Spec-Zone .ru
спецификации, руководства, описания, API
|
|
Spec-Zone .ru
спецификации, руководства, описания, API
|
Вы должны определить местоположение символьных границ, если Ваше приложение позволяет конечному пользователю выделять отдельные символы или перемещать курсор через текст один символ за один раз. Создать a BreakIterator это определяет местоположение символьных границ, Вы вызываете getCharacterInstance метод, следующим образом:
BreakIterator characterIterator =
BreakIterator.getCharacterInstance(currentLocale);
Этот тип BreakIterator обнаруживает границы между пользовательскими символами, не только символами Unicode.
Пользовательский символ может быть составлен больше чем из одного символа Unicode. Например, пользовательский символ ü может быть составлен, комбинируя символы Unicode \u0075 (u) и \u00a8 (¨). Это не лучший пример, однако, потому что символ ü может также быть представлен единственным символом Unicode \u00fc. Мы привлечем арабский язык для более реалистического примера.
На арабском языке слово для дома:
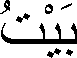
Это слово содержит три пользовательских символа, но оно составляется из следующих шести символов Unicode:
String house = "\u0628" + "\u064e" + "\u064a" + "\u0652" + "\u067a" + "\u064f";
Символы Unicode в позициях 1, 3, и 5 в house строка является диакритическими знаками. Арабский язык требует диакритических знаков, потому что они могут изменить значения слов. Диакритические знаки в примере являются символами без интервалов, так как они появляются выше базовых символов. В арабском текстовом процессоре невозможно переместить курсор в экран однажды для каждого символа Unicode в строке. Вместо этого следует переместить это однажды для каждого пользовательского символа, который может быть составлен больше чем одним символом Unicode. Поэтому следует использовать a BreakIterator отсканировать пользовательские символы в строке.
Пример программы BreakIteratorDemo, создает a BreakIterator отсканировать арабские символы. Программа передает это BreakIterator, наряду с String объект, создаваемый ранее, к методу, называют listPositions:
BreakIterator arCharIterator = BreakIterator.getCharacterInstance(
new Locale ("ar","SA"));
listPositions (house, arCharIterator);
listPositions метод использует a BreakIterator определять местоположение символьных границ в строке. Отметьте что BreakIteratorDemo присваивает определенную строку BreakIterator с setText метод. Программа получает первую символьную границу с first метод и затем вызывает next метод до константы BreakIterator.DONE возвращается. Код для этой подпрограммы следующие:
static void listPositions(String target, BreakIterator iterator) {
iterator.setText(target);
int boundary = iterator.first();
while (boundary != BreakIterator.DONE) {
System.out.println (boundary);
boundary = iterator.next();
}
}
listPositions метод распечатывает следующие граничные позиции для пользовательских символов в строке house. Отметьте, что позиции диакритических знаков (1, 3, 5) не перечисляются:
0 2 4 6
|
