Spec-Zone .ru
спецификации, руководства, описания, API
|
|
Spec-Zone .ru
спецификации, руководства, описания, API
|
MySQL Cluster поддерживает асинхронную репликацию, чаще упомянутую просто как "репликация". Этот раздел объясняет, как установить и управлять конфигурацией, в которой одна группа компьютеров, работающих, поскольку, MySQL Cluster тиражируется к второму компьютеру или группе компьютеров. Мы принимаем некоторое знакомство со стороны читателя со стандартной репликацией MySQL как обсуждено в другом месте в этом Руководстве. (См. Главу 16, Репликацию).
Нормальная (некластеризируемая) репликация включает "основной" сервер и "ведомый"
сервер, ведущее устройство, являющееся источником операций и данных, которые будут тиражированы и ведомое
устройство, являющееся получателем их. В MySQL Cluster репликация концептуально очень подобна, но может быть
более сложной практически, поскольку это может быть расширено, чтобы покрыть много различных конфигураций
включая тиражирование между двумя полными кластерами. Хотя сам MySQL Cluster зависит от NDB механизм хранения для того, чтобы кластеризировать функциональность, не
необходимо использовать NDB как
механизм хранения для копий ведомого устройства тиражированных таблиц (см. Репликацию
от NDB к не -NDB таблицы). Однако, для
максимальной доступности, это возможно (и предпочтительно) тиражироваться от одного MySQL Cluster до другого, и
именно этого сценария, мы обсуждаем, как показано в следующем числе:
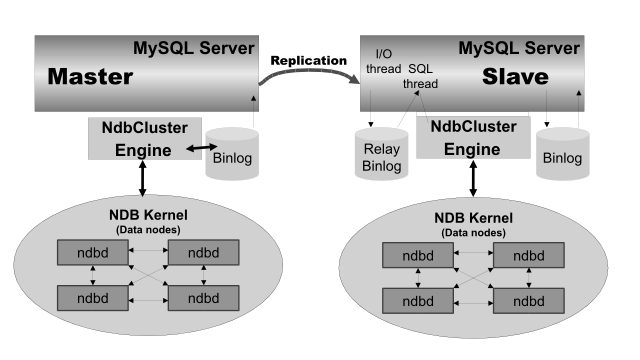
В этом сценарии процесс репликации - тот, в котором последовательные состояния основного кластера регистрируются
и сохраняются к ведомому кластеру. Этот процесс выполняется специальным потоком, известным как NDB binlog поток
инжектора, который работает на каждом сервере MySQL и производит двоичный журнал (binlog). Этот поток гарантирует, что все изменения в кластере, производящем
двоичный журнал — и не только те изменения, которые вызываются через MySQL Server — вставляются в двоичный
журнал с корректным порядком сериализации. Мы обращаемся к ведущему устройству репликации MySQL и ведомым
серверам репликации как сервера репликации или узлы репликации, и поток данных или линия связи между ними как
канал репликации.
Для получения информации о выполнении восстановления момента времени с MySQL Cluster и MySQL Cluster Replication, см. Раздел 17.6.9.2, "Восстановление Момента времени Используя MySQL Cluster Replication".
API NDB _slave переменные состояния. Счетчики API NDB могут обеспечить
улучшенные контролирующие возможности на ведомых устройствах репликации MySQL Cluster. Они реализуются как
статистика NDB _slave переменные состояния, как замечено в выводе SHOW STATUS, или в результатах запросов против SESSION_STATUS или GLOBAL_STATUS таблица в mysql клиентском сеансе, соединенном с MySQL Server, который
действует как ведомое устройство в MySQL Cluster Replication. Сравнивая значения этих переменных состояния
прежде и после того, как выполнение влияния операторов тиражировалось NDB таблицы, можно наблюдать соответствующие действия, взятые уровень API NDB
ведомым устройством, которое может быть полезным, контролируя или диагностируя MySQL Cluster Replication. Раздел 17.5.15, "Счетчики Статистики API
NDB и Переменные", обеспечивает дополнительная информация.
Репликация от NDB к не -NDB таблицы. Возможно тиражироваться NDB таблицы от MySQL Cluster, действующего как ведущее устройство к таблицам,
используя другие механизмы хранения MySQL такой как InnoDB или MyISAM
на ведомом устройстве mysqld. Однако, из-за различий между версией mysqld, предоставленного MySQL Cluster и включенным с MySQL
Server 5.6, ведомый сервер должен также использовать mysqld двоичный файл от распределения MySQL Cluster. См. Раздел 17.6.2, "Общие Требования
для MySQL Cluster Replication".