения указанной подстроки, ища назад запускающийся по указанному индексу.
|
int |
length()
Возвращает длину этой строки.
|
boolean |
matches(String regex)
Говорит, соответствует ли эта строка данное регулярное выражение.
|
int |
offsetByCodePoints(int index, int codePointOffset)
Возвращает индекс в пределах этого
String это смещается от данного index codePointOffset кодовые точки. |
boolean |
regionMatches(boolean ignoreCase, int toffset, String other, int ooffset, int len)
Тесты, если две строковых области равны.
|
boolean |
regionMatches(int toffset, String other, int ooffset, int len)
Тесты, если две строковых области равны.
|
Строка |
replace(char oldChar, char newChar)
Возвращает новую строку, следующую из замены всех возникновений
oldChar в этой строке с newChar. |
Строка |
replace(CharSequence target, CharSequence replacement)
Замены каждая подстрока этой строки, которая соответствует литеральную целевую последовательность с указанной литеральной заменяющей последовательностью.
|
Строка |
replaceAll(String regex, String replacement)
Замены каждая подстрока этой строки, которая соответствует данное регулярное выражение с данной заменой.
|
Строка |
replaceFirst(String regex, String replacement)
Заменяет первую подстроку этой строки, которая соответствует данное регулярное выражение с данной заменой.
|
Строка[] |
split(String regex)
Разделения эта строка вокруг соответствий данного регулярного выражения.
|
Строка[] |
split(String regex, int limit)
Разделения эта строка вокруг соответствий данного регулярного выражения.
|
boolean |
startsWith(String prefix)
Тесты, если эта строка запускается с указанного префикса.
|
boolean |
startsWith(String prefix, int toffset)
Тесты, если подстрока этой строки, начинающейся по указанному индексу, запускается с указанного префикса.
|
CharSequence |
subSequence(int beginIndex, int endIndex)
Возвращает новую символьную последовательность, которая является подпоследовательностью этой последовательности.
|
Строка |
substring(int beginIndex)
Возвращает новую строку, которая является подстрокой этой строки.
|
Строка |
substring(int beginIndex, int endIndex)
Возвращает новую строку, которая является подстрокой этой строки.
|
char[] |
toCharArray()
Преобразовывает эту строку в новый символьный массив.
|
Строка |
toLowerCase()
Преобразовывает все символы в этом
String к нижнему регистру, используя правила локали по умолчанию. |
Строка |
toLowerCase(Locale locale)
Преобразовывает все символы в этом
String к нижнему регистру, используя правила данного Locale. |
Строка |
toString()
Этот объект (который уже является строкой!) самостоятельно возвращается.
|
Строка |
toUpperCase()
Преобразовывает все символы в этом
String к верхнему регистру, используя правила локали по умолчанию. |
Строка |
toUpperCase(Locale locale)
Преобразовывает все символы в этом
String к верхнему регистру, используя правила данного Locale. |
Строка |
trim()
Возвращает копию строки, с продвижением и запаздывающим опущенным пробелом.
|
static String |
valueOf(boolean b)
Возвращает строковое представление
boolean параметр. |
static String |
valueOf(char c)
Возвращает строковое представление
char параметр. |
static String |
valueOf(char[] data)
Возвращает строковое представление
char параметр массива. |
static String |
valueOf(char[] data, int offset, int count)
Возвращает строковое представление определенного подмассива
char параметр массива. |
static String |
valueOf(double d)
Возвращает строковое представление
double параметр. |
static String |
valueOf(float f)
Возвращает строковое представление
float параметр. |
static String |
valueOf(int i)
Возвращает строковое представление
int параметр. |
static String |
valueOf(long l)
Возвращает строковое представление
long параметр. |
static String |
valueOf(Object obj)
Возвращает строковое представление
Object параметр. |
public static final Comparator<String> CASE_INSENSITIVE_ORDER
String объекты как compareToIgnoreCase. Этот компаратор сериализуем. Отметьте, что этот Компаратор не принимает локаль во внимание, и приведет к неудовлетворительному упорядочиванию для определенных локалей. java.text пакет обеспечивает Сортировально-подборочные машины, чтобы позволить чувствительное к локали упорядочивание.
Collator.compare(String, String)public String()
String возразите так, чтобы это представило пустую символьную последовательность. Отметьте, что использование этого конструктора является ненужным, так как Строки являются неизменными.public String(String original)
String возразите так, чтобы это представило ту же самую последовательность символов как параметр; другими словами недавно создаваемая строка является копией строки параметра. Если явная копия original необходим, использование этого конструктора является ненужным, так как Строки являются неизменными.original - A Stringpublic String(char[] value)
String так, чтобы это представило последовательность символов, в настоящий момент содержавшихся в символьном параметре массива. Содержание символьного массива копируется; последующая модификация символьного массива не влияет на недавно создаваемую строку.value - Начальное значение строкиpublic String(char[] value,
int offset,
int count)
String это содержит символы от подмассива символьного параметра массива. offset параметром является индекс первого символа подмассива и count параметр определяет длину подмассива. Содержание подмассива копируется; последующая модификация символьного массива не влияет на недавно создаваемую строку.value - Массив, который является источником символовoffset - Начальное смещениеcount - ДлинаIndexOutOfBoundsException - Если offset и count параметры индексируют символы вне границ value массивpublic String(int[] codePoints,
int offset,
int count)
String это содержит символы от подмассива параметра массива кодовой точки Unicode. offset параметром является индекс первой кодовой точки подмассива и count параметр определяет длину подмассива. Содержание подмассива преобразовывается в chars; последующая модификация int массив не влияет на недавно создаваемую строку.codePoints - Массив, который является источником кодовых точек Unicodeoffset - Начальное смещениеcount - ДлинаIllegalArgumentException - Если какая-либо недопустимая кодовая точка Unicode находится в codePointsIndexOutOfBoundsException - Если offset и count параметры индексируют символы вне границ codePoints массив@Deprecated public String(byte[] ascii, int hibyte, int offset, int count)
String конструкторы, которые берут a Charset, имя набора символов, или то использование набор символов платформы по умолчанию.String созданный из подмассива массива 8-разрядных целочисленных значений. offset параметром является индекс первого байта подмассива, и count параметр определяет длину подмассива.
Каждый byte в подмассиве преобразовывается в a char как определено в методе выше.
ascii - Байты, которые будут преобразованы в символыhibyte - Лучшие 8 битов каждого 16-разрядного элемента кода Unicodeoffset - Начальное смещениеcount - ДлинаIndexOutOfBoundsException - Если offset или count параметр недопустимString(byte[], int), String(byte[], int, int, java.lang.String), String(byte[], int, int, java.nio.charset.Charset), String(byte[], int, int), String(byte[], java.lang.String), String(byte[], java.nio.charset.Charset), String(byte[])@Deprecated public String(byte[] ascii, int hibyte)
String конструкторы, которые берут a Charset, имя набора символов, или то использование набор символов платформы по умолчанию.String содержа символы создается из массива 8-разрядных целочисленных значений. Каждый символ cin получающаяся строка создается из соответствующего компонента b в байтовом массиве так, что:
c == (char)(((hibyte & 0xff) << 8)
| (b & 0xff))
ascii - Байты, которые будут преобразованы в символыhibyte - Лучшие 8 битов каждого 16-разрядного элемента кода UnicodeString(byte[], int, int, java.lang.String), String(byte[], int, int, java.nio.charset.Charset), String(byte[], int, int), String(byte[], java.lang.String), String(byte[], java.nio.charset.Charset), String(byte[])public String(byte[] bytes,
int offset,
int length,
String charsetName)
throws UnsupportedEncodingException
String декодируя указанный подмассив байтов, используя указанный набор символов. Длина нового String функция набора символов, и следовательно, возможно, не равна длине подмассива. Поведение этого конструктора, когда данные байты не допустимы в данном наборе символов, является неуказанным. CharsetDecoder класс должен использоваться, когда больше управления процессом декодирования требуется.
bytes - Байты, которые будут декодироваться в символыoffset - Индекс первого байта, который будет декодироватьlength - Число байтов, чтобы декодироватьcharsetName - Имя поддерживаемого набора символовUnsupportedEncodingException - Если именованный набор символов не поддерживаетсяIndexOutOfBoundsException - Если offset и length параметры индексируют символы вне границ bytes массивpublic String(byte[] bytes,
int offset,
int length,
Charset charset)
String декодируя указанный подмассив байтов, используя указанный набор символов. Длина нового String функция набора символов, и следовательно, возможно, не равна длине подмассива. Этот метод всегда заменяет уродливый ввод и неотображаемо-символьные последовательности с заменяющей строкой этого набора символов по умолчанию. CharsetDecoder класс должен использоваться, когда больше управления процессом декодирования требуется.
bytes - Байты, которые будут декодироваться в символыoffset - Индекс первого байта, который будет декодироватьlength - Число байтов, чтобы декодироватьcharset - Набор символов, который будет использоваться, чтобы декодировать bytesIndexOutOfBoundsException - Если offset и length параметры индексируют символы вне границ bytes массивpublic String(byte[] bytes,
String charsetName)
throws UnsupportedEncodingException
String декодируя указанный массив байтов, используя указанный набор символов. Длина нового String функция набора символов, и следовательно, возможно, не равна длине байтового массива. Поведение этого конструктора, когда данные байты не допустимы в данном наборе символов, является неуказанным. CharsetDecoder класс должен использоваться, когда больше управления процессом декодирования требуется.
bytes - Байты, которые будут декодироваться в символыcharsetName - Имя поддерживаемого набора символовUnsupportedEncodingException - Если именованный набор символов не поддерживаетсяpublic String(byte[] bytes,
Charset charset)
String декодируя указанный массив байтов, используя указанный набор символов. Длина нового String функция набора символов, и следовательно, возможно, не равна длине байтового массива. Этот метод всегда заменяет уродливый ввод и неотображаемо-символьные последовательности с заменяющей строкой этого набора символов по умолчанию. CharsetDecoder класс должен использоваться, когда больше управления процессом декодирования требуется.
bytes - Байты, которые будут декодироваться в символыcharset - Набор символов, который будет использоваться, чтобы декодировать bytespublic String(byte[] bytes,
int offset,
int length)
String декодируя указанный подмассив байтов, используя набор символов платформы по умолчанию. Длина нового String функция набора символов, и следовательно, возможно, не равна длине подмассива. Поведение этого конструктора, когда данные байты не допустимы в наборе символов по умолчанию, является неуказанным. CharsetDecoder класс должен использоваться, когда больше управления процессом декодирования требуется.
bytes - Байты, которые будут декодироваться в символыoffset - Индекс первого байта, который будет декодироватьlength - Число байтов, чтобы декодироватьIndexOutOfBoundsException - Если offset и length параметры индексируют символы вне границ bytes массивpublic String(byte[] bytes)
String декодируя указанный массив байтов, используя набор символов платформы по умолчанию. Длина нового String функция набора символов, и следовательно, возможно, не равна длине байтового массива. Поведение этого конструктора, когда данные байты не допустимы в наборе символов по умолчанию, является неуказанным. CharsetDecoder класс должен использоваться, когда больше управления процессом декодирования требуется.
bytes - Байты, которые будут декодироваться в символыpublic String(StringBuffer buffer)
buffer - A StringBufferpublic String(StringBuilder builder)
Этому конструктору предоставляют, чтобы ослабить миграцию к StringBuilder. Получение строки от строкового разработчика через toString метод, вероятно, будет работать быстрее и обычно предпочитается.
builder - A StringBuilderpublic int length()
length в интерфейсе CharSequencepublic boolean isEmpty()
length() 0.length() 0, иначе falsepublic char charAt(int index)
char значение по указанному индексу. Индекс располагается от 0 к length() - 1. Первое char значение последовательности по индексу 0, следующее по индексу 1, и так далее, что касается индексации массива. Если char значение, определенное индексом, является заместителем, суррогатное значение возвращается.
charAt в интерфейсе CharSequenceindex - индекс char значение.char значение по указанному индексу этой строки. Первое char значение по индексу 0.IndexOutOfBoundsException - если index параметр отрицателен или не меньше чем длина этой строки.public int codePointAt(int index)
char значения (элементы кода Unicode) и диапазоны от 0 к length() - 1. Если char значение, определенное по данному индексу, находится в высоко-суррогатном диапазоне, следующий индекс является меньше чем длина этого String, и char значение по следующему индексу находится в диапазоне низкого заместителя, тогда дополнительная кодовая точка, соответствующая этой суррогатной паре, возвращается. Иначе, char значение по данному индексу возвращается.
index - индекс к char значенияindexIndexOutOfBoundsException - если index параметр отрицателен или не меньше чем длина этой строки.public int codePointBefore(int index)
char значения (элементы кода Unicode) и диапазоны от 1 к length. Если char значение в (index - 1) находится в диапазоне низкого заместителя, (index - 2) не отрицательно, и char значение в (index - 2) находится в высоко-суррогатном диапазоне, тогда дополнительное значение кодовой точки суррогатной пары возвращается. Если char значение в index - 1 непарный низкий заместитель или высокий заместитель, суррогатное значение возвращается.
index - индекс после кодовой точки, которая должна быть возвращенаIndexOutOfBoundsException - если index параметр - меньше чем 1 или больше чем длина этой строки.public int codePointCount(int beginIndex,
int endIndex)
String. Текстовый диапазон начинается в указанном beginIndex и расширяется на char по индексу endIndex - 1. Таким образом длина (в chars) из текста диапазон endIndex-beginIndex. Непарные заместители в пределах текста располагаются количество как одна кодовая точка каждый.beginIndex - индекс к первому char из текстового диапазона.endIndex - индекс после последнего char из текстового диапазона.IndexOutOfBoundsException - если beginIndex отрицательно, или endIndex больше чем длина этого String, или beginIndex больше чем endIndex.public int offsetByCodePoints(int index,
int codePointOffset)
String это смещается от данного index codePointOffset кодовые точки. Непарные заместители в пределах текстового диапазона, данного index и codePointOffset рассчитайте как одна кодовая точка каждый.index - индекс, который будет смещенcodePointOffset - смещение в кодовых точкахStringIndexOutOfBoundsException - если index отрицательно или больше тогда длина этого String, или если codePointOffset положительно и подстрока, запускающаяся с index имеет меньше чем codePointOffset кодовые точки, или если codePointOffset отрицательно и подстрока прежде index имеет меньше чем абсолютное значение codePointOffset кодовые точки.public void getChars(int srcBegin,
int srcEnd,
char[] dst,
int dstBegin)
Первый символ, который будет скопирован, по индексу srcBegin; последний знак, который будет скопирован, по индексу srcEnd-1 (таким образом общее количество символов, которые будут скопированы, srcEnd-srcBegin). Символы копируются в подмассив dst запуск по индексу dstBegin и окончание по индексу:
dstbegin + (srcEnd-srcBegin) - 1
srcBegin - индекс первого символа в строке, который скопирует.srcEnd - индекс после последнего знака в строке, чтобы скопировать.dst - целевой массив.dstBegin - запуск смещается в целевом массиве.IndexOutOfBoundsException - Если какое-либо следующее является истиной: srcBegin отрицательно. srcBegin больше чем srcEnd
srcEnd больше чем длина этой строки dstBegin отрицательно dstBegin+(srcEnd-srcBegin) больше чем dst.length@Deprecated public void getBytes(int srcBegin, int srcEnd, byte[] dst, int dstBegin)
getBytes() метод, который использует набор символов платформы по умолчанию. Первый символ, который будет скопирован, по индексу srcBegin; последний знак, который будет скопирован, по индексу srcEnd-1. Общее количество символов, которые будут скопированы, srcEnd-srcBegin. Символы, преобразованные в байты, копируются в подмассив dst запуск по индексу dstBegin и окончание по индексу:
dstbegin + (srcEnd-srcBegin) - 1
srcBegin - Индекс первого символа в строке, который скопируетsrcEnd - Индекс после последнего знака в строке, чтобы скопироватьdst - Целевой массивdstBegin - Запуск смещается в целевом массивеIndexOutOfBoundsException - Если какое-либо следующее является истиной: srcBegin отрицательно srcBegin больше чем srcEnd
srcEnd больше чем длина этой Строки dstBegin отрицательно dstBegin+(srcEnd-srcBegin) больше чем dst.length
public byte[] getBytes(String charsetName) throws UnsupportedEncodingException
String в последовательность байтов, используя именованный набор символов, храня результат в новый байтовый массив. Поведение этого метода, когда эта строка не может быть закодирована в данном наборе символов, является неуказанным. CharsetEncoder класс должен использоваться, когда больше управления процессом кодирования требуется.
charsetName - Имя поддерживаемого набора символовUnsupportedEncodingException - Если именованный набор символов не поддерживаетсяpublic byte[] getBytes(Charset charset)
String в последовательность байтов, используя данный набор символов, храня результат в новый байтовый массив. Этот метод всегда заменяет уродливый ввод и неотображаемо-символьные последовательности с заменяющим байтовым массивом этого набора символов по умолчанию. CharsetEncoder класс должен использоваться, когда больше управления процессом кодирования требуется.
charset - Набор символов, который будет использоваться, чтобы закодировать Stringpublic byte[] getBytes()
String в последовательность байтов, используя набор символов платформы по умолчанию, храня результат в новый байтовый массив. Поведение этого метода, когда эта строка не может быть закодирована в наборе символов по умолчанию, является неуказанным. CharsetEncoder класс должен использоваться, когда больше управления процессом кодирования требуется.
public boolean equals(Object anObject)
true если и только если параметр не null и a String объект, который представляет ту же самую последовательность символов как этот объект.equals в классе ObjectanObject - Объект сравнить это String противtrue если данный объект представляет a String эквивалентный этой строке, false иначеcompareTo(String), equalsIgnoreCase(String)public boolean contentEquals(StringBuffer sb)
StringBuffer. Результат true если и только если это String представляет ту же самую последовательность символов как указанное StringBuffer.sb - StringBuffer сравнить это String противtrue если это String представляет ту же самую последовательность символов как указанное StringBuffer, false иначеpublic boolean contentEquals(CharSequence cs)
CharSequence. Результат true если и только если это String представляет ту же самую последовательность значений случайной работы как указанная последовательность.cs - Последовательность, чтобы сравнить это String противtrue если это String представляет ту же самую последовательность значений случайной работы как указанная последовательность, false иначеpublic boolean equalsIgnoreCase(String anotherString)
String другому String, игнорирование соображений случая. Две строки считают равным случаем игнорирования, если они имеют ту же самую длину, и соответствующие символы в двух строках являются равным случаем игнорирования. Два символа c1 и c2 считаются тем же самым игнорирующим регистром, если по крайней мере одно из следующего является истиной:
== оператор) Character.toUpperCase(char) к каждому символу приводит к тому же самому результату Character.toLowerCase(char) к каждому символу приводит к тому же самому результату anotherString - String сравнить это String противtrue если параметр не null и это представляет эквивалент String игнорирование регистра; false иначеequals(Object)public int compareTo(String anotherString)
String объект сравнивается лексикографически с символьной последовательностью, представленной строкой параметра. Результатом является отрицательное целое число если это String объект лексикографически предшествует строке параметра. Результатом является положительное целое число если это String объект лексикографически следует за строкой параметра. Результатом является нуль, если строки равны; compareTo возвраты 0 точно, когда equals(Object) метод возвратился бы true. Это - определение лексикографического упорядочивания. Если две строки отличаются, то у или их есть различные символы по некоторому индексу, который является допустимым индексом для обеих строк, или их длины отличаются, или оба. Если у них есть различные символы в одной или более индексных позициях, k, которому позволяют, являются самыми маленькими такой индекс; тогда строка, у символа которой в позиции k есть меньшее значение, как определено при использовании <оператор, лексикографически предшествует другой строке. В этом случае, compareTo возвращает различие двух символьных значений в позиции k в этих двух представляют в виде строки - то есть, значение:
Если нет никакой индексной позиции, в которой они отличаются, то более короткая строка лексикографически предшествует более длинной строке. В этом случае,this.charAt(k)-anotherString.charAt(k)
compareTo возвращает различие длин строк - то есть, значение: this.length()-anotherString.length()
compareTo в интерфейсе Comparable<String>anotherString - String быть сравненным.0 если строка параметра равна этой строке; значение меньше чем 0 если эта строка является лексикографически меньше чем строковый параметр; и значение, больше чем 0 если эта строка лексикографически больше чем строковый параметр.public int compareToIgnoreCase(String str)
compareTo с нормализованными версиями строк, где различия в случае были устранены, вызывая Character.toLowerCase(Character.toUpperCase(character)) на каждом символе. Отметьте, что этот метод не принимает локаль во внимание, и приведет к неудовлетворительному упорядочиванию для определенных локалей. java.text пакет обеспечивает сортировально-подборочные машины, чтобы позволить чувствительное к локали упорядочивание.
str - String быть сравненным.Collator.compare(String, String)public boolean regionMatches(int toffset,
String other,
int ooffset,
int len)
Подстрока этого объекта String - по сравнению с подстрокой параметра другой. Результатом является истина, если эти подстроки представляют идентичные символьные последовательности. Подстрока этого объекта String, который будет сравнен, начинает по индексу toffset и имеет длину len. Подстрока другого, чтобы быть сравненной начинает по индексу ooffset и имеет длину len. Результатом является false, если и только если по крайней мере одно из следующего является истиной:
toffset - запускающееся смещение подобласти в этой строке.other - строковый параметр.ooffset - запускающееся смещение подобласти в строковом параметре.len - число символов, чтобы сравниться.true если указанная подобласть этой строки точно соответствует указанную подобласть строкового параметра; false иначе.public boolean regionMatches(boolean ignoreCase,
int toffset,
String other,
int ooffset,
int len)
Подстрокой этого объекта String является по сравнению с подстрокой параметра other. Результатом является true, если эти подстроки представляют символьные последовательности, которые являются тем же самым, игнорируя регистр, если и только если ignoreCase является истиной. Подстрока этого объекта String, который будет сравнен, начинает по индексу toffset и имеет длину len. Подстрока other, который будет сравнен, начинает по индексу ooffset и имеет длину len. Результатом является false, если и только если по крайней мере одно из следующего является истиной:
this.charAt(toffset+k) != other.charAt(ooffset+k)
Character.toLowerCase(this.charAt(toffset+k)) !=
Character.toLowerCase(other.charAt(ooffset+k))
Character.toUpperCase(this.charAt(toffset+k)) !=
Character.toUpperCase(other.charAt(ooffset+k))
ignoreCase - если true, игнорируйте регистр, сравнивая символы.toffset - запускающееся смещение подобласти в этой строке.other - строковый параметр.ooffset - запускающееся смещение подобласти в строковом параметре.len - число символов, чтобы сравниться.true если указанная подобласть этой строки соответствует указанную подобласть строкового параметра; false иначе. Точно ли соответствие, или нечувствительный к регистру зависит от ignoreCase параметр.public boolean startsWith(String prefix, int toffset)
prefix - префикс.toffset - где начать смотреть в этой строке.true если символьная последовательность, представленная параметром, является префиксом подстроки этого объекта, запускающегося по индексу toffset; false иначе. Результат false если toffset отрицательно или больше чем длина этого String объект; иначе результатом является то же самое как результат выражения
this.substring(toffset).startsWith(prefix)
public boolean startsWith(String prefix)
prefix - префикс.true если символьная последовательность, представленная параметром, является префиксом символьной последовательности, представленной этой строкой; false иначе. Отметьте также это true будет возвращен, если параметр будет пустой строкой или будет равен этому String возразите как определено equals(Object) метод.public boolean endsWith(String suffix)
suffix - суффикс.true если символьная последовательность, представленная параметром, является суффиксом символьной последовательности, представленной этим объектом; false иначе. Отметьте, что результат будет true если параметр является пустой строкой или равен этому String возразите как определено equals(Object) метод.public int hashCode()
String объект вычисляется как использованиеs[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
int арифметика, где s[i] ith символ строки, n длина строки, и ^ указывает на возведение в степень. (Значение хэш-функции пустой строки является нулем.)hashCode в классе ObjectObject.equals(java.lang.Object), System.identityHashCode(java.lang.Object)public int indexOf(int ch)
ch происходит в символьной последовательности, представленной этим String объект, тогда индекс (в элементах кода Unicode) первого такое возникновение возвращается. Для значений ch в диапазоне от 0 до 0xFFFF (включительно), это - самое маленькое значение k так, что: истина. Для других значенийthis.charAt(k) == ch
ch, это - самое маленькое значение k так, что: истина. В любом случае, если никакой такой символ не происходит в этой строке, тоthis.codePointAt(k) == ch
-1 возвращается.ch - символ (кодовая точка Unicode).-1 если символ не происходит.public int indexOf(int ch,
int fromIndex)
Если символ со значением ch происходит в символьной последовательности, представленной этим String объект по индексу, не меньшему чем fromIndex, тогда индекс первого такое возникновение возвращается. Для значений ch в диапазоне от 0 до 0xFFFF (включительно), это - самое маленькое значение k так, что:
истина. Для других значений(this.charAt(k) == ch) && (k >= fromIndex)
ch, это - самое маленькое значение k так, что: истина. Или в случае, если никакой такой символ не происходит в этой строке в или после позиции(this.codePointAt(k) == ch) && (k >= fromIndex)
fromIndex, тогда -1 возвращается. Нет никакого ограничения на значение fromIndex. Если это отрицательно, это имеет тот же самый эффект, как будто это был нуль: эта вся строка может искаться. Если это больше чем длина этой строки, это имеет тот же самый эффект, как будто это было равно длине этой строки: -1 возвращается.
Все индексы определяются в char значения (элементы кода Unicode).
ch - символ (кодовая точка Unicode).fromIndex - индекс, чтобы запустить поиск с.fromIndex, или -1 если символ не происходит.public int lastIndexOf(int ch)
ch в диапазоне от 0 до 0xFFFF (включительно), возвратился индекс (в элементах кода Unicode), самое большое значение k так, что: истина. Для других значенийthis.charAt(k) == ch
ch, это - самое большое значение k так, что: истина. В любом случае, если никакой такой символ не происходит в этой строке, тоthis.codePointAt(k) == ch
-1 возвращается. String ищется, назад запускаясь в последнем знаке.ch - символ (кодовая точка Unicode).-1 если символ не происходит.public int lastIndexOf(int ch,
int fromIndex)
ch в диапазоне от 0 до 0xFFFF (включительно), возвращенный индекс является самым большим значением k так, что: истина. Для других значений(this.charAt(k) == ch) && (k <= fromIndex)
ch, это - самое большое значение k так, что: истина. Или в случае, если никакой такой символ не происходит в этой строке в или перед позицией(this.codePointAt(k) == ch) && (k <= fromIndex)
fromIndex, тогда -1 возвращается. Все индексы определяются в char значения (элементы кода Unicode).
ch - символ (кодовая точка Unicode).fromIndex - индекс, чтобы запустить поиск с. Нет никакого ограничения на значение fromIndex. Если это больше чем или равно длине этой строки, это имеет тот же самый эффект, как будто это было равно меньше чем длина этой строки: эта вся строка может искаться. Если это отрицательно, это имеет тот же самый эффект, как будто это было-1:-1 возвращается.fromIndex, или -1 если символ не происходит перед той точкой.public int indexOf(String str)
Возвращенный индекс является самым маленьким значением k для который:
Если никакое такое значение k не существует, тоthis.startsWith(str, k)
-1 возвращается.str - подстрока, чтобы искать.-1 если нет такого возникновения.public int indexOf(String str, int fromIndex)
Возвращенный индекс является самым маленьким значением k для который:
Если никакое такое значение k не существует, тоk >= fromIndex && this.startsWith(str, k)
-1 возвращается.str - подстрока, чтобы искать.fromIndex - индекс, с которого можно запустить поиск.-1 если нет такого возникновения.public int lastIndexOf(String str)
this.length(). Возвращенный индекс является самым большим значением k для который:
Если никакое такое значение k не существует, тоthis.startsWith(str, k)
-1 возвращается.str - подстрока, чтобы искать.-1 если нет такого возникновения.public int lastIndexOf(String str, int fromIndex)
Возвращенный индекс является самым большим значением k для который:
Если никакое такое значение k не существует, тоk <= fromIndex && this.startsWith(str, k)
-1 возвращается.str - подстрока, чтобы искать.fromIndex - индекс, чтобы запустить поиск с.-1 если нет такого возникновения.public String substring(int beginIndex)
Примеры:
"unhappy".substring(2) returns "happy" "Harbison".substring(3) returns "bison" "emptiness".substring(9) returns "" (an empty string)
beginIndex - начинающийся индекс, включительно.IndexOutOfBoundsException - если beginIndex отрицательно или больше чем длина этого String объект.public String substring(int beginIndex, int endIndex)
beginIndex и расширяется на символ по индексу endIndex - 1. Таким образом длина подстроки endIndex-beginIndex. Примеры:
"hamburger".substring(4, 8) returns "urge" "smiles".substring(1, 5) returns "mile"
beginIndex - начинающийся индекс, включительно.endIndex - конечный индекс, монопольный.IndexOutOfBoundsException - если beginIndex отрицательно, или endIndex больше чем длина этого String объект, или beginIndex больше чем endIndex.public CharSequence subSequence(int beginIndex, int endIndex)
Вызов этого метода формы
ведет себя точно таким же образом как вызовstr.subSequence(begin, end)
Этот метод определяется так, чтобы класс String мог реализоватьstr.substring(begin, end)
CharSequence интерфейс. subSequence в интерфейсе CharSequencebeginIndex - начать индекс, включительно.endIndex - индекс конца, монопольный.IndexOutOfBoundsException - если beginIndex или endIndex отрицательны, если endIndex больше чем length(), или если beginIndex больше чем startIndexpublic String concat(String str)
Если длина строки параметра 0, тогда это String объект возвращается. Иначе, новое String объект создается, представляя символьную последовательность, которая является связью символьной последовательности, представленной этим String возразите и символьная последовательность, представленная строкой параметра.
Примеры:
"cares".concat("s") returns "caress"
"to".concat("get").concat("her") returns "together"
str - String это связывается до конца этого String.public String replace(char oldChar, char newChar)
oldChar в этой строке с newChar. Если символ oldChar не происходит в символьной последовательности, представленной этим String объект, затем ссылка на это String объект возвращается. Иначе, новое String объект создается, который представляет символьную последовательность, идентичную символьной последовательности, представленной этим String объект, за исключением того, что каждое возникновение oldChar заменяется возникновением newChar.
Примеры:
"mesquite in your cellar".replace('e', 'o')
returns "mosquito in your collar"
"the war of baronets".replace('r', 'y')
returns "the way of bayonets"
"sparring with a purple porpoise".replace('p', 't')
returns "starring with a turtle tortoise"
"JonL".replace('q', 'x') returns "JonL" (no change)
oldChar - старый символ.newChar - новый символ.oldChar с newChar.public boolean matches(String regex)
Вызов этого метода формы str.matches(regex) приводит точно к тому же самому результату как выражение
Pattern.matches( regex, str)
regex - регулярное выражение, к которому должна быть соответствующей эта строкаPatternSyntaxException - если синтаксис регулярного выражения недопустимPatternpublic boolean contains(CharSequence s)
s - последовательность, чтобы искатьs, ложь иначеNullPointerException - если s nullpublic String replaceFirst(String regex, String replacement)
Вызов этого метода формы str.replaceFirst(regex, repl) приводит точно к тому же самому результату как выражение
Pattern.compile( regex).matcher( str).replaceFirst( repl)
Отметьте, что наклонные черты влево (\) и знаки доллара ($) в заменяющей строке могут вызвать результаты отличаться, чем если бы это обрабатывалось как литеральная заменяющая строка; см. Matcher.replaceFirst(java.lang.String). Использовать Matcher.quoteReplacement(java.lang.String) подавить особое значение этих символов, при желании.
regex - регулярное выражение, к которому должна быть соответствующей эта строкаreplacement - строка, которая будет заменена первое соответствиеPatternSyntaxException - если синтаксис регулярного выражения недопустимPatternpublic String replaceAll(String regex, String replacement)
Вызов этого метода формы str.replaceAll(regex, repl) приводит точно к тому же самому результату как выражение
Pattern.compile( regex).matcher( str).replaceAll( repl)
Отметьте, что наклонные черты влево (\) и знаки доллара ($) в заменяющей строке могут вызвать результаты отличаться, чем если бы это обрабатывалось как литеральная заменяющая строка; см. Matcher.replaceAll. Использовать Matcher.quoteReplacement(java.lang.String) подавить особое значение этих символов, при желании.
regex - регулярное выражение, к которому должна быть соответствующей эта строкаreplacement - строка, которая будет заменена каждое соответствиеPatternSyntaxException - если синтаксис регулярного выражения недопустимPatternpublic String replace(CharSequence target, CharSequence replacement)
target - Последовательность значений случайной работы, которые будут замененыreplacement - Заменяющая последовательность значений случайной работыNullPointerException - если target или replacement null.public String[] split(String regex, int limit)
Массив, возвращенный этим методом, содержит каждую подстроку этой строки, которая завершается другой подстрокой, которая соответствует данное выражение или завершается к концу строки. Подстроки в массиве находятся в порядке, в котором они происходят в этой строке. Если выражение не соответствует части ввода тогда, у получающегося массива есть только один элемент, а именно, эта строка.
Параметр limit управляет числом раз, образец применяется и поэтому влияет на длину получающегося массива. Если предел n будет больше чем нуль тогда, то образец будет применен в большинстве n - 1 раз, длина массива будет не больше чем n, и последняя запись массива будет содержать весь ввод вне последнего соответствующего разделителя. Если n неположителен тогда, что образец будет применен настолько много раз насколько возможно, и у массива может быть любая длина. Если n будет нулем тогда, то образец будет применен настолько много раз насколько возможно, у массива может быть любая длина, и запаздывающие пустые строки будут отброшены.
Строка "boo:and:foo", например, приводит к следующим результатам с этими параметрами:
Regex Предел Результат : 2 { "boo", "and:foo" } : 5 { "boo", "and", "foo" } : -2 { "boo", "and", "foo" } o 5 { "b", "", ":and:f", "", "" } o -2 { "b", "", ":and:f", "", "" } o 0 { "b", "", ":and:f" }
Вызов этого метода формы str. split( regex, n) приводит к тому же самому результату как выражение
Pattern.compile( regex).split( str, n)
regex - регулярное выражение разграничиванияlimit - порог результата, как описано вышеPatternSyntaxException - если синтаксис регулярного выражения недопустимPatternpublic String[] split(String regex)
Этот метод работает как будто, вызывая с двумя параметрами split метод с данным выражением и предельным параметром нуля. Запаздывающие пустые строки поэтому не включаются в получающийся массив.
Строка "boo:and:foo", например, приводит к следующим результатам с этими выражениями:
Regex Результат : { "boo", "and", "foo" } o { "b", "", ":and:f" }
regex - регулярное выражение разграничиванияPatternSyntaxException - если синтаксис регулярного выражения недопустимPatternpublic String toLowerCase(Locale locale)
String к нижнему регистру, используя правила данного Locale. Отображение случая основано на версии Стандарта Unicode, определенной Character класс. Так как отображения случая не всегда 1:1 отображения случайной работы, получающееся String может быть различная длина чем оригинал String. Примеры строчных отображений находятся в следующей таблице:
| Код языка Локали | Верхний регистр | Нижний регистр | Описание |
|---|---|---|---|
| концерн (турецкий язык) | \u0130 | \u0069 | прописная буква I с точкой выше-> строчная буква i |
| концерн (турецкий язык) | \u0049 | \u0131 | прописная буква I-> строчная буква dotless i |
| (все) | Картофель-фри | картофель-фри | печатаемый строчными литерами все случайные работы в Строке |
| (все) | 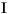 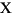
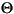 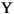
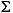 |
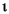 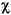
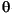 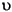
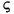 |
печатаемый строчными литерами все случайные работы в Строке |
locale - используйте правила преобразования случая для этой локалиString, преобразованный в нижний регистр.toLowerCase(), toUpperCase(), toUpperCase(Locale)public String toLowerCase()
String к нижнему регистру, используя правила локали по умолчанию. Это эквивалентно вызову toLowerCase(Locale.getDefault()).
Отметьте: Этот метод является чувствительной локалью, и может привести к неожиданным результатам если использующийся для строк, которые предназначаются, чтобы быть интерпретируемой локалью независимо. Примерами являются идентификаторы языка программирования, ключи протокола, и HTML-тэги. Например, "TITLE".toLowerCase() в турецкой локали возвращается "t\u0131tle", где '\u0131' является ЛАТИНСКОЙ СТРОЧНОЙ БУКВОЙ DOTLESS I символов. Чтобы получить корректные результаты для локали нечувствительные строки, использовать toLowerCase(Locale.ENGLISH).
String, преобразованный в нижний регистр.toLowerCase(Locale)public String toUpperCase(Locale locale)
String к верхнему регистру, используя правила данного Locale. Отображение случая основано на версии Стандарта Unicode, определенной Character класс. Так как отображения случая не всегда 1:1 отображения случайной работы, получающееся String может быть различная длина чем оригинал String. Примеры чувствительных к локали и 1:M отображения случая находятся в следующей таблице.
| Код языка Локали | Нижний регистр | Верхний регистр | Описание |
|---|---|---|---|
| концерн (турецкий язык) | \u0069 | \u0130 | строчная буква i-> прописная буква I с точкой выше |
| концерн (турецкий язык) | \u0131 | \u0049 | строчная буква dotless i-> прописная буква I |
| (все) | \u00df | \u0053 \u0053 | строчная буква резкий s-> две буквы: SS |
| (все) | Fahrvergnügen | FAHRVERGNÜGEN |
locale - используйте правила преобразования случая для этой локалиString, преобразованный в верхний регистр.toUpperCase(), toLowerCase(), toLowerCase(Locale)public String toUpperCase()
String к верхнему регистру, используя правила локали по умолчанию. Этот метод эквивалентен toUpperCase(Locale.getDefault()).
Отметьте: Этот метод является чувствительной локалью, и может привести к неожиданным результатам если использующийся для строк, которые предназначаются, чтобы быть интерпретируемой локалью независимо. Примерами являются идентификаторы языка программирования, ключи протокола, и HTML-тэги. Например, "title".toUpperCase() в турецкой локали возвращается "T\u0130TLE", где '\u0130' является ЛАТИНСКОЙ ПРОПИСНОЙ БУКВОЙ I С ТОЧКОЙ ВЫШЕ символа. Чтобы получить корректные результаты для локали нечувствительные строки, использовать toUpperCase(Locale.ENGLISH).
String, преобразованный в верхний регистр.toUpperCase(Locale)public String trim()
Если это String объект представляет пустую символьную последовательность, или первые и последние символы символьной последовательности, представленной этим String возразите, что у обоих есть коды, больше чем '\u0020' (пробел), затем ссылка на это String объект возвращается.
Иначе, если нет никакого символа с кодом, больше чем '\u0020' в строке, затем новое String объект, представляющий пустую строку, создается и возвращается.
Иначе, позвольте k быть индексом первого символа в строке, код которой больше чем '\u0020', и позвольте м. быть индексом последнего знака в строке, код которой больше чем '\u0020'. Новое String объект создается, представляя подстроку этой строки, которая начинается с символа по индексу k и заканчивает символом по индексу м. то есть, результат this.substring(k, m+1).
Этот метод может использоваться, чтобы обрезать пробел (как определено выше) с начала и конца строки.
public String toString()
toString в интерфейсе CharSequencetoString в классе Objectpublic char[] toCharArray()
public static String format(String format, Object... args)
Локаль, всегда используемая, является той, возвращенной Locale.getDefault().
format - Строка форматаargs - На параметры ссылаются спецификаторы формата в строке формата. Если есть больше параметров чем спецификаторы формата, дополнительные параметры игнорируются. Число параметров является переменным и может быть нулем. Максимальное количество параметров ограничивается максимальной размерностью массива Java как определено Спецификацией Виртуальной машины Java™. Поведение на параметре null зависит от преобразования.IllegalFormatException - Если строка формата содержит недопустимый синтаксис, спецификатор формата, который является несовместимым с данными параметрами, недостаточные параметры, данные строку формата, или другие недопустимые условия. Для спецификации всех возможных ошибок форматирования см. раздел Деталей спецификации класса средства форматирования.NullPointerException - Если format является nullFormatterpublic static String format(Locale l, String format, Object... args)
l - Локаль, чтобы применяться во время форматирования. Если l является null тогда, никакая локализация не применяется.format - Строка форматаargs - На параметры ссылаются спецификаторы формата в строке формата. Если есть больше параметров чем спецификаторы формата, дополнительные параметры игнорируются. Число параметров является переменным и может быть нулем. Максимальное количество параметров ограничивается максимальной размерностью массива Java как определено Спецификацией Виртуальной машины Java™. Поведение на параметре null зависит от преобразования.IllegalFormatException - Если строка формата содержит недопустимый синтаксис, спецификатор формата, который является несовместимым с данными параметрами, недостаточные параметры, данные строку формата, или другие недопустимые условия. Для спецификации всех возможных ошибок форматирования см. раздел Деталей спецификации класса средства форматированияNullPointerException - Если format является nullFormatterpublic static String valueOf(Object obj)
Object параметр.obj - Object.null, тогда строка, равная "null"; иначе, значение obj.toString() возвращается.Object.toString()public static String valueOf(char[] data)
char параметр массива. Содержание символьного массива копируется; последующая модификация символьного массива не влияет на недавно создаваемую строку.data - a char массив.public static String valueOf(char[] data, int offset, int count)
char параметр массива. offset параметром является индекс первого символа подмассива. count параметр определяет длину подмассива. Содержание подмассива копируется; последующая модификация символьного массива не влияет на недавно создаваемую строку.
data - символьный массив.offset - начальное смещение в значение String.count - длина значения String.IndexOutOfBoundsException - если offset отрицательно, или count отрицательно, или offset+count больше чем data.length.public static String copyValueOf(char[] data, int offset, int count)
data - символьный массив.offset - начальное смещение подмассива.count - длина подмассива.String это содержит символы указанного подмассива символьного массива.public static String copyValueOf(char[] data)
data - символьный массив.String это содержит символы символьного массива.public static String valueOf(boolean b)
boolean параметр.b - a boolean.true, строка, равная "true" возвращается; иначе, строка, равная "false" возвращается.public static String valueOf(char c)
char параметр.c - a char.1 содержа как его единственный символ параметр c.public static String valueOf(int i)
int параметр. Представление является точно тем, возвращенным Integer.toString метод одного параметра.
i - int.int параметр.Integer.toString(int, int)public static String valueOf(long l)
long параметр. Представление является точно тем, возвращенным Long.toString метод одного параметра.
l - a long.long параметр.Long.toString(long)public static String valueOf(float f)
float параметр. Представление является точно тем, возвращенным Float.toString метод одного параметра.
f - a float.float параметр.Float.toString(float)public static String valueOf(double d)
double параметр. Представление является точно тем, возвращенным Double.toString метод одного параметра.
d - a double.double параметр.Double.toString(double)public String intern()
Пул строк, первоначально пустых, сохраняется конфиденциально классом String.
Когда метод интерна вызывается, если пул уже содержит строку, равную этому String возразите как определено equals(Object) метод, тогда строка от пула возвращается. Иначе, это String объект добавляется к пулу и ссылке на это String объект возвращается.
Из этого следует, что для любых двух строк s и t, s.intern() == t.intern() true если и только если s.equals(t) true.
Все литеральные строки и оцененные строке константные выражения интернируются. Строковые литералы определяются в разделе 3.10.5 из Спецификация языка Java™.
Для дальнейшей ссылки API и документации разработчика, см. . Та документация содержит более подробные, предназначенные разработчиком описания, с концептуальными краткими обзорами, определениями сроков, обходных решений, и рабочих примеров кода.
Авторское право © 1993, 2011, Oracle и/или его филиалы. Все права защищены.